谷歌 AI 新方法:可提升 10 倍图像识别效率,关键还简单易用
Posted DeepTech深科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谷歌 AI 新方法:可提升 10 倍图像识别效率,关键还简单易用相关的知识,希望对你有一定的参考价值。
在开发以卷积神经网络(CNN)为核心的机器学习模型时,我们通常会先使用固定的资源成本,构建最初的模型,然后增加更多资源(层数)扩展模型,从而获得更高的准确率。
著名的 CNN 模型 ResNet(深度残差网络),就可以用增加层数的方法从ResNet-18 扩展到 ResNet-200。谷歌的 GPipe 模型也通过将基线 CNN 扩展 4 倍,在 ImageNet 数据库上达到 84.3% 的准确率,力压所有模型。
一般来说,模型的扩大和缩小都是任意增加 CNN 的深度或宽度,抑或是使用分辨率更大的图像进行训练和评估。虽然这些传统方法提高准确率的效果不错,但大多需要繁琐的手动调整,还可能无法达到最佳性能。
因此,谷歌AI团队最近提出了新的模型缩放方法“复合缩放(Compound Scaling)”和配套的 EfficientNet 模型。他们使用复合系数和 AutoML 从多个维度均衡缩放 CNN,综合考虑深度和宽度等参数,而不是只单纯地考虑一个,使得模型的准确率和效率大幅提升,图像识别的效率甚至可以大幅提升 10 倍。
这项新方法的根本优势在于实践起来非常简单,背后的原理很好理解,甚至让人怀疑为什么没有被更早发现。该研究成果以论文的形式被 ICML 2019(国际机器学习大会)接收,名为 EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks。EfficientNet 模型的相关代码和 TPU 训练数据也已经在 GitHub 上开源。
寻找复合系数

为了弄清楚神经网络缩放之后的效果,谷歌团队系统地研究了改变不同维度对模型的影响,维度参数包括网络深度、宽度和图像分辨率。
首先他们进行了栅格搜索(Grid Search)。这是一种穷举搜索方法,可以在固定资源的限定下,列出所有参数之间的关系,显示出改变某一种维度时,基线网络模型会受到什么样的影响。换句话说,如果只改变了宽度、深度或分辨率,模型的表现会发生什么变化。
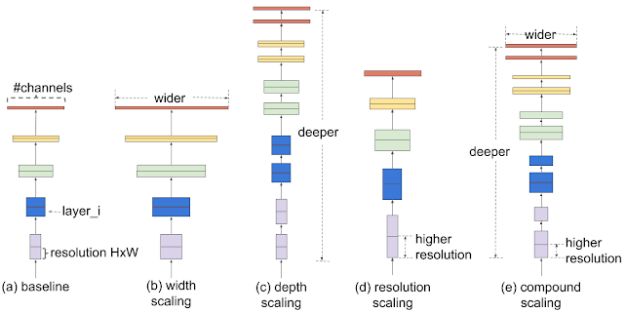
图 | 以基线网络为基础,列出所有维度变化对模型的影响(来源:谷歌 AI)
综合考虑所有情况之后,他们确定了每个维度最合适的调整系数,然后将它们一同应用到基线网络中,对每个维度都进行适当的缩放,并且确保其符合目标模型的大小和计算预算。
简单来说,就是分别找到宽度、深度和分辨率的最佳系数,然后将它们组合起来一起放入原本的网络模型中,对每一个维度都有所调整。从整体的角度缩放模型。
与传统方法相比,这种复合缩放法可以持续提高模型的准确性和效率。在现有模型 MobileNet 和 ResNet 上的测试结果显示,它分别提高了 1.4% 和 0.7% 的准确率。
高效的网络架构和性能
缩放模型的有效性也依赖于基线网络(架构)本身。
因为,为了进一步提高性能,谷歌 AI 团队还使用了 AutoML MNAS 框架进行神经架构搜索,优化准确性和效率。AutoML 是一种可以自动设计神经网络的技术,由谷歌团队在 2017 年提出,而且经过了多次优化更新。使用这种技术可以更简便地创造神经网络。
由此产生的架构使用了移动倒置瓶颈卷积(MBConv),类似于 MobileNetV2 和 MnasNet 模型,但由于计算力(FLOPS)预算增加,MBConv 模型体积略大。随后他们多次缩放了基线网络,组成了一系列模型,统称为 EfficientNets。
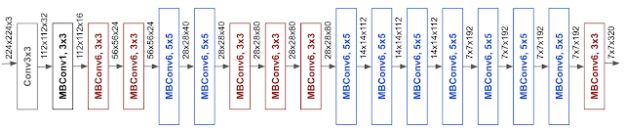
图 | EfficientNet-B0 基线网络架构(来源:谷歌 AI)
为了测试其性能,研究人员与 ImageNet 上的其他现有 CNN 进行了比较。结果显示,EfficientNet 在大多数情况下表现亮眼,比现有 CNN 的准确率和效率都高,还将参数大小和计算力降低了一个数量级。
比如 EfficientNet-B7 在 ImageNet 上达到的 Top-1 最高准确率是 84.4%,Top-5 准确率是 97.1%。在 CPU 推理上,它的体积比最好的 CNN 模型 GPipe 小 8.4 倍,但速度快了 6.1 倍。与广泛使用的 ResNet-50 相比,EfficientNet-B4 使用了类似的计算力,但 Top-1 准确率从 76.3% 提升到了 82.6%。
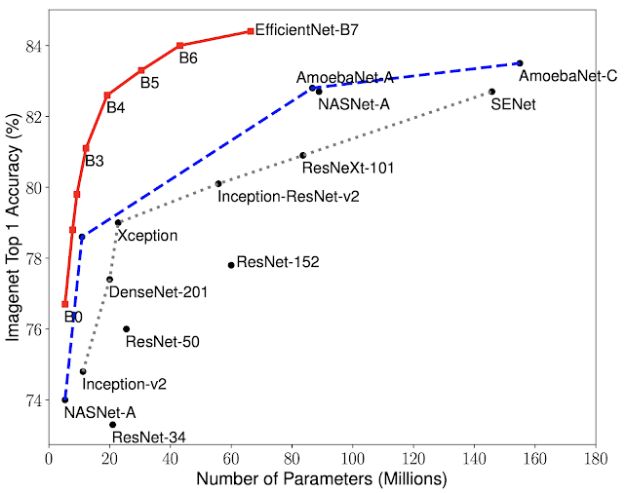
图 | 参数使用量和 ImageNet Top-1 准确率对比(来源:谷歌 AI)
此外,EfficientNets 不仅在 ImageNet 上表现出众,其能力还可以转移到其它数据集上。
他们在 8 个流行的迁移学习数据集上测试了 EfficientNets。结果显示,它在其中的 5 个上面都拿到了顶尖成绩,例如在 CIFAR-100 上获得了 91.7% 的成绩,在 Flowers 上获得了 98.8% 的成绩,而且参数至少减少了一个数量级,甚至还可以最多减少 21 倍,说明 EfficientNets 具有很强的迁移能力。
谷歌 AI 团队认为,EfficientNets 有望凭借简单易操作的特点,成为未来计算机视觉任务的新基石。
-End-
参考:
https://ai.googleblog.com/2019/05/efficientnet-improving-accuracy-and.html
https://arxiv.org/pdf/1905.11946.pdf
坐标:北京·国贸
联系方式:hr@mittrchina.com
请随简历附上3篇往期作品(实习生除外)
点击阅读原文报名参加“万物LINK”↓↓↓
以上是关于谷歌 AI 新方法:可提升 10 倍图像识别效率,关键还简单易用的主要内容,如果未能解决你的问题,请参考以下文章
阿里「杀手锏」级语音识别模型来了!推理效率较传统模型提升10倍,已开源...
全球最大的图像识别数据库ImageNet不行了?谷歌DeepMind新方法提升精度
用深度学习理解遥感图像,识别效率提升90倍 | 百度PaddlePaddle&中科院遥感地球所
GPT-4杀疯了!Copilot X重磅发布!AI写代码效率10倍提升,码农遭降维打击...