全球最大的图像识别数据库ImageNet不行了?谷歌DeepMind新方法提升精度
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全球最大的图像识别数据库ImageNet不行了?谷歌DeepMind新方法提升精度相关的知识,希望对你有一定的参考价值。
编辑:元子
【新智元导读】来自苏黎世谷歌大脑和DeepMind London的研究人员认为,世界上最受欢迎的图像数据库之一ImageNet需要改造。ImageNet是一个无与伦比的计算机视觉数据集,拥有超过1400万张标记图像。它是为对象识别研究而设计的,并按照WordNet的层次结构进行组织。层次结构的每个节点都由成百上千的图像描述,目前每个节点平均有超过500个图像。
将时间倒回15年前,2005年,还是一个被算法统治的年代。
刚刚拿到加州理工电子工程学博士学位,到伊利诺伊州香槟分校担任教职的李飞飞敏锐的发现了「算法为王」的局限性,开始研究算法的基石:数据集。
此后,全世界最大的图像识别数据集「ImageNet」诞生。
ImageNet的出现,伴随着一个非常宏大的野心。完整版ImageNet拥有超过1400多万幅图片,涉及2万多个类别标注,超百万边界标注。
2010年到2017年期间,围绕ImageNet共举办了8届 Large Scale Visual Recognition Challenge,包括图像分类,目标检测,目标定位单元。
2017年,挑战赛完结。
八年来,参赛选手将算法正确识别率从71.8%提升到97.3%,这样的精度甚至已经将我们人类自己都远远的甩在后面。
同时,也证明了数据集越大、效果越好。
近十年来,ImageNet一直是人工感知研究的核心测试平台,它的规模和难度凸显了机器学习领域的里程碑式成就。
但Google和DeepMind的科学家却认为,已有的ImageNet有些落伍了。他们发现,原始的ImageNet标签不再是新标注的最佳预测者,已经被最近的高绩效模型系统性地超越了。
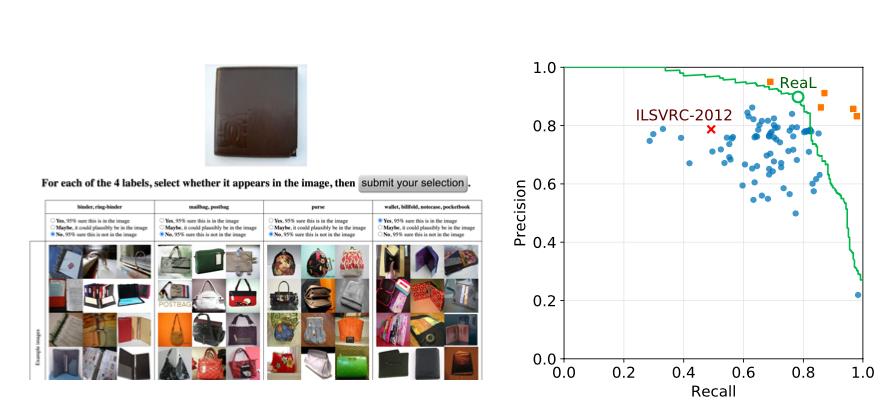
现实世界中的图像通常包含很多标签,但是ImageNet对每幅图像只分配了一个标签,这就导致图像内容的严重表达不足。比如下图第一行,每幅图只标记了一个物体,图中很多物体都被遗漏了。
ImageNet注释流程是在互联网上查询制定类的图像,然后询问人工评审员该类是否确实存在于当前图像中。
虽然这个过程会产生合理的图像描述,但也会导致不准确的情况。当单独考虑时,一个特定的标签建议,看起来可能是对图像的合理描述;然而当与其他ImageNet类一起考虑时,这种描述马上就显得不那么合适了。
比如上图中间一行第二个更准确的标注应该是「水瓶」,然而从单张图片来看,你说它是水桶也说得过去。最后一个其实是「校车」,但校车上的人,不论是学生还是老师,也都是passenger呀。
例如最下一行中间,laptop的分类虽然是没错,但却忽略了notebook、Computor也同样可以指代同一个对象。如果我们能够将这些标签都用上,显然可以更精准的描述一个物体。
考虑到孤立地分配一个标签所产生的偏差,Google和DeepMind的研究团队设计了一个标签程序,它能捕获ImageNet数据集中内容的多样性和多重性。
并寻求一种范式,允许人类注释者同时评估一组不同的候选标签,又能保持proposal的数量足够小,以实现稳健的注释。
在模型子集上进行穷尽式搜索,以找到一组能达到最高精度,同时保持97%以上的召回率的模型子集。
在此基础上,科学家找到了一个6个模型的子集,它生成的标签proposal具有97.1%的召回率和28.3%的精度,将每个图像的平均proposal标签数从13个降低到7.4个。从这个子集中,使用上述相同的规则,为整个验证集生成proposal标签。
在获得了整个验证集的新的候选标签集后,首先评估哪些图像需要由人工进行评估。
在所有模型都与原始ImageNet标签一致的情况下,就可以安全地保留原始标签而不需要人工重新评估,这样就将需要标注的图像数量就从50000张减少到24889张。
进一步根据WordNet的层次结构,将超过8个标签建议的图像分成多个标签任务。这就导致了37988个标签任务。
使用众包平台,将每个任务分配给5个独立的真人工标注者执行。
下图是在ImageNet上,由Google和DeepMind科学家提出的sigmoid loss和clean label set的Top-1精度(百分比)。
可以看出,无论是sigmoid loss还是clean label set都比Benchmark优秀,而同时使用这两种方法获得了最好的性能。
新方法在较长的训练计划下,其改进更为明显。
但是在存在噪声数据的情况下,较长的训练计划可能是有害的,科学加期望清洗 ImageNet 训练集(或使用 sigmoid 损失)能在这种情况下产生额外的好处。
在后续的实验中,科学家发现ReaL标签可以更正超过一半的ImageNet标签错误,这意味着ReaL标签提供了对模型准确性的更优越估计。
https://arxiv.org/pdf/2006.07159.pdf
以上是关于全球最大的图像识别数据库ImageNet不行了?谷歌DeepMind新方法提升精度的主要内容,如果未能解决你的问题,请参考以下文章
让图像识别准确率瞬间下降40个点,「江苏卷」版ImageNet你考得过吗?
厉害了,图像识别已攻克,谷歌将发力视频识别和搜索
图像识别已攻克 谷歌将发力视频识别和搜索
图像识别 ImageNet 比赛 历届冠军评析:看看哪个深度学习模型最适合你?
百度图像识别技术享誉国际,斩获最大规模图像识别竞赛WebVision桂冠
何恺明等在图像识别任务上取得重大进展,这次用的是弱监督学习