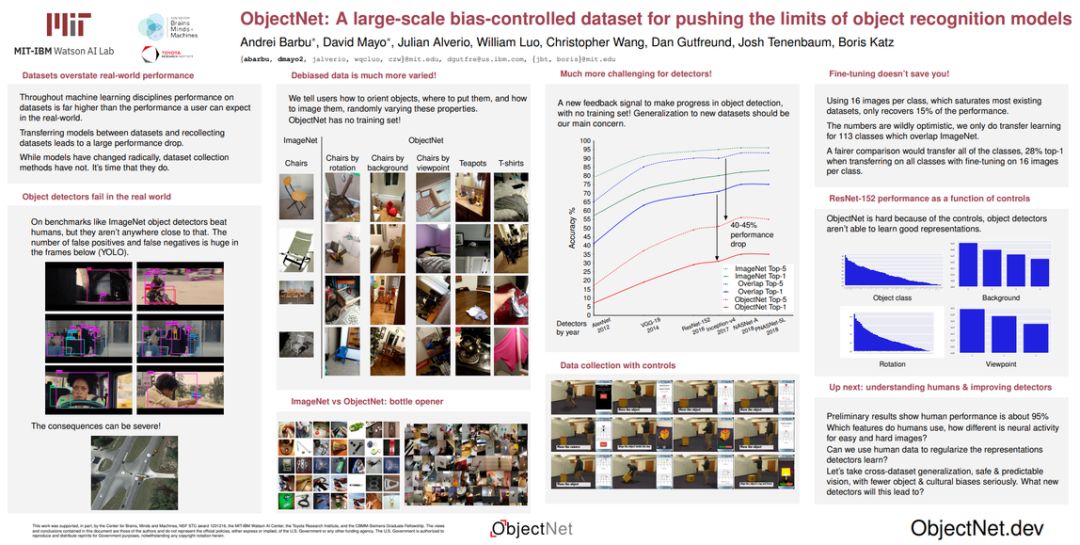
让图像识别准确率瞬间下降40个点,「江苏卷」版ImageNet你考得过吗?
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了让图像识别准确率瞬间下降40个点,「江苏卷」版ImageNet你考得过吗?相关的知识,希望对你有一定的参考价值。
近日,MIT 联合 IBM 研究团队提出了一个数据集,在它上面测试的图像识别 SOTA 模型的性能下降了 40 多个点。
图像识别是计算机视觉中最为成熟的领域了。从 ImageNet 开始,历年都会出现各种各样的新模型,如 AlexNet、YOLO 家族、到后面的 EfficientNet 等。这些模型都在刷新着各种图像识别领域的榜单,创造更令人惊讶的表现。
而近日,MIT 和 IBM 的研究者发现,在他们建立的一个名为 ObjectNet 的数据集上,即使是现在的 SOTA 模型都会「吃瘪」。
这一新的数据集能够让模型的性能下降了 40 多个点。
最终,研究者们公开了这个数据集,并鼓励人们开发更好的模型来解决问题。
这一数据集相关的论文已经被 NeurlPS 2019 大会接收为 Poster 论文,读者们可以参考这个有趣的研究,看看自己的图像识别模型性能如何。
论文地址:
https://objectnet.dev/objectnet-a-large-scale-bias-controlled-dataset-for-pushing-the-limits-of-object-recognition-models.pdf
项目地址:
https://objectnet.dev/
MIT 和 IBM 开发的这个 ObjectNet 数据集包含 50,000 张图像,与 ImageNet 的测试集图像数量相当。它包含 313 种物体类别,其中的 113 个类别与 ImageNet 重合。
从构思到收集完成,MIT 的研究人员足足花了四年时间。为什么做这个数据集那么费劲?研究人员说了,「我们的目的就是告诉人们,目标检测仍然是一个难题。」翻译一下就是:「我们就是要难倒你们的模型!」
要难倒模型,从网上爬取图片肯定是不够的,毕竟大家上传到网上的照片大都是精心挑选的。所以,MIT 的研究人员选择
专门雇人拍摄
。由于拍摄标准比较严格,最后拍到的照片只有一半是合格的。
拍摄标准到底有多严格?
研究者要求拍摄者注意三个问题:物体摆放的方向、拍摄的角度以及是否放在客厅、厨房等与物体高度相关的场景下。比如椅子不能摆的太正,不能拍正面图,盘子不能放在厨房拍。
如此一来,他们得到的照片有着和日常图像不同的角度、状态——即不同的语义信息。
ImageNet 图像(左侧)和 ObjectNet 图像的对比。
可以看出 ObjectNet 图像中的目标有各种奇怪的语义。
为了增加难度,他们还选择去美国之外的地方拍摄,因为 Facebook 的一项研究表明,在识别家用物品方面,模型在欧洲和北美的识别准确度要高于在亚、非的识别准确率。
研究人员绞尽脑汁想出的这些拍摄方式无非是为了充分还原现实世界的复杂性,从而告诉大家,「你们的算法还有很大的进步空间。」
除了拍摄,ObjectNet 与其他数据集还有一个很大的不同,即没有训练集,只有测试集。
普通数据集会将所有图像分为测试集和训练集,但二者之间或多或少会存在一些相似性,所以模型相当于提前看过测试集的一些内容,判断起来当然更加方便。在去掉训练集之后,ObjectNet 明显能够很好地评估图像识别模型的泛化能力。
研究者测试了各种主流模型在 ObjectNet 数据集上的效果,从 2012 年的 AlexNet 到 18 年的 PNASNet-5L 都有尝试。
所有模型都在 ImageNet 上完成预训练,并在 ObjectNet 与 ImageNet 交叉的 113 个类别上进行测试。
正如我们前面所看到的,这种测试能让顶级模型的性能下降 40-45%,不论是 Top-1 还是 Top-5 准确率。
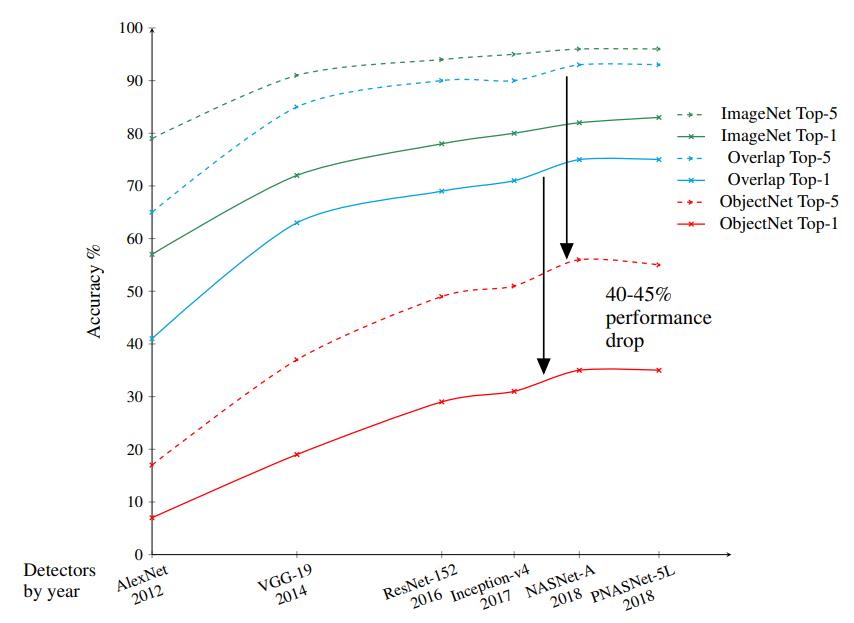
图 1:在 ImageNet 上训练,并在 ImageNet 测试集或 ObjectNet 做验证的结果,很明显,不同的网络的性能都会大幅降低。
很明显,当我们更换测试集后,尽管类别一致,但性能也会有一定的降低。只不过 SOTA 模型降低一半的准确率,这足以说明深度模型在同类目标的识别上,泛化能力并不强。
此外,值得注意的是,通过改进模型,识别准确率确实能上升,但 ImageNet 与 ObjectNet 之间的差距并不会减小。
读者可能对巨大的性能差异感到困惑,研究者将背景、旋转和视角作为控制变量,并根据它们分解性能。如果说不同类之间的概率非常均衡,那么就表明它与检测器无关,检测器对于这个特征是鲁棒的。相反,对于某些特征概率差别很大,那么就表明它们与预测结果很相关。
如下所示为不同类别的性能影响,我们可以看到,目标类别与旋转都对最终的预测有非常大的影响。而背景这样的特征,它对最终预测产生的影响并不非常显著。
图 6:ResNet-152 在 ImageNet 上做预训练,并在 ObjectNet – 113 做测试的结果。
熟悉机器学习的读者知道,如果测试集和训练集的数据分布有很大不同,则一般的模型不太可能在测试集上取得较好的结果。那么这篇论文做的实验也是这样的结果吗?
实验过程中,研究者是在 ImageNet 上进行的训练,而测试则放在了 ObjectNet 上。尽管图像类别是一致的,但这些 SOTA 模型就被愚弄了。研究者表示,为了弄清楚原因,他们才做了图 6 的控制变量实验,实验结果表明,ObjectNet 极低的准确率很大程度上取决于这些变量,而不是数据本身。
为了证明这一点,研究者测试了微调模型。具体而言,研究者使用在 ImageNet 上预训练的 ResNet-152,并在两种条件下微调它的最后两层。如果没有在 ObjectNet 微调,它的 Top-1 准确率为 29%,如果在 8 张图片上微调,它的准确率能提升到 39%,在 16 张图片微调能提升到 45%。
但问题在于,即使用一半的图像来微调,它的 Top-1 准确率也只能达到 50%,这还是在识别类别一致的情况下。所以说,很大一部分性能损失在于,模型对于旋转、背景和视角的稳健性缺失,也许未来的研究可以从这些方面进一步提升识别模型的极致性能。
研究者在论文中表示,人类在这个数据集上的测试精确率高达 95%。他们下一步会继续探究为何人类在图像识别任务上具有良好的泛化能力和鲁棒性,并希望这一数据集能够成为检验图像识别模型泛化能力的评估方法。
NeuralPS 2019 大会仍在继续,机器之心将会继续为读者带来一线报道。
参考链接:
https://venturebeat.com/2019/12/10/mit-and-ibms-objectnet-shows-that-ai-struggles-at-object-detection-in-the-real-world/
12月18日,机器之心线下技术分享会邀请到来自硅谷专注于 AutoML 领域的 MoBagel 行动贝果的两位重磅嘉宾,为大家介绍全流程 AutoML 技术,详细解读自动机器学习如何实现机器学习的全民化。
在演讲分享之后,我们还安排了 AutoML 实战工作坊,通过实际案例的讲解,帮助大家深入了解全流程 AutoML 技术的商业应用,并抢先亲手体验行动贝果 Decanter AI (数醒™) 自动化机器学习平台。
点击阅读原文,立即报名。
以上是关于让图像识别准确率瞬间下降40个点,「江苏卷」版ImageNet你考得过吗?的主要内容,如果未能解决你的问题,请参考以下文章
convnet 突然下降准确率
[论文荐读]重组牛肉图像识别模型的比较研究
AI图像识别遇上对抗性图像竟变“瞎子”
关于模型优化的思考
98%都认错,图像识别AI遇上对抗性图像竟变“瞎子”
计算机科学卷积神经网络在图像识别中的应用