图像识别之美食挑战赛 Ⅱ:由二分类到多分类,增加的不止是一点复杂度......
Posted AI开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像识别之美食挑战赛 Ⅱ:由二分类到多分类,增加的不止是一点复杂度......相关的知识,希望对你有一定的参考价值。


就在几个月前,AI 研习社推出了第一场有关美食识别的挑战赛(详情请戳:)。该比赛要求参赛者能够从给出待识别图片中正确区分豆腐与土豆,这一任务也让众多图片识别爱好者得到了初级练手。
相较第一场美食识别挑战赛,这次推出的比赛 2.0 难度略有增加。除了食材种类的成倍增加之外,四种食材的图片辨识度也有所降低。这对于专注于图像识别的开发者而言,相信是非常值得尝试的一次挑战!

二分类 ---> 多分类
如果你单纯以为这次挑战赛只是将种类增加了 2 类,那可就误会大了。从学术的角度来看,这次的问题实际上是由之前的二分类问题扩展到了多分类问题。
通常在处理二分类问题时,我们只需将所涉及类别分为两类,例如:真(1),假(0),然后再进行两两配对即可。之后根据测试结果与实际情况的对比,我们还会得到一个混淆矩阵,其中包括四类数据:
预测为真且实际为真的 True Positives(TP)
预测为假且实际为真的 False Negatives(FN)
预测为真且实际为假的 False Positives(FP)
预测为假且实际为假 True Negatives(TN)
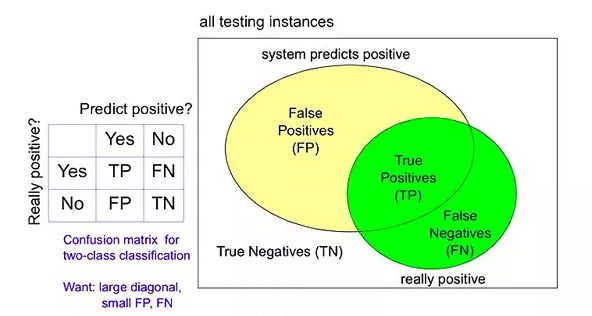
二分类问题
除此之外,也涉及到由此衍生的多个衡量模型质量的相关指标。例如:精确率 (Precision)——模型判断正确的数据 (TP+TN) 占总数据的比例;召回率 (Recall)——模型正确判断出的正例 (TP) 占数据集中所有正例的比例;准确率 (Accuracy)——针对模型判断出的所有正例 (TP+FP) 而言, 其中真正例 (TP) 占的比例。
而如果是多分类问题,例如本次挑战赛所涉及的 4 类,不仅分类将对应增加为茄子(0)、山药(1)、苦瓜(2)、西兰花(3),而且相应的混淆矩阵也将由之前的 2*2 变为 4*4。如果多分类问题扩展到 10 类,那混淆矩阵将会变成 10*10 的矩阵。
多类细胞分类问题示例
类似于线性回归分类,多元线性回归较单元线性回归问题,增加变量个数即单变量推广到多元;运用梯度下降法时,方法同单变量线性回归,代价函数也将有很大的变化。
具体而言,多变量的时候,变量的取值范围将有差异。如果差异过大,产生的代价函数极不规整,像特别狭长的椭圆,这时候进行梯度下降时,路径会十分曲折。
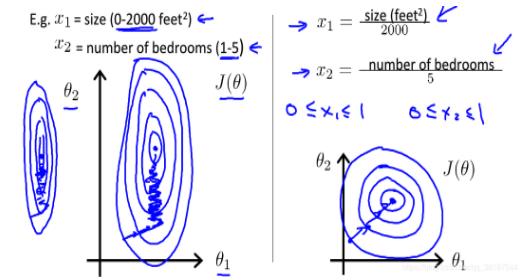
图片来源:https://blog.csdn.net/qq_36187544/article/details/87879423
如此一来,多分类问题不仅有多个参数增加的代价问题;同时,考虑到模型质量问题,也需要有更为复杂的衡量指标来对模型进行判断与优化。因此,多分类问题每多一个类别,识别问题的复杂维度将大大增加。
多分类问题解决思路
当问题从二分类变为多分类时,通常开发者们采用的是拆解法,即:将多分类问题拆分成多个二分类问题,为每一个二分类问题训练一个分类器,再综合多个分类标准下的预测结果进行集成,得到最终分类。这种将问题转换的拆分策略主要为三种:
二元关联 :将每个标签当做单独的一个类分类问题。给定数据集 D 这里有 N 个类别,这种情况下就是将这些类别两两配对,从而产生 N(N-1)/2 个二分类任务,在测试的时候把样本传给这些分类器,然后进行决策。
分类器链 :将每一次的一个类作为正例,其余作为反例,总共训练 N 个分类器。测试的时候若仅有一个分类器预测为正的类别则对应的类别标记作为最终分类结果,若有多个分类器预测为正类,则选择置信度最大的类别作为最终分类结果。
多分类策略 :基于一种纠错输出码的分类方法,分为编码与解码两个步骤。编码负责对 N 个类别做 M 次划分,解码则负责用 M 个分类器分别对测试样本进行预测,得到最终预测结果。
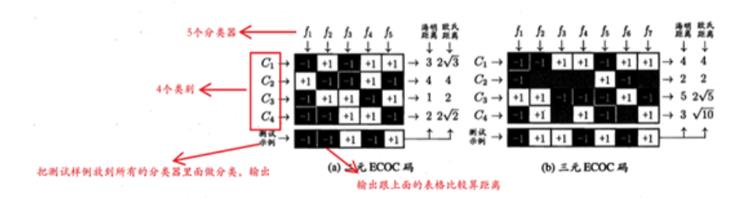
ECOC 编码示意图
但不管是哪种策略,对于每个分类器的训练集,开发者都可以先将原始训练集的标签重新定义分成两类,转化为二分类问题,然后对每个分类器作相应的心理,从而对测试集进行分类判断得到每一个分类器标签,最后在通过对各个分类器的标签得到最后的识别结果。
除此之外,选择合适的评价指标有助于选出更适合于当前任务的算法,开发者还可以为这一识别模型设计合适的评价指标。对于分类任务而言,评价指标主要关注点在于系统分类正确的能力;因此,所涉及到的评价指标可参考二分类的精确率、召回率、准确率等。
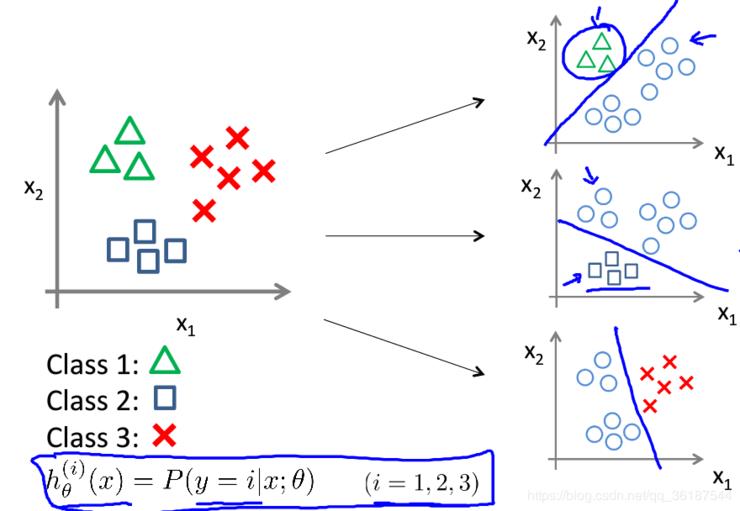
对于多类别分类,图示为两特征分 3 类
美食识别挑战(Ⅱ):茄子、山药、苦瓜 or 西兰花?
本次 AI 研习社发起的美食识别挑战赛任务即:正确判断美食图片中出现的食材。其中,食材共 4 种分类,包含了:茄子、山药、苦瓜、西兰花。
这相对于第一场美食识别系列挑战赛「土豆 or 豆腐」而言,难度有所上升。但和之前比赛相同的是,每张图片只包含了其中一种食材。

大赛主页提供了相关的数据集,包括了训练集 6140 张,测试集 856 张。参赛者需要根据美食图片中食材进行分类,其中:茄子=0、山药=1、苦瓜=2、西兰花=3。
开始时间:2020-02-13 18:00:00
结束时间:2020-03-14 23:59:59
本次大赛基础奖金池为 3000 元,比赛一共设置了三种奖项,包括了:参与奖(30%)、突破奖(20%)、排名奖(50%);AI 研习社春节红包活动仍在继续,邀请好友参赛得奖金,奖金直接划入个人账户,视同比赛奖金。以上四种奖项均互不冲突哦!

数据集部分图片示例
评审标准
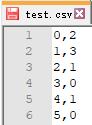
最终提交结果文件如下所示,其中,第一个字段位:测试集图片 ID(注意 ID 即文件名是从 0 开始的);第二个字段:食材 ID(茄子=0、山药=1、苦瓜=2、西兰花=3)
Ps:建议使用 UTF-8 编码,共计 856 个结果,因为数量不足可能导致无法评分哈~
整个比赛的评审完全透明化,我们将会对比选手提交的 csv 文件,确认正确分辨图片数据,并按照如下公式计算得分,其中:
True:模型分类正确数量
Total :测试集样本总数量
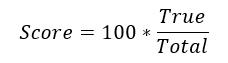
每日 24:00,我们也会将最新结果更新在官网排行榜上,你可以随时随地查看自己的排名情况。
更多信息,可进入参赛主页查看:https://god.yanxishe.com/26
敬请 扫描下方二维码 或点击文末 阅读原文 参加



点击 阅读原文,参加 美食识别挑战(2)
以上是关于图像识别之美食挑战赛 Ⅱ:由二分类到多分类,增加的不止是一点复杂度......的主要内容,如果未能解决你的问题,请参考以下文章