从0到1:神经网络实现图像识别
Posted 艾克斯007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1:神经网络实现图像识别相关的知识,希望对你有一定的参考价值。
”. . . we may have knowledge of the past and cannot control it; we may control the future but have no knowledge of it.” — Claude Shannon 1959
往者可知然不可谏,来者可追或未可知。
,介绍了神经网络的理论基石 - ;感知机模型是一个简洁的二类分类模型,这里,我们把它推广到多类分类问题,不借助计算框架,构建一个全连接神经网络,再应用于手写数字识别场景。
从二分类到多分类问题
一种思路是把 K 类分类问题,视为 K 个二类分类问题:第一次,把样本数据集的某一个类别,和余下的K-1类(合并成一个大类)做二类分类划分,识别出某一类;第 i 次,划分第i类和余下的K-i类;经过 K 次 二类分类迭代,最终完成 K 类分类。
这里,我们选用一种更直接的思路,回忆感知机二类分类模型,只包含了一个输出节点;现在把输出节点扩展为K个 ;权值向量w扩展为 D x K的权值矩阵W,偏置(bias) b扩展为长度为K的数组;这样一来,一个样本点经过模型处理,会得到这个样本点在所有K个类别上的归类可能性得分 z。
z同样是长度为K的数组,某一个元素z [j]的数值越大,输入样本点属于对应分类类别j的可能性也越高。
Softmax
Softmax方法,用于把输出z进一步标准化(normalize),得到某个样本点,归属于各个类别的概率分布。
例如,归属于类别 j 的概率为:
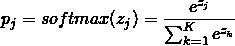
这个结果满足了概率分布的标准化要求:在所有类别上的输出概率都不小0,且所有类别上的输出概率和等于1。就得到了模型预测输出结果的标准概率分布。
对应的,目标问题MNIST数据集的正确标签,也可以视为概率分布:一张手写数字图片,在正确类别上的概率分布视为1,其它类别上为0;数字9的图片,所对应的正确标签为(0,0,0,0,0,0,0,0,0,1),可视为放平之后的分类期望向量 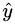 。
。
有了预测输出和正确答案的概率分布,就可以刻画两者之间相似度,简便地度量模型预测的损失。
损失函数-交叉熵
经过 Softmax 转换为标准概率分布的预测输出
,与正确类别标签之间的损失,可以用两个概率分布的 交叉熵(cross entropy)来度量: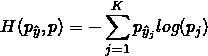
所以,某一样本点使用模型预测的损失函数,可以写为
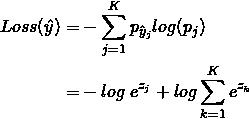 你可以跳过关于交叉熵的展开介绍,从学习算法处继续阅读,不影响方法使用。
你可以跳过关于交叉熵的展开介绍,从学习算法处继续阅读,不影响方法使用。
再深一点:关于交叉熵

1948年,Claude E Shannon首次提出信息熵(Entropy)概念。
交叉熵(Cross Entropy)的概念来自信息论 :若离散事件以真实概率 分布,则以隐概率分布
分布,则以隐概率分布 对一系列随机事件
对一系列随机事件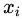 最短编码,所需要的平均比特(bits)长度。其中,定义
最短编码,所需要的平均比特(bits)长度。其中,定义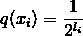 , 显然,较短的编码长度
, 显然,较短的编码长度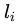 ,应当被用于出现频度 高的编码片段,以提高传输效率。
,应当被用于出现频度 高的编码片段,以提高传输效率。
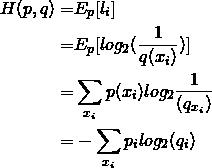
直观理解,如果有 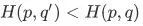 , 则相对于 , 概率分布
, 则相对于 , 概率分布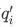 同真实概率分布 更相似。
同真实概率分布 更相似。
交叉熵对两个概率分布的度量结果,不具对称性,所以交叉熵并不是严格意义上距离。
交叉熵概念的源头,用比特(bits)信息为单位,以2为底做对数计算,那么用作损失函数Loss时,对数计算是否必须以2为底呢?
不是必须的。
机器学习领域,交叉熵被用来衡量两个概率分布的相似度,交叉熵越小,两个概率分布越相似。工程实践中,出于简化公式推导,或优化数值计算效率的考虑,对数的底可以做出其它选择。
例举以e为底的情况,由换底公式:
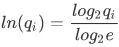
可知,对数的底由2换成e,对Loss的影响是,缩小了常数倍 ;,我们提到,优化损失函数使损失极小的场景下,函数取值的数值缩放正倍数不影响优化方法。
;,我们提到,优化损失函数使损失极小的场景下,函数取值的数值缩放正倍数不影响优化方法。
所以损失函数也可以写为: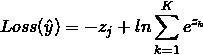
学习算法
用上一次介绍的方法,你可以先为 W, b 设置初始值比如 0,然后用梯度下降法( gradient descent),让参数不断更新梯度△W 和△b,来极小化损失函数。
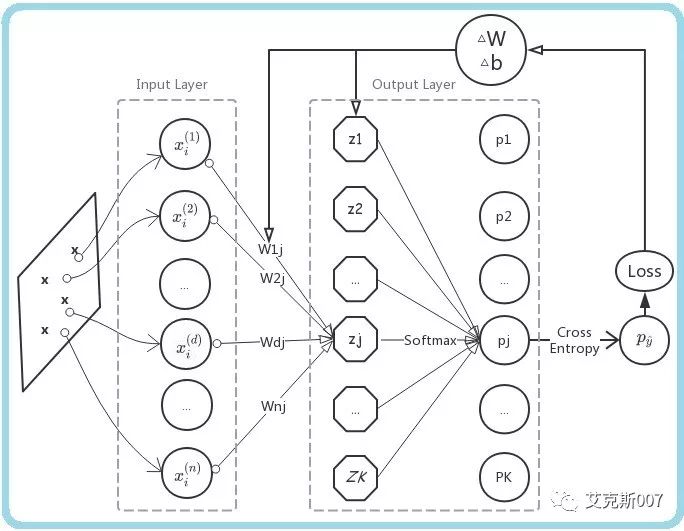
对包含D维输入特征的K类分类样例点,根据损失函数计算参数更新的梯度:
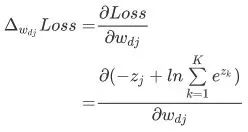
对 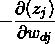 , 将
, 将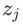 内积运算展开,易得:
内积运算展开,易得:
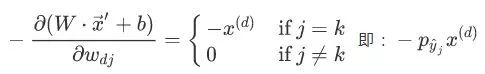
对后一部分, 应用链式法则:
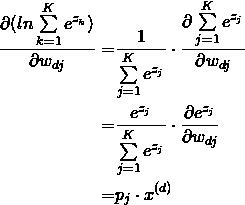
从而
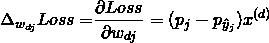
同样
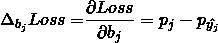 得到参数更新的梯度:
得到参数更新的梯度:
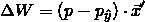
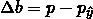
其中 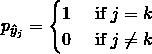
反向传播(backpropagation)
反向传播(backpropagation)是相对前向推断(inference)过程而言的。
抽取训练数据,得到预测分类结果,再使用训练数据的正确标注,计算样本预测损失,然后根据损失更新神经网络模型参数,这个迭代过程就是反向传播过程。
工程实践中,往往从训练样本集中,抽取一批(batch)训练样本,通过整批数据的矩阵运算,得到这批样本损失的均值,减少更新梯度的次数,提高训练效率;每轮训练后,使用该批次的梯度均值更新参数,较快得到接近梯度下降的收敛结果。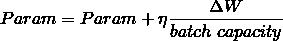 实现
实现
你可以通过原文Github链接,获得上述算法的python实现,不借助Tensorflow计算框架,直接从算法实现层面,了解全连接神经网络的基本结构,跟踪训练过程:
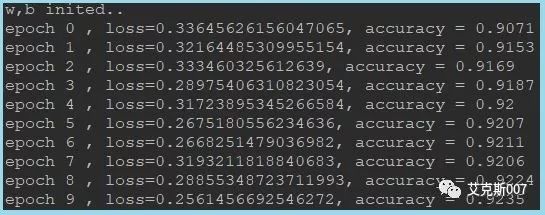
在一千五百次参数更新迭代后,模型参数在验证集上准确率超过90%;五千次迭代后,验证数据集上预测损失(Loss)趋于稳定。
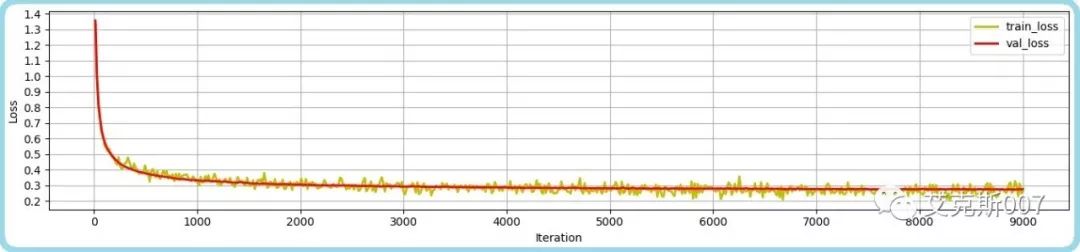
预测准确率(acc)在验证数据集上稳定于92%附近。
上述内容,介绍了全连接神经网络的基本结构,你可以结合原理与算法了解并实现它。
下一次,将介绍过拟合(over-fittingt)问题和解决方法,并在目前的基本结构上,引入一个隐藏层(Hidden Layer),将模型去线性化,使异或问题得以解决,从而将模型的预测准确率,进一步提高到96%以上。
(完)
参考
[1] 斯坦福大学 class CS231n:The Stanford CS class CS231n
[2] de Boer, PT., Kroese, D.P., Mannor, S. et al. A Tutorial on the Cross-Entropy Method. Ann Oper Res (2005) 134: 19.
长按订阅,获得更新
可以通过“原文” 查看文中链接和Github源码。
以上是关于从0到1:神经网络实现图像识别的主要内容,如果未能解决你的问题,请参考以下文章
毕业设计 题目:基于深度学习的动物识别 - 卷积神经网络 机器视觉 图像识别