神经网络做MNIST手写数字识别代码
Posted t18438605018
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络做MNIST手写数字识别代码相关的知识,希望对你有一定的参考价值。
1.MNIST数据集
MNIST数据集是由0 到9 的手写数字图像构成的。训练图像有6 万张,测试图像有1 万张每一张图片都有对应的标签数字。因此这个测试集就可以作为验证集使用。
MNIST的图像,每张图片是包含28 像素× 28 像素的灰度图像(1 通道),各个像素的取值在0 到255 之间。每张图片都由一个28 ×28 的矩阵表示,每张图片都由一个784 维的向量表示(28*28=784)。

详细介绍参考:http://yann.lecun.com/exdb/mnist/
2.用神经网络做MNIST手写数字识别
模型结构:

模型如图所示,输入二维张量展开成一维。再经过若干次组合的,Linear层和激活函数层,最后返回。
在模型使用时,后面接到交叉熵损失函数上。所以模型的最后一层不做激活。因为本身交叉熵损失函数带有激活功能。
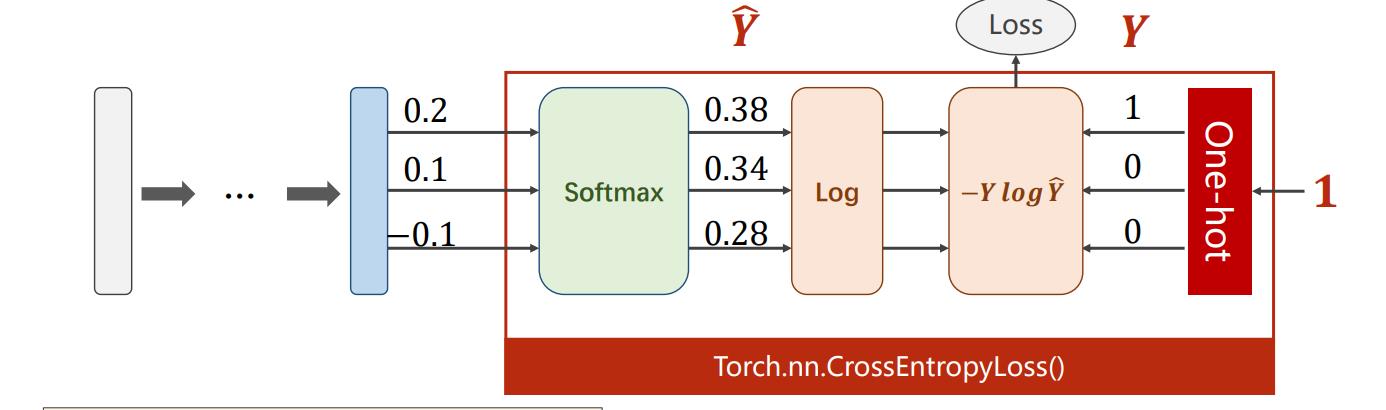
3.代码实现(python+pytorch)
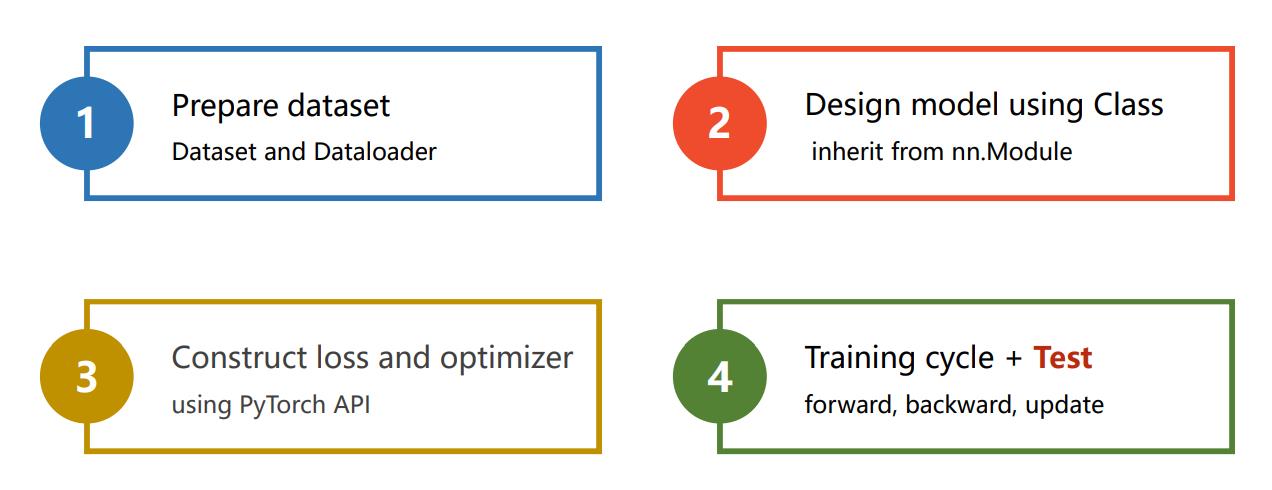
分四个步骤:
第一步:数据集准备和加载;第二步:设计模型;第三步:构建损失函数和优化器;第四步:模型的训练和验证
因pytorc中封装了很多模块。所以我们在实现时,更多的是了解各个模块的功能,以便组合使用。
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307),(0.3081)) #两个参数,平均值和标准差
])
train_dataset = datasets.MNIST(
root="../dataset/mnist/",
train= True,
download= True,
transform= transform
)
train_loader = DataLoader(train_dataset,
shuffle = True,
batch_size = batch_size)
test_dataset = datasets.MNIST(
root="../dataset/mnist/",
train=False,
download=True,
transform=transform
)
test_loder = DataLoader(test_dataset,
shuffle = True,
batch_size = batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.linear1 = torch.nn.Linear(784,512)
self.linear2 = torch.nn.Linear(512,256)
self.linear3 = torch.nn.Linear(256,128)
self.linear4 = torch.nn.Linear(128,64)
self.linear5 = torch.nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,784) # 改变张量形状。把输入展开成若干行,784列
x = F.leaky_relu(self.linear1(x))
x = F.leaky_relu(self.linear2(x))
x = F.leaky_relu(self.linear3(x))
x = F.leaky_relu(self.linear4(x))
return self.linear5(x) #最后一层不做激活,因为下一步输入到交叉损失函数中,交叉熵包含了激活层
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum= 0.5)
def train(epoch):
total = 0
running_loss = 0.0
train_loss = 0.0 #记录每次epoch的损失
accuracy = 0 #记录每次epoch的accuracy
for batch_id, data in enumerate(train_loader,0):
inputs, target = data
optimizer.zero_grad()
# forword + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
_, predicted = torch.max(outputs.data, dim=1)
accuracy += (predicted == target).sum().item()
total += target.size(0)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss = running_loss
#每迭代300次,求一下这三百次迭代的平均
if batch_id % 300 == 299:
print('[%d, %5d] loss: %.3f' %(epoch+1, batch_id+1, running_loss / 300))
running_loss = 0.0
print('第 %d epoch的 Accuracy on train set: %d %%, Loss on train set: %f' % (epoch + 1, 100 * accuracy / total, train_loss))
#返回acc和loss
return 1.0 * accuracy / total, train_loss
def validation(epoch):
correct = 0
total = 0
val_loss = 0.0
with torch.no_grad():
for data in test_loder:
images, target = data
outputs = model(images)
loss = criterion(outputs, target)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('第 %d epoch的 Accuracy on validation set: %d %%, Loss on validation set: %f' %(epoch+1,100*correct / total, val_loss))
#返回acc和loss
return 1.0 * correct / total, val_loss
#pytorch绘制loss和accuracy曲线
def draw_fig(list,name,name2,epoch):
# 我这里迭代了200次,所以x的取值范围为(0,200),然后再将每次相对应的准确率以及损失率附在x上
x1 = range(1, epoch+1)
print(x1)
y1 = list
if name=="loss":
plt.cla()
plt.title('Train loss vs. epoch', fontsize=20)
plt.plot(x1, y1, '.-')
plt.xlabel('epoch', fontsize=20)
plt.ylabel('Train loss', fontsize=20)
plt.grid()
str = "./lossAndacc/"+name2+"_loss.png"
plt.savefig(str)
plt.show()
elif name =="acc":
plt.cla()
plt.title('Train accuracy vs. epoch', fontsize=20)
plt.plot(x1, y1, '.-')
plt.xlabel('epoch', fontsize=20)
plt.ylabel('Train accuracy', fontsize=20)
plt.grid()
str2 = "./lossAndacc/" + name2 + "_accuracy.png"
plt.savefig(str2)
plt.show()
def draw_in_one(list,epoch):
# x_axix,train_pn_dis这些都是长度相同的list()
# 开始画图
x_axix = [x for x in range(1, epoch+1)] #把ranage转化为list
train_acc = list[0]
train_loss = list[1]
val_acc = list[2]
val_loss = list[3]
#sub_axix = filter(lambda x: x % 200 == 0, x_axix)
plt.title('Result Analysis')
plt.plot(x_axix, train_acc, color='green', label='training accuracy')
plt.plot(x_axix, train_loss, color='red', label='training loss')
plt.plot(x_axix, val_acc, color='skyblue', label='val accuracy')
plt.plot(x_axix, val_loss, color='blue', label='val loss')
plt.legend() # 显示图例
plt.xlabel('epoch times')
plt.ylabel('rate')
plt.show()
# python 一个折线图绘制多个曲线
if __name__ == '__main__':
train_loss = []
train_acc = []
val_loss = []
val_acc = []
epoches = 10
list = []
for epoch in range(epoches):
acc1, loss1 = train(epoch)
train_loss.append(loss1)
train_acc.append(acc1)
acc2, loss2 = validation(epoch)
val_loss.append(loss2)
val_acc.append(acc2)
#四幅图分开绘制
draw_fig(train_loss, "loss","train", epoches)
draw_fig(train_acc, "acc", "train",epoches)
draw_fig(val_loss, "loss","val", epoches)
draw_fig(val_acc, "acc","val", epoches)
# 四幅图合并绘制
list.append(train_acc)
list.append(train_loss)
list.append(val_acc)
list.append(val_loss)
draw_in_one(list, epoches)
结果:
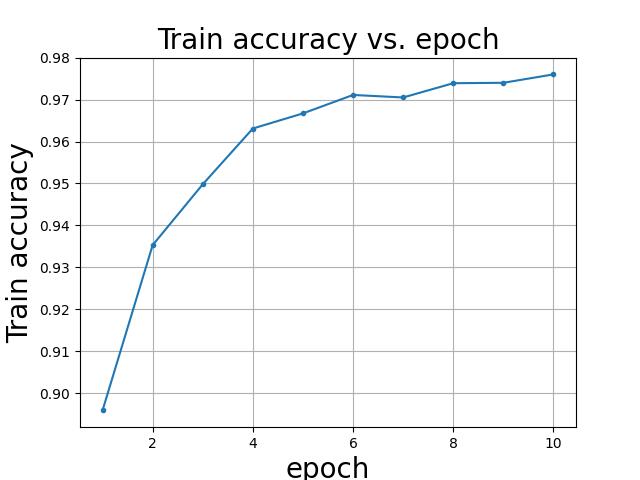
train acc
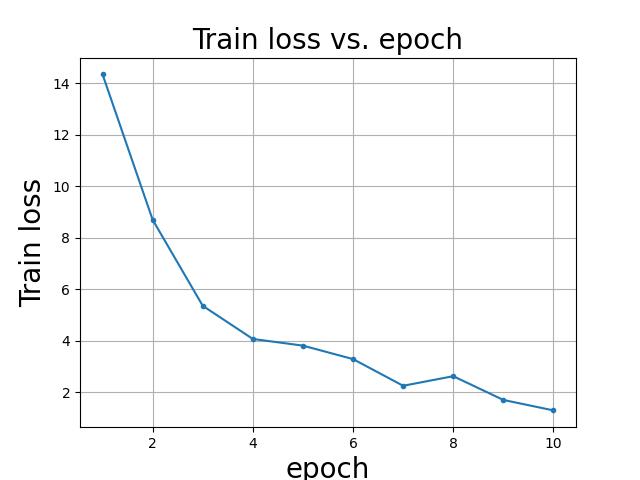
train loss
val acc
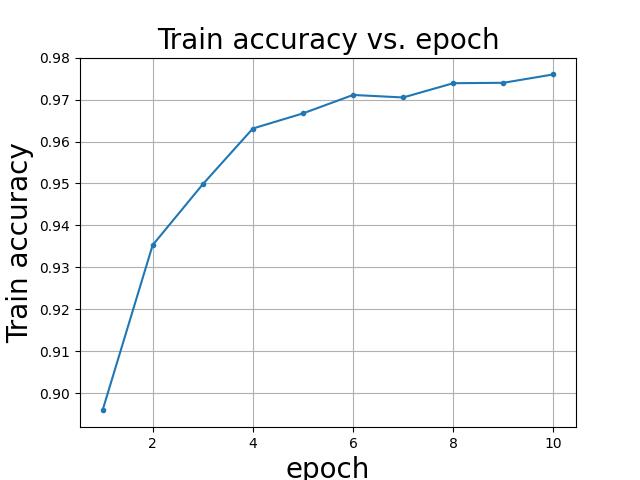
注:图的title代码中有误。读者自行更改
val loss
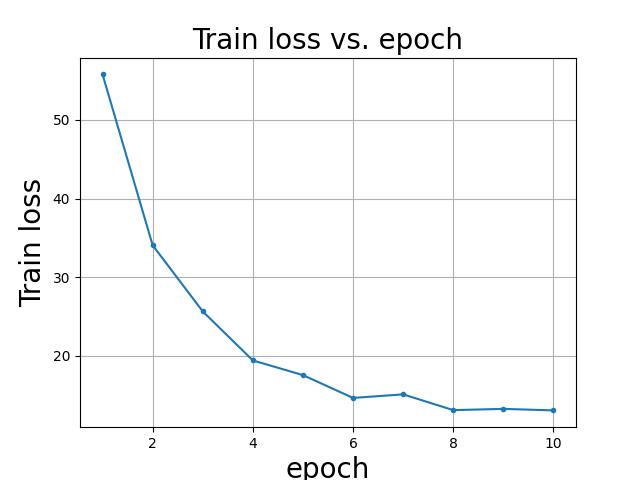
四幅图合并绘制
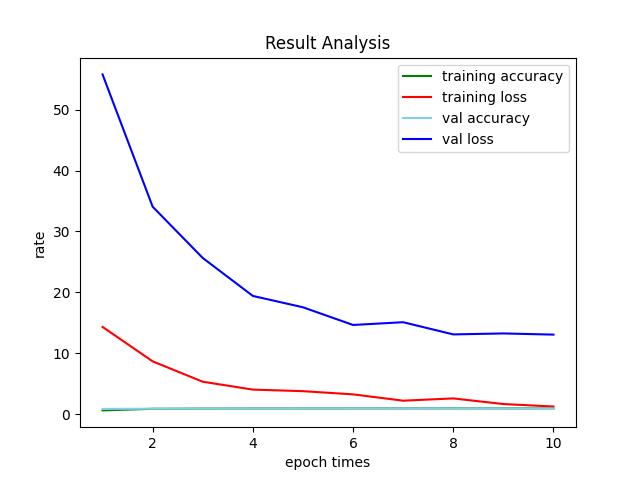
在计算这四个值时,代码可能有点小错误。导致画的图不很准确。读者发现后,自行更改吧
控制台输出内容:
E:\\anaconda3\\envs\\pytorch\\python.exe D:/PycharmProjects/pytorchProject/手写数字识别.py
[1, 300] loss: 2.211
[1, 600] loss: 0.881
[1, 900] loss: 0.439
第 1 epoch的 Accuracy on train set: 65 %, Loss on train set: 14.349343
第 1 epoch的 Accuracy on validation set: 89 %, Loss on validation set: 55.763730
[2, 300] loss: 0.325
[2, 600] loss: 0.284
[2, 900] loss: 0.242
第 2 epoch的 Accuracy on train set: 91 %, Loss on train set: 8.700389
第 2 epoch的 Accuracy on validation set: 93 %, Loss on validation set: 34.062688
[3, 300] loss: 0.199
[3, 600] loss: 0.180
[3, 900] loss: 0.159
第 3 epoch的 Accuracy on train set: 94 %, Loss on train set: 5.356741
第 3 epoch的 Accuracy on validation set: 94 %, Loss on validation set: 25.656663
[4, 300] loss: 0.138
[4, 600] loss: 0.131
[4, 900] loss: 0.117
第 4 epoch的 Accuracy on train set: 96 %, Loss on train set: 4.067950
第 4 epoch的 Accuracy on validation set: 96 %, Loss on validation set: 19.429859
[5, 300] loss: 0.110
[5, 600] loss: 0.093
[5, 900] loss: 0.095
第 5 epoch的 Accuracy on train set: 97 %, Loss on train set: 3.809268
第 5 epoch的 Accuracy on validation set: 96 %, Loss on validation set: 17.569023
[6, 300] loss: 0.080
[6, 600] loss: 0.082
[6, 900] loss: 0.074
第 6 epoch的 Accuracy on train set: 97 %, Loss on train set: 3.285731
第 6 epoch的 Accuracy on validation set: 97 %, Loss on validation set: 14.668039
[7, 300] loss: 0.062
[7, 600] loss: 0.068
[7, 900] loss: 0.064
第 7 epoch的 Accuracy on train set: 98 %, Loss on train set: 2.248924
第 7 epoch的 Accuracy on validation set: 97 %, Loss on validation set: 15.119584
[8, 300] loss: 0.048
[8, 600] loss: 0.055
[8, 900] loss: 0.053
第 8 epoch的 Accuracy on train set: 98 %, Loss on train set: 2.621493
第 8 epoch的 Accuracy on validation set: 97 %, Loss on validation set: 13.119277
[9, 300] loss: 0.042
[9, 600] loss: 0.041
[9, 900] loss: 0.047
第 9 epoch的 Accuracy on train set: 98 %, Loss on train set: 1.698503
第 9 epoch的 Accuracy on validation set: 97 %, Loss on validation set: 13.277307
[10, 300] loss: 0.029
[10, 600] loss: 0.037
[10, 900] loss: 0.040
第 10 epoch的 Accuracy on train set: 98 %, Loss on train set: 1.292258
第 10 epoch的 Accuracy on validation set: 97 %, Loss on validation set: 13.084560
range(1, 11)
range(1, 11)
range(1, 11)
range(1, 11)
Process finished with exit code 0
以上是关于神经网络做MNIST手写数字识别代码的主要内容,如果未能解决你的问题,请参考以下文章