机器学习算法之——隐马尔可夫(Hidden Markov ModelsHMM)原理及Python实现
Posted 生信逻辑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习算法之——隐马尔可夫(Hidden Markov ModelsHMM)原理及Python实现相关的知识,希望对你有一定的参考价值。
机器学习算法之——隐马尔可夫(Hidden Markov ModelsHMM)原理及Python实现
前言
上星期写了Kaggle竞赛的详细介绍及入门指导,但对于真正想要玩这个竞赛的伙伴,机器学习中的相关算法是必不可少的,即使是你不想获得名次和奖牌。那么,从本周开始,我将介绍在Kaggle比赛中的最基本的也是运用最广的机器学习算法,很多项目用这些基本的模型就能解决基础问题了。
今天我们开始介绍隐马尔可夫模型(Hidden Markov Models,HMM),本模型的先学模型是马尔科夫模型,如果是基础学习者,请参看该链接:马尔可夫模型 jiqizhixin.com/graph/te。
1 概述
隐马尔可夫模型(Hidden Markov Model,HMM)是结构最简单的动态贝叶斯网,这是一种著名的有向图模型,主要用于时序数据建模(语音识别、自然语言处理等)。
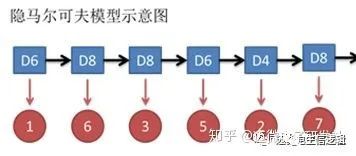
假设有三个不同的骰子(6面、4面、8面),每次先从三个骰子里选一个,每个骰子选中的概率为1/3,如下图所示,重复上述过程,得到一串数字[1 6 3 5 2 7]。这些可观测变量组成可观测状态链。
同时,在隐马尔可夫模型中还有一条由隐变量组成的隐含状态链,在本例中即骰子的序列。比如得到这串数字骰子的序列可能为[D6 D8 D8 D6 D4 D8]。
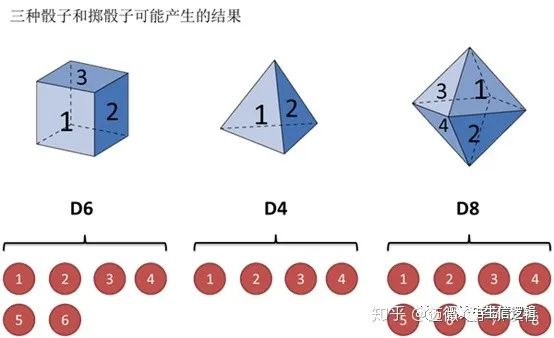
隐马尔可夫模型示意图如下所示:
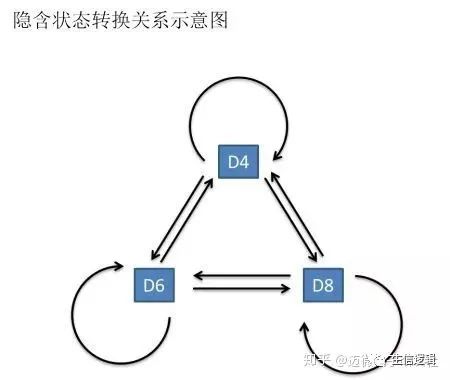
图中,箭头表示变量之间的依赖关系。在任意时刻,观测变量(骰子点数)仅依赖于状态变量(哪类骰子),“观测独立性假设”。
同时,t时刻的状态qt仅依赖于t-1时刻的状态qt-1。这就是马尔可夫链,即系统的下一时刻的状态仅由当前状态决定不依赖以往的任何状态(无记忆性),“齐次马尔可夫性假设”。
2 隐马尔可夫模型三要素
对于一个隐马尔可夫模型,它的所有N个可能的状态的集合Q={q1,q2,…,qN},所有M个可能的观测集合V={v1,v2,…,vM}
隐马尔可夫模型三要素:
状态转移概率矩阵A,A=[aij]NxN,aij表示任意时刻t状态qi条件下,下一时刻t+1状态为qj的概率;
观测概率矩阵B,B=[bij]NxM,bij表示任意时刻t状态qi条件下,生成观测值vj的概率;
初始状态概率向量Π,Π=(π1,π2,…,πN),πi表示初始时刻t=1,状态为qi的概率。
一个隐马尔可夫模型可由λ=(A, B, Π)来指代。
3 隐马尔可夫模型的三个基本问题
(1) 给定模型λ=(A, B, Π),计算其产生观测序列O={o1,o2,…,oT}的概率P(O|λ);
计算掷出点数163527的概率(2) 给定模型λ=(A, B, Π)和观测序列O={o1,o2,…,oT},推断能够最大概率产生此观测序列的状态序列I={i1,i2,…,iT},即使P(I|O)最大的I;
推断掷出点数163527的骰子种类(3) 给定观测序列O={o1,o2,…,oT},估计模型λ=(A, B, Π)的参数,使P(O|λ)最大;
已知骰子有几种,不知道骰子的种类,根据多次掷出骰子的结果,反推出骰子的种类
这三个基本问题在现实应用中非常重要,例如根据观测序列O={o1,o2,…,oT-1,}推测当前时刻最有可能出现的观测值OT,这就转换成基本问题(1);
在语音识别中,观测值为语音信号,隐藏状态为文字,根据观测信号推断最有可能的状态序列,即基本问题(2);
在大多数应用中,人工指定参数模型已变得越来越不可行,如何根据训练样本学得最优参数模型,就是基本问题(3)。
4 三个基本问题的解法
基于两个条件独立假设,隐马尔可夫模型的这三个基本问题均能被高效求解。
4.1 基本问题(1)解法
4.1.1 直接计算法(概念上可行,计算上不可行)
通过列举所有可能的长度为T的状态序列I=(i1,i2,…,iT),求各个状态序列I与观测序列O同时出现的联合概率P(I,O|λ),然后对所有可能求和得到P(O|λ)。
状态序列I=(i1,i2,…,iT)的概率是P(I|λ)=π1a12a23…a(T-1)T
对于固定状态序列 I,观测序O=(o1,o2,…,oT)的概率P(O|I,λ)= b11b22…bTT
I 和 O同时出现的联合概率P(I,O|λ)= P(I|λ) P(O|I,λ)
然后对所有可能的 I 求和,得到P(O|λ)
这种方法计算量很大,算法不可行。
4.1.2 前向算法(forward algorithm)(t=1,一步一步向前计算)
前向概率αt(i)= P(o1,o2,…,ot,ii=qi|λ),表示模型λ,时刻 t,观测序列为o1,o2,…,ot且状态为qi的概率。
(1) 初始化前向概率
状态为qi和观测值为o1的联合概率 α1(i)=π1bi1
(2) 递推t=1,2,…,T-1
根据下图,得到αt+1(i)= [Σj=1,…,Nαt(j)αji]bi(t+1)
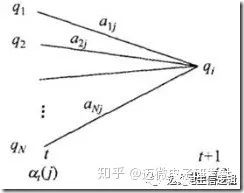
(3) 终止 P(O|λ) = Σi=1,…,NαT(i)
前向算法高效的关键是其局部计算前向概率,根据路径结构,如下图所示,每次计算直接利用前一时刻计算结果,避免重复计算,减少计算量。
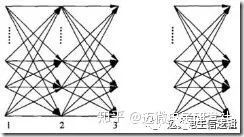
4.1.3 后向算法(backward algorithm)
后向概率βt(i) = P(o1,o2,…,ot,ii=qi|λ),表示模型λ,时刻t,从t+1到时刻T观测序列o1,o2,…,ot且状态为qi的概率。
(1)初始化后向概率
对最终时刻的所有状态为qi规定βT(i) = 1。
(2)递推t=T-1,T-2,…,1
根据下图,计算t时刻状态为qi,且时刻t+1之后的观测序列为ot+1,ot+2,…,ot的后向概率。只需考虑t+1时刻所有可能的N个状态qi的转移概率(transition probability) αij,以及在此状态下的观测概率bi(t+1),然后考虑qj之后的后向概率βt+1(j),得到
βt(i) = Σj=1,…,Nβt+1(j)αijbi(t+1).
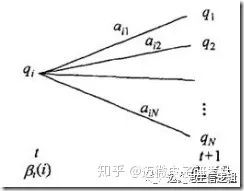
(3) 终止 P(O|λ) = Σi=1,…,Nβ1(i)πibi1
前向算法高效的关键是其局部计算前向概率,根据路径结构,如下图所示,每次计算直接利用前一时刻计算结果,避免重复计算,减少计算量。
4.2 基本问题(2)解法
4.2.1 近似算法
选择每一时刻最有可能出现的状态,从而得到一个状态序列。这个方法计算简单,但是不能保证整个状态序列的出现概率最大。因为可能出现转移概率为0的相邻状态。
4.2.2 Viterbi算法
使用动态规划求解概率最大(最优)路径。t=1时刻开始,递推地计算在时刻t状态为i的各条部分路径的最大概率,直到计算到时刻T,状态为i的各条路径的最大概率,时刻T的最大概率即为最优路径的概率,最优路径的节点也同时得到。
如果还不明白,看一下李航《统计学习方法》的186-187页的例题就能明白算法的原理。
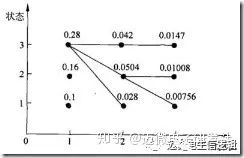
状态[3 3 3]极为概率最大路径。
4.3 基本问题(3)解法
4.3.1 监督学习方法
给定S个长度相同的(观测序列,状态序列)作为训练集(O1,I1),O2,I3),…, (Os,Is)使用极大似然估计法来估计模型参数。
转移概率αij 的估计:样本中t时刻处于状态i,t+1时刻转移到状态j的频数为αij,则
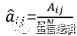
观测概率bij和初始状态概率πi的估计类似。
4.3.2 Baum-Welch算法
使用EM算法得到模型参数估计式

EM算法是常用的估计参数隐变量的利器,它是一种迭代方法,基本思想是:
(1) 选择模型参数初始值;
(2) (E步)根据给定的观测数据和模型参数,求隐变量的期望;
(3) (M步)根据已得隐变量期望和观测数据,对模型参数做极大似然估计,得到新的模型参数,重复第二步。
5 Python代码实现
5.1 Baum-Welch算法的程序实现
这里提供Baum-Welch算法的代码实现。
本来打算试一下用自己写的HMM跑一下中文分词,但很可惜,代码运行的比较慢。所以改成 模拟 三角波 以及 正弦波。
# encoding=utf8
import numpy as np
import csv
class HMM(object):
def __init__(self,N,M):
self.A = np.zeros((N,N)) # 状态转移概率矩阵
self.B = np.zeros((N,M)) # 观测概率矩阵
self.Pi = np.array([1.0/N]*N) # 初始状态概率矩阵
self.N = N # 可能的状态数
self.M = M # 可能的观测数
def cal_probality(self, O):
self.T = len(O)
self.O = O
self.forward()
return sum(self.alpha[self.T-1])
def forward(self):
"""
前向算法
"""
self.alpha = np.zeros((self.T,self.N))
# 公式 10.15
for i in range(self.N):
self.alpha[0][i] = self.Pi[i]*self.B[i][self.O[0]]
# 公式10.16
for t in range(1,self.T):
for i in range(self.N):
sum = 0
for j in range(self.N):
sum += self.alpha[t-1][j]*self.A[j][i]
self.alpha[t][i] = sum * self.B[i][self.O[t]]
def backward(self):
"""
后向算法
"""
self.beta = np.zeros((self.T,self.N))
# 公式10.19
for i in range(self.N):
self.beta[self.T-1][i] = 1
# 公式10.20
for t in range(self.T-2,-1,-1):
for i in range(self.N):
for j in range(self.N):
self.beta[t][i] += self.A[i][j]*self.B[j][self.O[t+1]]*self.beta[t+1][j]
def cal_gamma(self, i, t):
"""
公式 10.24
"""
numerator = self.alpha[t][i]*self.beta[t][i]
denominator = 0
for j in range(self.N):
denominator += self.alpha[t][j]*self.beta[t][j]
return numerator/denominator
def cal_ksi(self, i, j, t):
"""
公式 10.26
"""
numerator = self.alpha[t][i]*self.A[i][j]*self.B[j][self.O[t+1]]*self.beta[t+1][j]
denominator = 0
for i in range(self.N):
for j in range(self.N):
denominator += self.alpha[t][i]*self.A[i][j]*self.B[j][self.O[t+1]]*self.beta[t+1][j]
return numerator/denominator
def init(self):
"""
随机生成 A,B,Pi
并保证每行相加等于 1
"""
import random
for i in range(self.N):
randomlist = [random.randint(0,100) for t in range(self.N)]
Sum = sum(randomlist)
for j in range(self.N):
self.A[i][j] = randomlist[j]/Sum
for i in range(self.N):
randomlist = [random.randint(0,100) for t in range(self.M)]
Sum = sum(randomlist)
for j in range(self.M):
self.B[i][j] = randomlist[j]/Sum
def train(self, O, MaxSteps = 100):
self.T = len(O)
self.O = O
# 初始化
self.init()
step = 0
# 递推
while step<MaxSteps:
step+=1
print(step)
tmp_A = np.zeros((self.N,self.N))
tmp_B = np.zeros((self.N,self.M))
tmp_pi = np.array([0.0]*self.N)
self.forward()
self.backward()
# a_{ij}
for i in range(self.N):
for j in range(self.N):
numerator=0.0
denominator=0.0
for t in range(self.T-1):
numerator += self.cal_ksi(i,j,t)
denominator += self.cal_gamma(i,t)
tmp_A[i][j] = numerator/denominator
# b_{jk}
for j in range(self.N):
for k in range(self.M):
numerator = 0.0
denominator = 0.0
for t in range(self.T):
if k == self.O[t]:
numerator += self.cal_gamma(j,t)
denominator += self.cal_gamma(j,t)
tmp_B[j][k] = numerator / denominator
# pi_i
for i in range(self.N):
tmp_pi[i] = self.cal_gamma(i,0)
self.A = tmp_A
self.B = tmp_B
self.Pi = tmp_pi
def generate(self, length):
import random
I = []
# start
ran = random.randint(0,1000)/1000.0
i = 0
while self.Pi[i]<ran or self.Pi[i]<0.0001:
ran -= self.Pi[i]
i += 1
I.append(i)
# 生成状态序列
for i in range(1,length):
last = I[-1]
ran = random.randint(0, 1000) / 1000.0
i = 0
while self.A[last][i] < ran or self.A[last][i]<0.0001:
ran -= self.A[last][i]
i += 1
I.append(i)
# 生成观测序列
Y = []
for i in range(length):
k = 0
ran = random.randint(0, 1000) / 1000.0
while self.B[I[i]][k] < ran or self.B[I[i]][k]<0.0001:
ran -= self.B[I[i]][k]
k += 1
Y.append(k)
return Y
def triangle(length):
'''
三角波
'''
X = [i for i in range(length)]
Y = []
for x in X:
x = x % 6
if x <= 3:
Y.append(x)
else:
Y.append(6-x)
return X,Y
def show_data(x,y):
import matplotlib.pyplot as plt
plt.plot(x, y, 'g')
plt.show()
return y
if __name__ == '__main__':
hmm = HMM(10,4)
tri_x, tri_y = triangle(20)
hmm.train(tri_y)
y = hmm.generate(100)
print(y)
x = [i for i in range(100)]
show_data(x,y)5.2 运行结果
5.2.1 三角波
三角波比较简单,我设置N=10,扔进去长度为20的序列,训练100次,下图是其生成的长度为100的序列。
可以看出效果还是很不错的。
5.2.2 正弦波
正弦波有些麻烦,因为观测序列不能太大,所以我设置N=15,M=100,扔进去长度为40的序列,训练100次,训练的非常慢,下图是其生成的长度为100的序列。
可以看出效果一般,如果改成C的代码,并增加N应该是能模拟的。
6 HMM的实际应用举例
请参看另一篇文章,基于隐马尔科夫模型(HMM)的地图匹配(Map-Matching)算法 原文链接:cnblogs.com/mindpuzzle/
参考文献:
[1] 如何用简单易懂的例子解释隐马尔可夫模型 原文链接:zhihu.com/question/2096
[2]《机器学习》周志华
[3]《统计学习方法》李航
[4] 隐马尔科夫模型(HMM)及其Python实现 原文链接:blog.csdn.net/fengyanqi
以上是关于机器学习算法之——隐马尔可夫(Hidden Markov ModelsHMM)原理及Python实现的主要内容,如果未能解决你的问题,请参考以下文章
隐马尔可夫模型(Hidden Markov model, HMM)
大道至简机器学习算法之隐马尔科夫模型(Hidden Markov Model, HMM)详解---学习问题:Baum-Welch算法推导