Go语言之中文分词技术使用技巧
Posted 跳动的代码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Go语言之中文分词技术使用技巧相关的知识,希望对你有一定的参考价值。
中文分词(Chinese Word Segmentation)指的是将一个汉字序列(句子)切分成一个一个的单独的词,分词就是将连续的字序列按照一定的规则重新组合成词序列的过程。
现在分词方法大致有三种:基于字符串配置的分词方法、基于理解的分词方法和基于统计的分词方法。
今天为大家分享一个国内使用人数最多的中文分词工具GoJieba。
官方文档:http://www.github.com/yanyiwu/gojieba/wiki
官方介绍
支持多种分词方式,包括: 最大概率模式, HMM新词发现模式, 搜索引擎模式, 全模式
核心算法底层由C++实现,性能高效。
无缝集成到 Bleve 到进行搜索引擎的中文分词功能。
字典路径可配置,NewJieba(...string), NewExtractor(...string) 可变形参,当参数为空时使用默认词典(推荐方式)
模式扩展
精确模式:将句子精确切开,适合文本字符分析
全模式:把短语中所有的可以组成词语的部分扫描出来,速度非常快,会有歧义
搜索引擎模式:精确模式基础上,对长词再次切分,提升引擎召回率,适用于搜索引擎分词
主要算法
前缀词典实现高效的词图扫描,生成句子中汉字所有可能出现成词情况所构成的有向无环图(DAG)
采用动态规划查找最大概率路径,找出基于词频最大切分组合
对于未登录词,采用汉字成词能力的HMM模型,采用Viterbi算法计算
基于Viterbi算法做词性标注
基于TF-IDF和TextRank模型抽取关键词
编码实现
package mainimport ("fmt""github.com/yanyiwu/gojieba""strings")func main() {var seg = gojieba.NewJieba()defer seg.Free()var useHmm = truevar separator = "|"var resWords []stringvar sentence = "万里长城万里长"resWords = seg.CutAll(sentence)fmt.Printf("%s 全模式:%s ", sentence, strings.Join(resWords, separator))resWords = seg.Cut(sentence, useHmm)fmt.Printf("%s 精确模式:%s ", sentence, strings.Join(resWords, separator))var addWord = "万里长"seg.AddWord(addWord)fmt.Printf("添加新词:%s ", addWord)resWords = seg.Cut(sentence, useHmm)fmt.Printf("%s 精确模式:%s ", sentence, strings.Join(resWords, separator))sentence = "北京鲜花速递"resWords = seg.Cut(sentence, useHmm)fmt.Printf("%s 新词识别:%s ", sentence, strings.Join(resWords, separator))sentence = "北京鲜花速递"resWords = seg.CutForSearch(sentence, useHmm)fmt.Println(sentence, " 搜索引擎模式:", strings.Join(resWords, separator))sentence = "北京市朝阳公园"resWords = seg.Tag(sentence)fmt.Println(sentence, " 词性标注:", strings.Join(resWords, separator))sentence = "鲁迅先生"resWords = seg.CutForSearch(sentence, !useHmm)fmt.Println(sentence, " 搜索引擎模式:", strings.Join(resWords, separator))words := seg.Tokenize(sentence, gojieba.SearchMode, !useHmm)fmt.Println(sentence, " Tokenize Search Mode 搜索引擎模式:", words)words = seg.Tokenize(sentence, gojieba.DefaultMode, !useHmm)fmt.Println(sentence, " Tokenize Default Mode搜索引擎模式:", words)word2 := seg.ExtractWithWeight(sentence, 5)fmt.Println(sentence, " Extract:", word2)return}
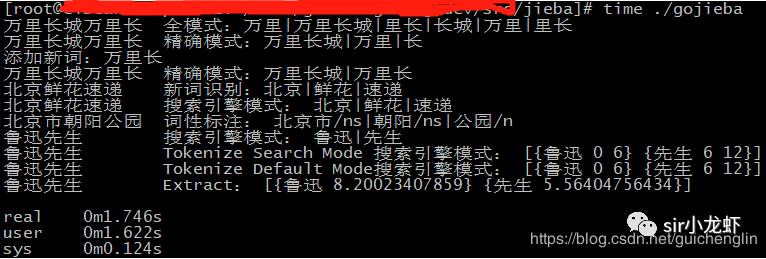
运行结果
go build -o gojiebatime ./gojieba万里长城万里长 全模式:万里|万里长城|里长|长城|万里|里长万里长城万里长 精确模式:万里长城|万里|长添加新词:万里长万里长城万里长 精确模式:万里长城|万里长北京鲜花速递 新词识别:北京|鲜花|速递北京鲜花速递 搜索引擎模式:北京|鲜花|速递北京市朝阳公园 词性标注:北京市/ns|朝阳/ns|公园/n鲁迅先生 搜索引擎模式:鲁迅|先生鲁迅先生 Tokenize Search Mode 搜索引擎模式:[{鲁迅 0 6} {先生 6 12}]鲁迅先生 Tokenize Default Mode搜索引擎模式:[{鲁迅 0 6} {先生 6 12}]鲁迅先生 Extract:[{鲁迅 8.20023407859} {先生 5.56404756434}]real 0m1.746suser 0m1.622ssys 0m0.124s
性能评测
计算分词过程的耗时,不包括加载词典耗时,CppJieba性能是GoJieba的1.2倍。CppJieba性能详见jieba-performance-comparison,GoJieba由于是C++开发的CppJieba,性能方面仅次于CppJieba,如果追求性能还是可以考虑的。
以上是关于Go语言之中文分词技术使用技巧的主要内容,如果未能解决你的问题,请参考以下文章