NLP | NLP基础之中文分词
Posted 人工智能技术研究
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP | NLP基础之中文分词相关的知识,希望对你有一定的参考价值。
今天我们来讲一讲,自然语言处理中的最基础的技术,中文分词。
什么是中文分词
中文分词(Chinese Word Segmentation)指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序的过程。
主要的分词算法
基于词表的分词算法
1)、正向最大匹配算法(FMM):对于输入的一段文本从左至右、以贪心的方式切分出当前位置上长度最大的词。
分词原理是:单词的颗粒越大,所能表示的含义越确切。
该算法主要分为以下步骤:
(1).从左到右取待切分的前m个字符(m为词典里最长的词的字符数),如果序列不足最大词长,则选择全部序列。
(2).若这m个字符属于词典里的词,则匹配成功,然后将这m个字符切分出来,剩下的词语作为新的待切分的语句,如果这m个字符不属于词典里的词,则从右边开始,减少一个字符,剩余的m-1个字符继续匹配看是否在词典中,依次循环,逐到只剩下一个字。
(3). 重复以上步骤,直到句子切分完。
#使用正向最大匹配算法实现中文分词 FMMwords_dic = []def init():"""读取词典文件载入词典"""with open("dic/dic.txt","r",encoding="utf8") as dic_input:for word in dic_input:words_dic.append(word.strip())#实现正向匹配算法中的切词方法def cut_words(raw_sentence,words_dic):#统计词典中最长的词max_length = max(len(word) for word in words_dic)sentence = raw_sentence.strip()#统计序列长度words_length = len(sentence)#存储切分好的词语cut_word_list = []while words_length > 0:max_cut_length = min(max_length,words_length)subSentence = sentence[0:max_cut_length]while max_cut_length > 0:if subSentence in words_dic:cut_word_list.append(subSentence)breakelif max_cut_length == 1:cut_word_list.append(subSentence)breakelse:max_cut_length = max_cut_length - 1subSentence = subSentence[0:max_cut_length]sentence = sentence[max_cut_length:]words_length = words_length - max_cut_lengthword = "/".join(cut_word_list)return cut_word_listdef main():"""用于用户交互接口"""init()while True:input_str = '我在学习自然语言处理'result = cut_words(input_str,words_dic)print("分词结果")print(result)if __name__ == "__main__":main()
输出结果如下:
我/在/学习/自然语言处理
2)、逆向最大匹配算法(RMM):基本原理与正向最大匹配算法类似,只是分词顺序变为从右至左。
RMM.py
#使用逆向最大匹配算法实现中文分词RMMwords_dic = []def init():"""读取词典文件载入词典"""with open("dic/dic.txt","r",encoding="utf8") as dic_input:for word in dic_input:words_dic.append(word.strip())#实现逆向匹配算法中的切词方法def cut_words(raw_sentence,words_dic):#统计词典中词的最长长度max_length = max(len(word) for word in words_dic)sentence = raw_sentence.strip()#统计序列长度words_length = len(sentence)#存储切分好的词语cut_word_list = []#判断是否需要继续切词while words_length > 0:max_cut_length = min(max_length,words_length)subSentence = sentence[-max_cut_length:]while max_cut_length > 0:if subSentence in words_dic:cut_word_list.append(subSentence)breakelif max_cut_length == 1:cut_word_list.append(subSentence)breakelse:max_cut_length = max_cut_length - 1subSentence = subSentence[-max_cut_length:]sentence = sentence[0:-max_cut_length:]words_length = words_length - max_cut_lengthcut_word_list.reverse()word = "/".join(cut_word_list)return cut_word_listdef main():"""用于用户交互接口"""init()while True:input_str = '我在学习自然语言处理'result = cut_words(input_str,words_dic)print("分词结果")print(result)if __name__ == "__main__":main()
输出结果如下:
3)、 双向最大匹配算法(Bi-MM):即正向与反向相结合,实现双向最大匹配。对分词结果进一步处理,比较两个结果。筛选出两者中更确切的分词结果。
import RMMimport FMM#使用双向最大匹配算法实现中文分词words_dic = []def init():"""读取词典文件载入词典"""with open("dic/dic.txt","r",encoding="utf8") as dic_input:for word in dic_input:words_dic.append(word.strip())#实现双向匹配算法中的切词方法def cut_words(raw_sentence,words_dic):bmm_word_list = BMM.cut_words(raw_sentence,words_dic)fmm_word_list = FMM.cut_words(raw_sentence,words_dic)bmm_word_list_size = len(bmm_word_list)fmm_word_list_size = len(fmm_word_list)if bmm_word_list_size != fmm_word_list_size:if bmm_word_list_size < fmm_word_list_size:return bmm_word_listelse:return fmm_word_listelse:FSingle = 0BSingle = 0isSame = Truefor i in range(len(fmm_word_list)):if fmm_word_list[i] not in bmm_word_list:isSame = Falseif len(fmm_word_list[i]) == 1:FSingle = FSingle + 1if len(bmm_word_list[i]) == 1:BSingle = BSingle + 1if isSame:return fmm_word_listelif BSingle > FSinglereturn fmm_word_listelse:return bmm_word_listdef main():"""用于用户交互接口"""init()while True:print("请输入要分词的序列")input_str = input()if not input_str:breakresult = cut_words(input_str,words_dic)print("分词结果")print(result)if __name__ == "__main__":main()
基于统计模型的分词算法
1)、基于N-gram语言模型的分词算法
如何判断一个句子是否合理,很容易想到一种很好的统计模型来解决上述问题,只需要看它在所有句子中出现的概率就行了。
第一个句子出现的概率大概是80%,第二个句子出现的概率大概是50%,第三个句子出现的概率大概是20%,第一个句子出现的可能性最大,因此这个句子最合理。
假设下一个词的出现依赖它前面的一个词或依赖它前面的两个词。
假设想知道S在文本中出现的可能性,也就是数学上所说的S的概率,既然
计算
假设一个词
现在,S的概率就变得简单了
那么,接下来的问题就变成了估计条件概率
当样本量很大的时候,基于大数定律,一个短语或者词语出现的概率可以用其频率来表示是,即
其中,count(i)表示单词i出现的次数,count表示语料库的大小。
那么
N-gram语言模型的分词算法是利用信息找出一条概率最大的路径
假设随机变量S为一个汉字序列,W是S上所有可能的切分路径。对于分词,实际上就是求解使条件概率
W^* = argmax P(w|s)
根据贝叶斯公式:
W^* = argmax P(w)P(S|W)/P(S)
由于P(S)为归一化因子,P(S|W)恒为1,因此只需求解P(W)
基于序列标注的分词算法
1)、基于HMM的分词方法
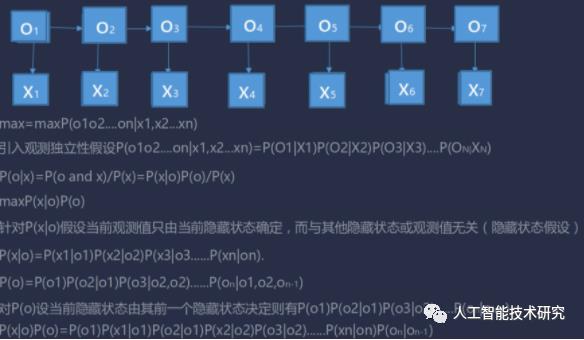
首先我们转换下思维,把分词问题做个转换:分词问题就是句子中的每个字打标注,标注要么是一个词的开始(B),要么是一个词的中间位置(M),要么是一个词的结束位置(E),还有单个字的词,用S表示。
下面对中文分词进行形式化描述:
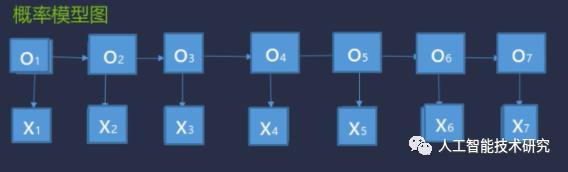
设观察集合O={
问题:已知输入的观察序列为:X =
求对应的状态序列:Y =
基于HMM的分词方法:属于由字构词的分词方法,由字构词的分词方法思想,就是将分词问题转化为字的分类问题(序列标注问题)。
从某些层面讲,由字构词的方法并不依赖于事先编制好的词表,但仍然需要分好词的训练语料。
规定每个字有4个词位:词首B、词中M、词尾E、单字成词S

由于HMM是一个生成式模型,X为观测序列,Y为隐序列
基本思路
每个字在构造一个特定的词语时都占据着一个确定的构词位置(即词位),规定每个字最多只有四个构词位置:即B(词首)、M(词中)、E(词尾)、S(单独成词)。
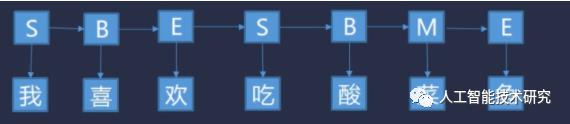
把带求解的标志用O1,O2,...,O7表示,把输入用X表示。然后观察线带来的关系。
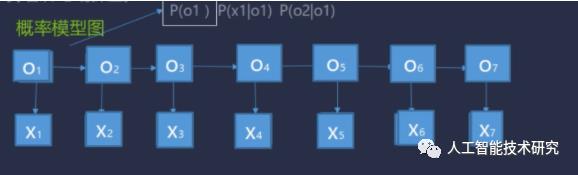
O1取B,取M,取E,取S的概率是多大.
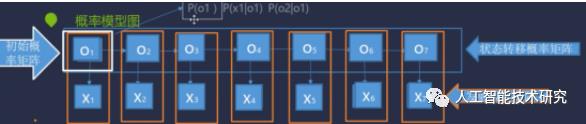
Viterbi算法讲解
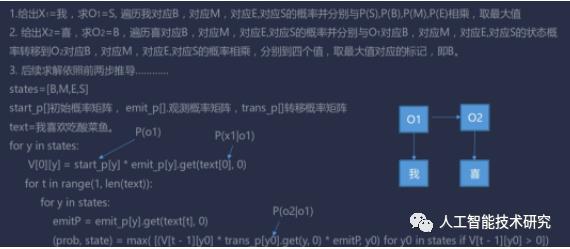
1).当前观测值只由当前隐藏状态确定,而与其他隐藏状态或观测值无关(隐藏状态假设)
2).当前隐藏状态由其前一个隐藏状态决定(一阶马尔科夫假设)
3).隐藏状态之间的转换函数概率不随时间变化(转换函数稳定性假设)
三大概率矩阵
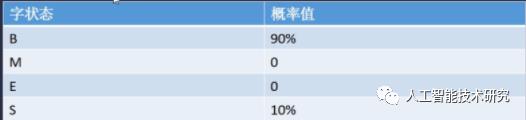
start_p[]初始概率矩阵
设语料库中有1000条句子,以B开始即以词语开始的句子有900条,以S开始的句子有100条
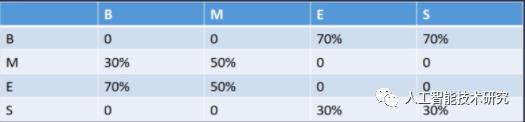
trans_p[] 转移概率矩阵
设语料库中有M标记字一共有100个,以B开始转移到M有30个,转移到E有70个
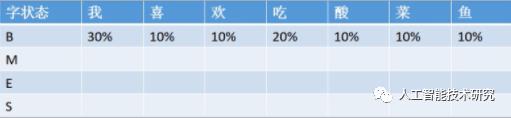
emit_p[] 观测概率矩阵
语料库中有B标记字一共有100个,以B为条件得到'我'字有30个...
HMM公式推导
2)、基于CRF的分词方法
CRF分词原理
CRF把分词当做字的词位分类问题,通常定义字的词位信息如下:
词首,常用B表示
词中,常用M表示
词尾,常用E表示
单字词,常用S表示
CRF分词的过程就是对词位标注后,将B和E之间的字,以及S单字构成分词
CRF分词实例:
原始例句:我爱北京天安门
CRF标注后:我/S 爱/S 北/B 京/E 天/B 安/M 门/E
分词结果:我/爱/北京/天安门
CRF是一种判别式模型,CRF通过定义条件概率P(Y|X)来描述模型。基于CRF的分词方法,与传统的分类模型求解很相似,即给定feature(字级别的各种信息)输出label(词位)
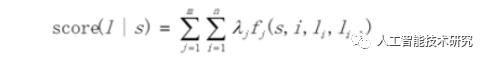
简单来说,分词所使用的是Linear-CRF,它由一组特征函数组成,包括权重和特征函数f,特征函数f的输入是整个句子s、当前posi、前一个词位Ii-1,当前词位Ii
3)、基于深度学习的端到端的分词方法
最近,基于深度神经网络的序列标注算法在词性标注、命名实体识别问题上取得了优秀的进展。词性标注、命名实体识别都属于序列标注问题,这些端到端的方法可以迁移到分词问题上,免去CRF的特征模板配置问题。但与所有深度学习的方法一样,它需要较大的训练语料才能体现优势。
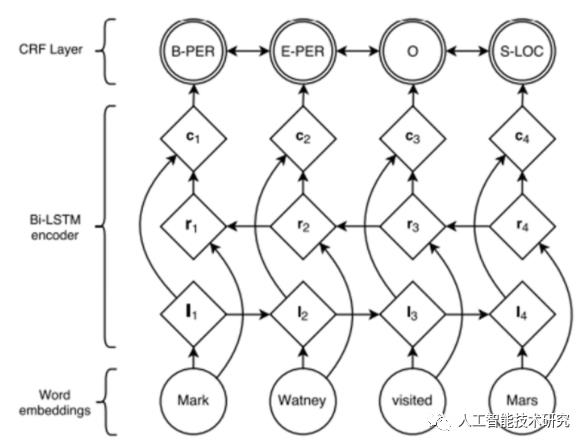
BiLSTM-CRF的网络结构如上图所示,输入层是一个embedding层,经过双向LSTM网络编码,输出层是一个CRF层。下图是BiLSTM-CRF各层的物理含义,可以看见经过双向LSTM网络输出的实际上是当前位置对于各词性的得分,CRF层的意义是对词性得分加上前一位置的词性概率转移的约束,其好处是引入一些语法规则的先验信息。
从数学公式的角度:
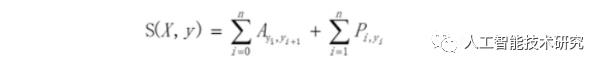
其中,A是词性的转移矩阵,P是BiLSTM网络的判别得分
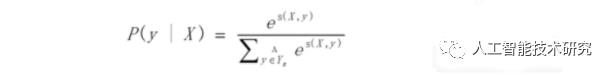
主要的分词工具
准确率中文分词评价指标
准确率
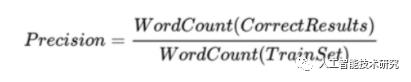
召回率
F值
结语
中文分词呈现两个发展趋势:
1、越来越多的Attention方法应用到中文分词上。
2、神经网络深入到NLP各个领域之中
3、数据科学与语言科学融合,发挥彼此优势。
以上是关于NLP | NLP基础之中文分词的主要内容,如果未能解决你的问题,请参考以下文章