数据挖掘干货总结--NLP基础
Posted 爱上终身学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘干货总结--NLP基础相关的知识,希望对你有一定的参考价值。
本文共计1463字,预计阅读时长八分钟
NLP-基础和中文分词
一、本质
NLP (Natural Language Processing) 自然语言处理是一门研究计算机处理人类语言的技术
二、NLP用来解决什么问题
语音合成(Speech synthesis)
语音识别(Speech recognition)
中文分词(Chinese word segmentation)☆
文本分类(Text categorization)☆
信息检索(Information retrieval)
问答系统(Question answering)
机器翻译(Machine translation)
自动摘要(Automatic summarization)
。。。
三、NLP基础
1.相似度度量
1)意义
计算个体间相似程度,是机器学习和数据挖掘的基础,作为评判个体间差异的大小
2)度量的方法
空间:欧氏距离
路径:曼哈顿距离
加权:标准化欧氏距离
编码差别:汉明距离
集合近似度:杰卡德类似系数与距离
相关:相关系数与相关距离
向量差距:夹角余弦(最常用的度量方法)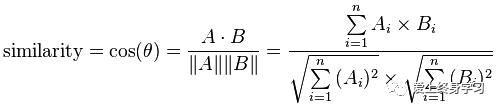
3)相似文本计算的流程
– 找出两篇文章的关键词;
– 每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中词的词频;
– 生成两篇文章各自的词频向量;
– 计算两个向量的余弦相似度,值越大就表示越相似。
2. TF-IDF词频与反文档频率
1)意义
找出文章中重要性最高的词,是自动摘要、推荐算法等技术的基础
2)概念
仅仅用词频TF,并不能表明一个词的重要性,还要综合考虑每个词的权重,因此需要计算IDF。TF*IDF可以有效地表示一个词对文章的重要性。

3)相似文章计算的流程
– 使用TF-IDF算法,找出两篇文章的关键词;
– 每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
– 生成两篇文章各自的词频向量;
– 计算两个向量的余弦相似度,值越大就表示越相似。
4)生成自动摘要的流程
– 使用TF-IDF算法,找出文章的关键词;
– 过滤掉停用词后排序;
– 将文章分成句子/簇;
– 计算每个句子/簇的重要性;
– 将重要性最高的句子/簇组合,生成摘要。
3. LCS最长公共子序列(Longest Common Subsequence)
1)意义
即找出两个序列中最长的公共子序列,广泛的应用在图形相似处理、媒体流的相似比较、计算生物学方面
2)算法——动态规划
①如果xm = yn(最后一个字符相同),则:Xm与Yn的最长公共子序列LCS(Xm,Yn)的最后一个字符必定为xm(=yn)
②如果xm ≠ yn,则LCS(Xm,Yn) = max{LCS(Xm−1,Yn), LCS(Xm, Yn−1)}
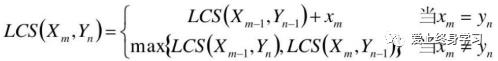
③创建一个二维数组C[m,n],用C[i,j]记录序列Xi和Yj的最长公共子序列的长度
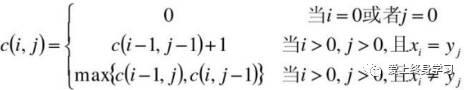
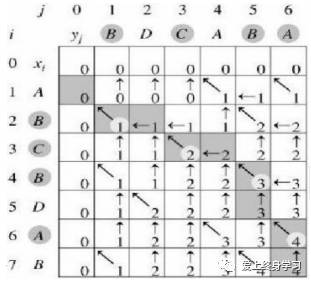
④那么对于两个序列:X =<A, B, C, B, D, A, B>和Y=<B, D, C, A, B, A>,可以通过如下二维数组求出LCS的长度
4. 中文分词☆
1)意义
自然语言处理中,与英文不同,中文词之间没有空格。所以为了实现机器对中文数据的处理,多了一项很重要的任务——中文分词。
2)方法:基于词典匹配的最大长度查找(有前向查找和后向查找两种)
+
数据结构:Trie树(单词查找树,字典树),明显提高查找效率
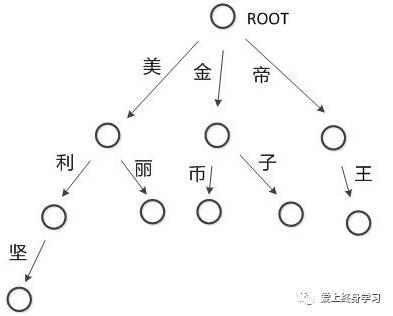
3)工具:Jieba分词(下一篇详细介绍)
4)概率语言模型:
概率语言模型的任务是:在全切分所得的所有结果中求某个切分方案S,使得P(S)最大。
#STEP1
从统计思想的角度来看,分词问题的输入是一个字串C=c1,c2……cn ,输出是一个词串S=w1,w2……wm ,其中m<=n。对于一个特定的字符串C,会有多个切分方案S对应,分词的任务就是在这些S中找出一个切分方案S,使得P(S|C)的值最大。
P(S|C)就是由字符串C产生切分S的概率,也就是对输入字符串切分出最有可能的词序列,基于贝叶斯公式可以得到如下推论:
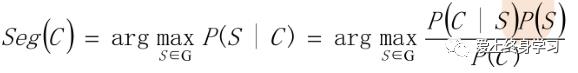
转换的精髓:
#STEP2
• P(C)只是一个用来归一化的固定值
• 从词串恢复到汉字串的概率只有唯一的一种方式,所以P(C|S)=1。
• 所以:比较P(S1|C)和P(S2|C)的大小变成比较P(S1)和P(S2) 的大小
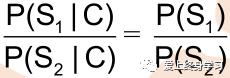
#STEP3
• 为了容易实现,假设每个词之间的概率是上下文无关的(注释)
• 最后算 logP(w),取log是为了防止向下溢出,如果一个数太小,10^-30可能会向下溢出。
• 如果这些对数值事前已经算出来了,则结果直接用加法就可以得到,而加法比乘法速度更快
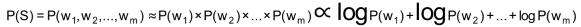
注:
***N元模型***
在此,需要引入一个N元模型的概念:前后两词出现概率并不是相互独立的,严格意义上:
P(w1,w2)= P(w1)P(w2|w1)
P(w1,w2,w3)= P(w1,w2)P(w3|w1,w2)
那么
P(w1,w2,w3)= P(w1)P(w2|w1)P(w3|w1,w2)
所以
P(S)=P(w1,w2,...,wn)= P(w1)P(w2|w1)P(w3|w1,w2)…P(wn|w1w2…wn-1)
这个式子叫做概率的链规则
显然这个式子不好求解,需要进行简化:
① 如果简化成一个词的出现仅依赖于它前面出现的一个词,那么就称为二元模型(Bigram)
P(S) = P(w1,w2,...,wn)≈P(w1) P(w2|w1)P(w3|w2)…P(wn|wn-1)
② 如果简化成一个词的出现仅依赖于它前面出现的两个词,就称之为三元模型(Trigram)。
③ 如果一个词的出现不依赖于它前面出现的词,叫做一元模型(Unigram)。
P(S)=P(w1,w2,...,wn)= P(w1)P(w2)P(w3)…P(wn)
以上。
祝大家圣诞快乐
听说,爱点赞的人运气都不会太差哦
如果有任何意见和建议,也欢迎在下方留言~
点击这里查看往期精彩内容:
以上是关于数据挖掘干货总结--NLP基础的主要内容,如果未能解决你的问题,请参考以下文章