数据分析应用之-二叉树算法的应用
Posted 云导师在线辅导平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析应用之-二叉树算法的应用相关的知识,希望对你有一定的参考价值。
点击蓝字
上节我们对论文中二叉树算法的概念以及优缺点进行了介绍,这一节就让我们具体介绍其应用过程吧。
数据集介绍
1936年费希尔收集了三种鸢尾花(分别标记为setosa(山鸢尾)、versicolor(变色鸢尾)和virginica(维吉尼亚鸢尾))的花萼和花瓣数据。包括花萼的长度和宽度,以及花瓣的长度和宽度。改数据包为iris,共包含150条数据。
从照片来看,三者没有区别。但是内在是有区别的。
我们将根据这四个特征来建立支持向量机模型从而实现对鸢尾花的分类判别任务。如下图所示:iris数据集中更有三种品种的鸢尾,蓝色为山鸢尾、粉色为变色鸢尾,绿色为维吉尼亚鸢尾。
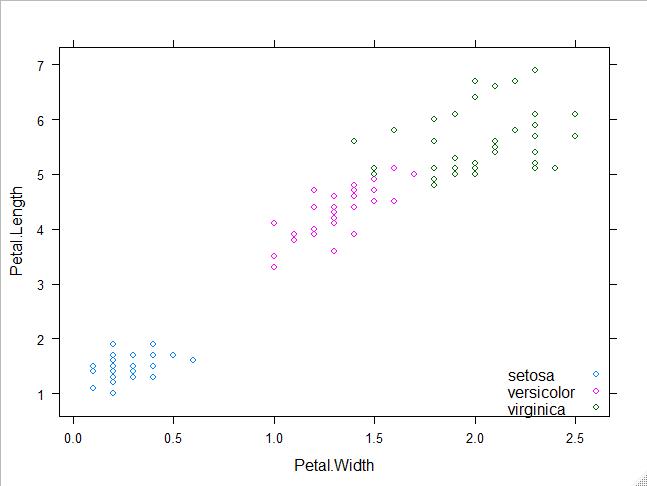
图2-2:iris数据集鸢尾花分类
代码运行
初始设置
set.seed(1)
data= iris[sample(1:nrow(iris)),] #一步打乱数据(重排序)。
data[,1:4] = apply(data[,1:4],2,scale)#apply函数 把一个function作用到array或者matrix的margins(可以理解为数组的每一行或者每一列)中,返回值时vector、array、list。
is= sample(1:nrow(iris), 100)# 将1到150随机打乱,并取前一百个数。
train=data[is,]#取一百个数的对应的数据为训练集。
test=data[-is,]#取剩下的50个为测试集
test.x= test[,1:4]#提取出测试集前四列的特征(花萼长、宽和花瓣的长、宽)作为预测时的输入。
test.y= test[,5]#提取测试集真实的分类结果。
library(tree)#R语言中决策树算法需要用到tree包,此处需要加载tree包
tm1= tree(Species~., train, split='gini')#调用tree函数
plot(tm1)#根据模型拟合结果画出决策树的线,注意这里显示的是只有线的图,没有文字。
text(tm1)#为决策树添加上条件。
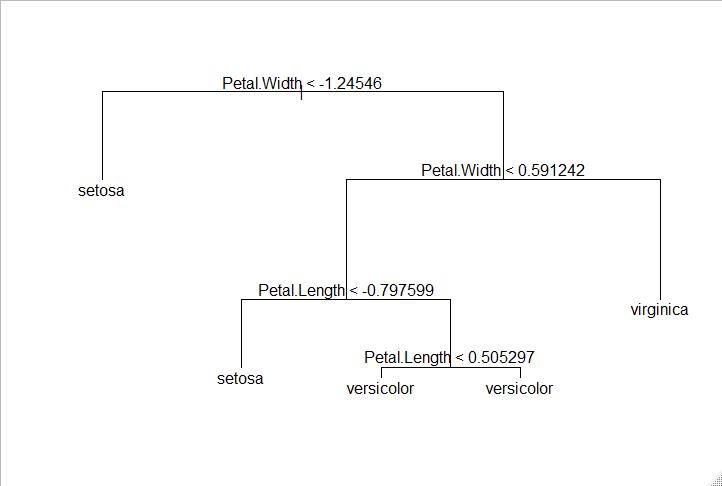
tm1.p = predict(tm1, test.x, type='class')#通过上述得到的决策树模型对测试集进行预测。
(tb = table(tm1.p, test.y))#输出预测结果与真实测试集的分类结果的对比。
test.y
tm1.p setosa versicolor virginica
setosa 16 0 0
versicolor 0 16 2
virginica 0 2 14
#由上述结果可以发现,50个预测值中四个预测错误。
sum(diag(tb))/sum(tb)#输出精确度
[1] 0.92
#上述结果表明当终端节点数为5时,tm1决策树模型的精确度为0.92。
#如果你现在有少量鸢尾花的花瓣长宽和花萼长宽的数据,可以直接通过上面决策树进行判断分类,不需要通过计算机等进行预测,这是决策树算法的一个独特鲜明的优点之一。
一个基础的决策树基本完成了,由于iris数据集简单,所以暂不需要剪枝(R语言中剪枝需要prune.tree()函数)等操作,在实际生活的应用中,终端结点的个数往往会需要很多,一般选取K-flod交叉验证与剪枝操作,对决策树进行适当的修剪。


推荐阅读

云导师在线辅导平台
更多学术资讯

以上是关于数据分析应用之-二叉树算法的应用的主要内容,如果未能解决你的问题,请参考以下文章