Vision MLP之RaftMLP Do MLP-based Models Dream of Winning Over Computer Vision
Posted 随想中的生活
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Vision MLP之RaftMLP Do MLP-based Models Dream of Winning Over Computer Vision相关的知识,希望对你有一定的参考价值。
RaftMLP: Do MLP-based Models Dream of Winning Over Computer Vision?
原始文档:https://www.yuque.com/lart/papers/kv3f2e

从摘要理解论文
For the past ten years, CNN has reigned supreme in the world of computer vision, but recently, Transformer is on the rise. However, the quadratic computational cost of self-attention has become a severe problem of practice.
这里指出了 self-attention 结构较高的计算成本。
There has been much research on architectures without CNN and self-attention in this context. In particular, MLP-Mixer is a simple idea designed using MLPs and hit an accuracy comparable to the Vision Transformer.
引出本文的核心,MLP 架构。
However, the only inductive bias in this architecture is the embedding of tokens.
在 MLP 架构中,唯一引入归纳偏置的位置也就是 token 嵌入的过程。
这里提到归纳偏置在我看来主要是为了向原始的纯 MLP 架构中引入更多的归纳偏置来在视觉任务上实现更好的训练效果。估计本文又要从卷积架构中借鉴思路了。
Thus, there is still a possibility to build a non-convolutional inductive bias into the architecture itself, and we built in an inductive bias using two simple ideas.
这里主要在强调虽然引入了归纳偏置,但并不是通过卷积结构引入的。那就只能通过对运算过程进行约束来实现了。
- A way is to divide the token-mixing block vertically and horizontally.
- Another way is to make spatial correlations denser among some channels of token-mixing.
这里又一次出现了使用垂直与水平方向对计算进行划分的思路。类似的思想已经出现在很多方法中,例如:
- 卷积方法
- Axial-Attention Transformer 方法
- Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
- CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows
- MLP 方法
- Hire-MLP: Vision MLP via Hierarchical Rearrangement
这里的第二点暂时不是太直观,看起来是对通道 MLP 进行了改进?——从正文来看,是在沿着轴向处理时,同时整合了多个通道的信息。
With this approach, we were able to improve the accuracy of the MLP-Mixer while reducing its parameters and computational complexity.
毕竟因为分治的策略,将原本凑在一起计算的全连接改成了沿特定轴向的级联处理。
粗略来看,这使得运算量近似从 \\(O(2(HW)^2)\\) 变成了 \\(O(H^2) + O(W^2)\\)。
Compared to other MLP-based models, the proposed model, named RaftMLP has a good balance of computational complexity, the number of parameters, and actual memory usage. In addition, our work indicates that MLP-based models have the potential to replace CNNs by adopting inductive bias. The source code in PyTorch version is available at https://github.com/okojoalg/raft-mlp.
主要内容
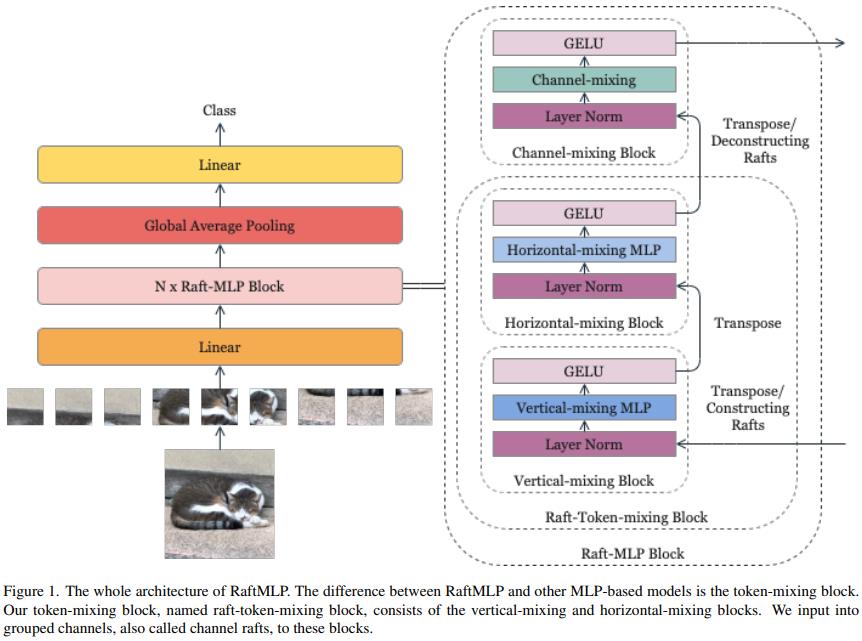
可以看到,实际上还是可以看作是对空间 MLP 的调整。
这里将原始的空间与通道 MLP 交叉堆叠的结构修改为了垂直、水平、通道三个级联的结构。通过这样的方式,作者们期望可以引入垂直和水平方向上的属于 2D 图像的有意义的归纳偏置,隐式地假设水平或者垂直对齐的 patch 序列有着和 其他的水平或垂直对齐的 patch 序列 有着相似的相关性。
此外,在输入到垂直混合块和水平混合块之前,一些通道被连接起来,它们被这两个模块共享。这样做是因为作者们假设某些通道之间存在几何关系(后文将整合得到的这些通道称作Channel Raft,并且假定的是特定间隔 \\(r\\) 的通道具有这样的关系)。
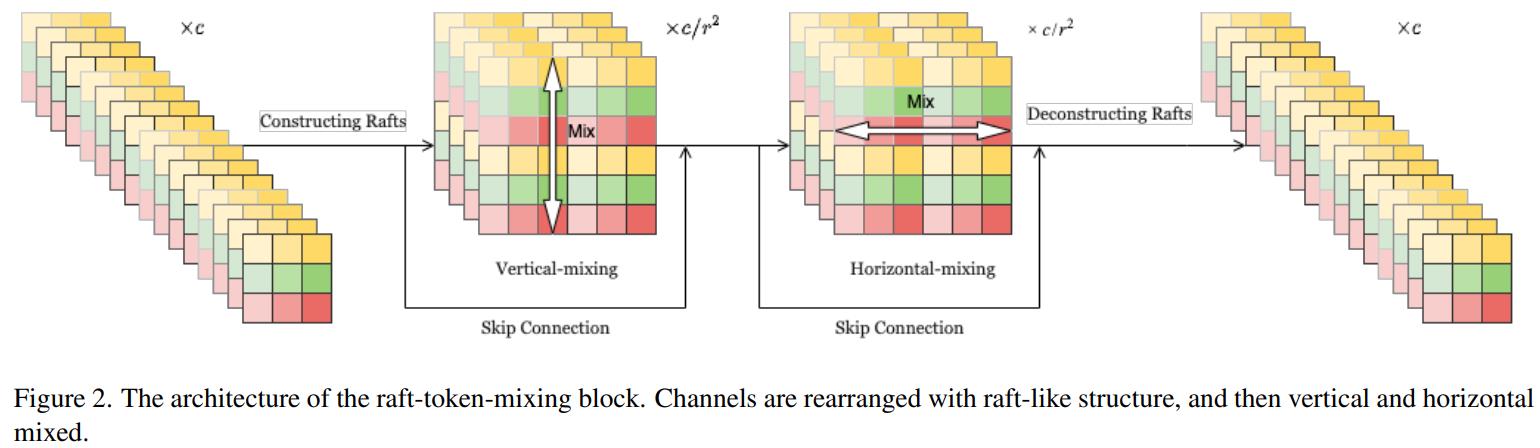
Vertical-Mixing Block 的索引形式变化过程:((rh*rw*sr,h,w) -> (sr, rh*h, rw*w) <=> (rw*sr*w, rh*h) (因为这里是通道和水平方向共享,所以可以等价,而图中绘制的是等价符号左侧的形式),Horizontal-Mixing Block 类似。
针对水平和垂直模块构成的 Raft-Token-Mixing Block,作者给出的代码示例和我上面等式中等价符号右侧内容一致。从代码中可以看到,其中的归一化操作不受通道分组的影响,而直接对原始形式的特征的通道处理。
class RaftTokenMixingBlock(nn.Module):
# b: size of mini -batch, h: height, w: width,
# c: channel, r: size of raft (number of groups), o: c//r,
# e: expansion factor,
# x: input tensor of shape (h, w, c)
def __init__(self):
self.lnv = nn.LayerNorm(c)
self.lnh = nn.LayerNorm(c)
self.fnv1 = nn.Linear(r * h, r * h * e)
self.fnv2 = nn.Linear(r * h * e, r * h)
self.fnh1 = nn.Linear(r * w, r * w * e)
self.fnh2 = nn.Linear(r * w * e, r * w)
def forward(self, x):
"""
x: b, hw, c
"""
# Vertical-Mixing Block
y = self.lnv(x)
y = rearrange(y, \'b (h w) (r o) -> b (o w) (r h)\')
y = self.fcv1(y)
y = F.gelu(y)
y = self.fcv2(y)
y = rearrange(y, \'b (o w) (r h) -> b (h w) (r o)\')
y = x + y
# Horizontal-Mixing Block
y = self.lnh(y)
y = rearrange(y, \'b (h w) (r o) -> b (o h) (r w)\')
y = self.fch1(y)
y = F.gelu(y)
y = self.fch2(y)
y = rearrange(y, \'b (o h) (r w) -> b (h w) (r o)\')
return x + y
对于提出的结构,通过选择合适的 \\(r\\) 可以让最终的 raft-token-mixing 相较于原始的 token-mixing block 具有更少的参数(\\(r<h\'/\\sqrt{2}\\)),更少的 MACs(multiply-accumulate)(\\(r<h\'/2^{\\frac{1}{4}}\\))。这里假定 \\(h\'=w\'\\),并且 token-mixing block 中同样使用膨胀参数 \\(e\\)。
实验结果
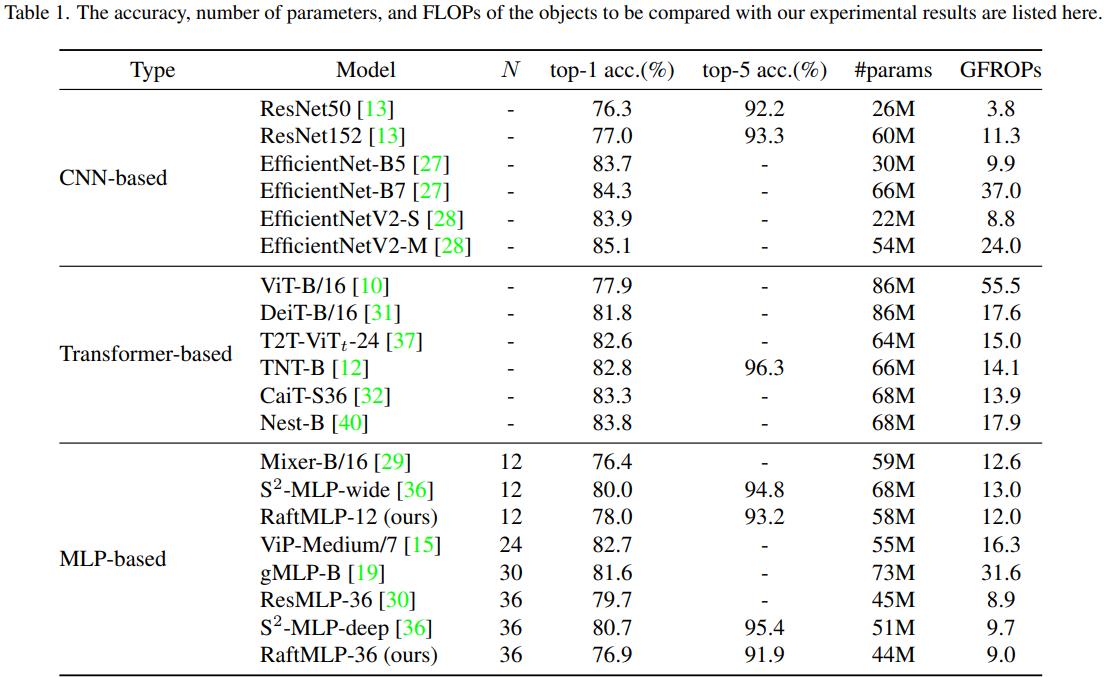
这里的中,由于模型设定的原因,RaftMLP-12 主要和 Mixer-B/16 和 ViT-B/16 对比。而 RaftMLP-36 则主要和 ResMLP-36 对比。
Although RaftMLP-36 has almost the same parameters and number of FLOPs as ResMLP-36, it is not more accurate than ResMLP-36. However, since RaftMLP and ResMLP have different detailed architectures other than the raft-token-mixing block, the effect of the raft-token-mixing block cannot be directly compared, unlike the comparison with MLP-Mixer. Nevertheless, we can see that raft-token-mixing is working even though the layers are deeper than RaftMLP-12. (关于最后这个模型 36 的比较,我也没看明白想说个啥,层数更多难道 raft-token-mixing 可能就不起作用了?)
一些扩展与畅想
- token-mixing block 可以扩展到 3D 情形来替换 3D 卷积。这样可以用来处理视频。
- 本文进引入了水平和垂直的空间归纳偏置,以及一些通道的相关性的约束。但是作者也提到,还可以尝试利用其他的归纳偏置:例如平行不变性(parallel invariance,这个不是太明白),层次性(hierarchy)等。
链接
Vision MLP 之 S2-MLP V1&V2 : Spatial-Shift MLP Architecture for Vision
Vision MLP 之 S2-MLP V1&V2 : Spatial-Shift MLP Architecture for Vision
原始文档:https://www.yuque.com/lart/papers/dgdu2b


这里将会总结关于 S2-MLP 的两篇文章。这两篇文章核心思路是一样的,即基于空间偏移操作替换空间 MLP。
从摘要理解文章
V1
Recently, visual Transformer (ViT) and its following works abandon the convolution and exploit the self-attention operation, attaining a comparable or even higher accuracy than CNNs. More recently, MLP-Mixer abandons both the convolution and the self-attention operation, proposing an architecture containing only MLP layers.
To achieve cross-patch communications, it devises an additional token-mixing MLP besides the channel-mixing MLP. It achieves promising results when training on an extremely large-scale dataset. But it cannot achieve as outstanding performance as its CNN and ViT counterparts when training on medium-scale datasets such as ImageNet1K and ImageNet21K. The performance drop of MLP-Mixer motivates us to rethink the token-mixing MLP.
这里引出了本文的主要内容,即改进空间 MLP。
We discover that the token-mixing MLP is a variant of the depthwise convolution with a global reception field and spatial-specific configuration. But the global reception field and the spatial-specific property make token-mixing MLP prone to over-fitting.
指出了空间 MLP 的问题,由于其全局感受野和空间特定的属性使得模型容易过拟合。
In this paper, we propose a novel pure MLP architecture, spatial-shift MLP (S2-MLP). Different from MLP-Mixer, our S2-MLP only contains channel-mixing MLP.
这里提到仅有通道 MLP,说明想到了新的办法来扩张通道 MLP 的感受野还可以保留点运算。
We utilize a spatial-shift operation for communications between patches. It has a local reception field and is spatial-agnostic. It is parameter-free and efficient for computation.
引出本文的核心内容,也就是标题中提到的空间偏移操作。看上去这一操作不带参数,仅仅是用来调整特征的一个处理手段。
Spatial-Shift 操作可以参考这里的几篇文章:https://www.yuque.com/lart/architecture/conv#i8nnp
The proposed S2-MLP attains higher recognition accuracy than MLP-Mixer when training on ImageNet-1K dataset. Meanwhile, S2-MLP accomplishes as excellent performance as ViT on ImageNet-1K dataset with considerably simpler architecture and fewer FLOPs and parameters.
V2
Recently, MLP-based vision backbones emerge. MLP-based vision architectures with less inductive bias achieve competitive performance in image recognition compared with CNNs and vision Transformers. Among them, spatial-shift MLP (S2-MLP), adopting the straightforward spatial-shift operation, achieves better performance than the pioneering works including MLP-mixer and ResMLP. More recently, using smaller patches with a pyramid structure, Vision Permutator (ViP) and Global Filter Network (GFNet) achieve better performance than S2-MLP.
这里引出了金字塔结构,看来 V2 版本要使用类似的构造。
In this paper, we improve the S2-MLP vision backbone. We expand the feature map along the channel dimension and split the expanded feature map into several parts. We conduct different spatial-shift operations on split parts.
依然延续了空间偏移的策略,但是不知道相较于 V1 版本改动如何
Meanwhile, we exploit the split-attention operation to fuse these split parts.
这里还引入了 split-attention(ResNeSt)来融合分组。难道这里是要使用并行分支?
Moreover, like the counterparts, we adopt smaller-scale patches and use a pyramid structure for boosting the image recognition accuracy.
We term the improved spatial-shift MLP vision backbone as S2-MLPv2. Using 55M parameters, our medium-scale model, S2-MLPv2-Medium achieves an 83.6% top-1 accuracy on the ImageNet-1K benchmark using 224×224 images without self-attention and external training data.
在我看来,V2 相较于 V1,主要是借鉴了 CycleFC 的一些想法,并进行了适应性的调整。整体改动有两方面:
- 引入多分支处理的思想,并应用 Split-Attention 来融合不同分支。
- 受现有工作的启发,使用更小的 patch 和分层金字塔结构。
主要内容
核心结构比较
V1 中,整体流程延续的是 MLP-Mixer 的思路,仍然保持直筒状结构。
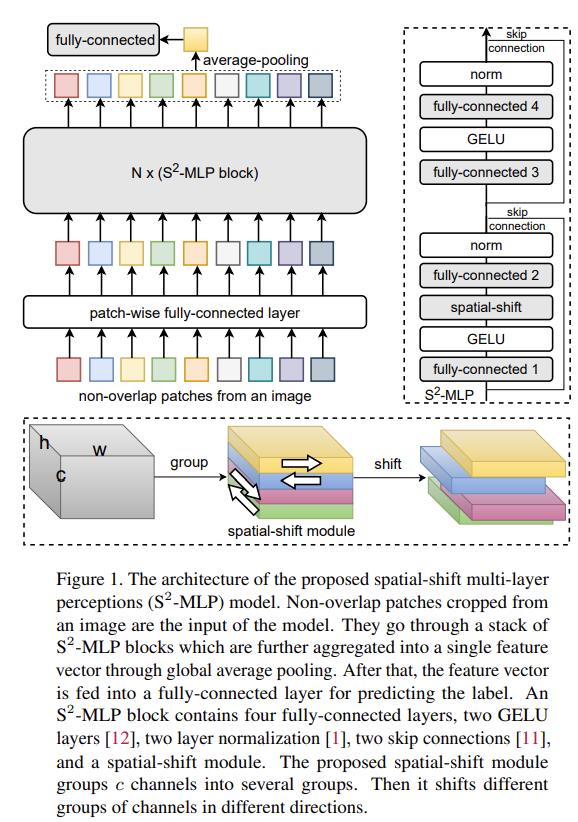
MLP-Mixer 的结构图:
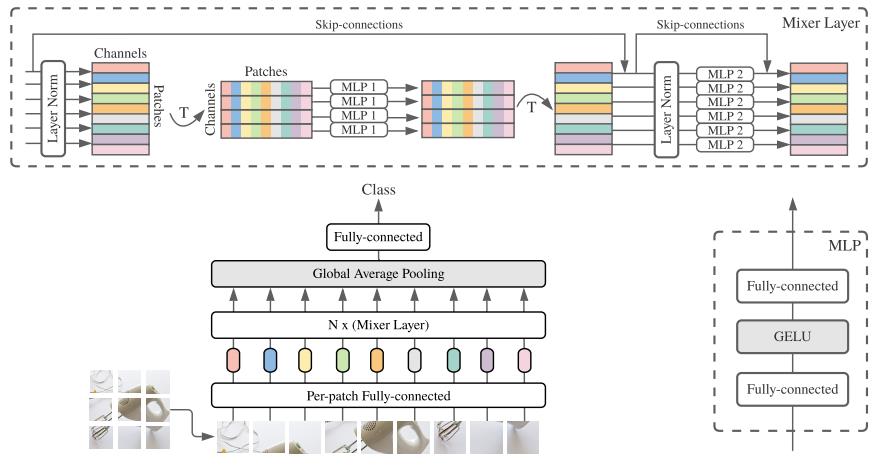
从图中可以看到,不同于 MLP-Mixer 中的 Pre-Norm 结构,S2MLP 使用的是 Post-Norm 结构。
另外,S2MLP 的改动主要集中在空间 MLP 的位置,由原来的Spatial-MLP(Linear->GeLU->Linear)转变为Spatial-Shifted Channel-MLP(Linear->GeLU->Spatial-Shift->Lienar)。
关于空间偏移的核心伪代码如下:

可以看到,这里就是将输入划分成四个不同的分组,各自沿着不同的轴向(H 和 W 轴)偏移,由于实现的原因,在边界部分会有重复值出现。分组数依赖于方向的数量,这里默认使用 4,即向四个方向偏移。
虽然从单个空间偏移模块上来看,仅仅关联了相邻的 patch,但是从整体堆叠后的结构来看,可以实现一个近似的长距离交互过程。
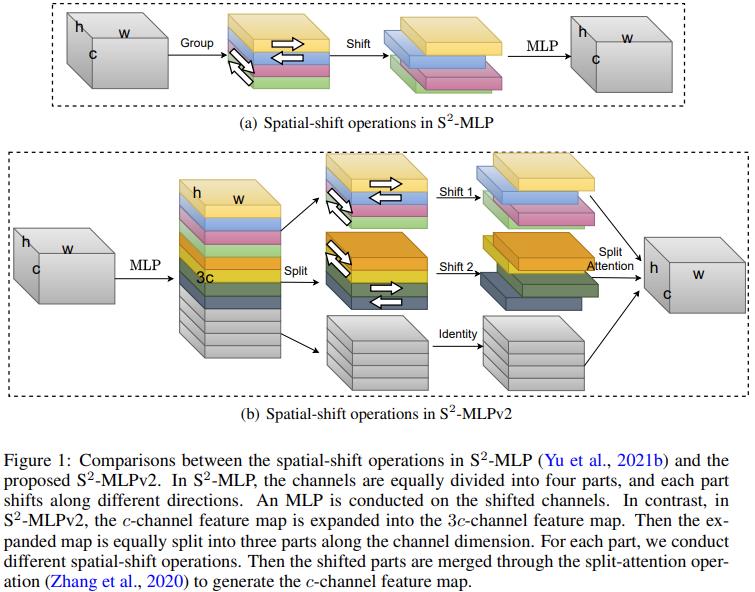
而在 V2 版本相较于 V1 版本引入了多分支处理的策略,并且在结构上开始使用 Pre-Norm 形式。
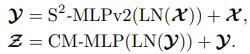
关于多分支结构的构造思路与 CycleFC 非常类似。不同支路使用不同的处理策略,同时在多分支整合时,使用了 Split-Attention 的方式进行融合。
Split-Attention: Vision Permutator (Hou et al., 2021) adopts split attention proposed in ResNeSt (Zhang et al., 2020) for enhancing multiple feature maps from different operations. 本文借鉴使用来融合多分支。
主要操作过程:
- 输入 \\(K\\) 个特征图(可以来自不同分支)\\(\\mathbf{X} = \\{X_k \\in \\mathbb{R}^{N \\times C}\\}^{K}_{k=1}, \\, N=HW\\)
- 将所有特诊图的列求和后的结果累加:\\(a \\in \\mathbb{R}^{C} = \\sum_{k=1}^{K}\\sum_{n=1}^{N}\\mathbf{X}_{k}[n, :]\\)
- 通过堆叠的全连接层进行变换,得到针对不同特征图的通道注意力 logits:\\(\\hat{a} \\in \\mathbb{R}^{KC} = \\sigma(a W_1) W_2, \\, W_1 \\in \\mathbb{R}^{C \\times \\bar{C}}, \\, W_2 \\in \\mathbb{R}^{\\bar{C} \\times KC}\\)
- 使用 reshape 来调整注意力向量的形状:\\(\\hat{a} \\in \\mathbb{R}^{KC} \\rightarrow \\hat{A} \\in \\mathbb{R}^{K \\times C}\\)
- 使用 softmax 沿着索引 \\(k\\) 计算,来获得针对不同样本的归一化注意力权重:\\(\\bar{A}[:, c] \\in \\mathbb{R}^{K} = \\text{softmax}(\\hat{A}[:, c])\\)
- 对输入的 \\(K\\) 个特征图加权求和得到结果 \\(Y\\),其一行的结果可以表示为:\\(Y[n, :] \\in \\mathbb{R}^{C} = \\sum_{k=1}^{K} X_{k}[n, :] \\odot \\bar{A}[k, :]\\)
不过需要注意的是,这里第三个分支是一个恒等分支,直接将输入的部分通道取了过来,这一点延续了 GhostNet 的想法,而不同于 CycleFC,使用的是一个独立的通道 MLP。
GhostNet的核心结构:
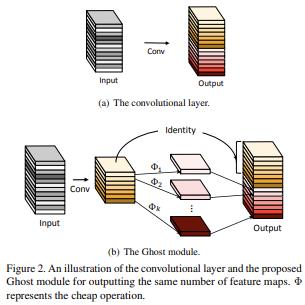
关于该多分支结构的核心伪代码如下:
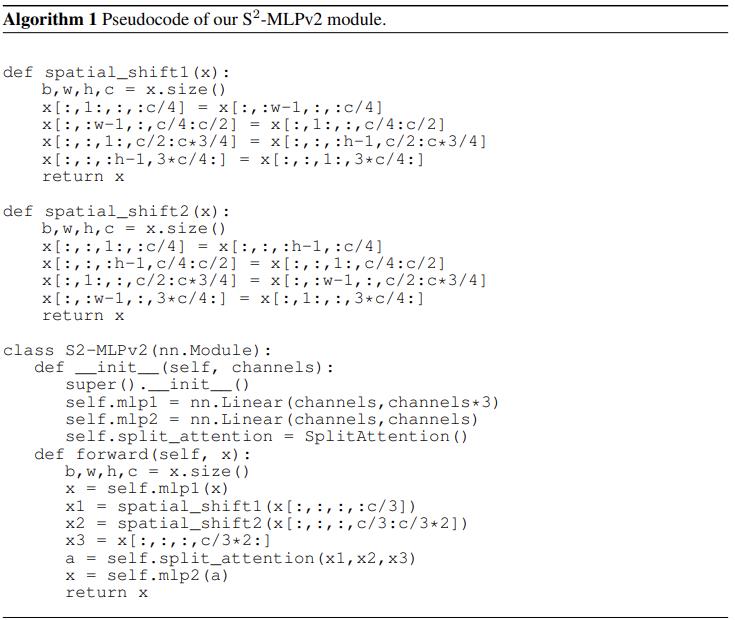
其他细节
Spatial-Shift 与 Depthwise Convolution 的关系

实际上,四个方向的偏移都是可以通过特定的卷积核构造来实现的:
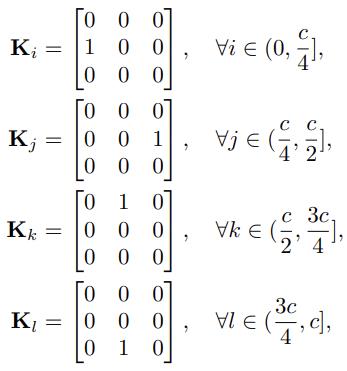
所以分组空间偏移操作可以通过为 Depthwise Convolution 的不同分组指定对应上面的卷积核来实现。
实际上实现偏移的方法非常多,除了文中提到的切片索引和构造核的 depthwise convolution 的方式,还可以通过分组torch.roll和自定义 offset 的deform_conv2d来实现。
import torch
import torch.nn.functional as F
from torchvision.ops import deform_conv2d
xs = torch.meshgrid(torch.arange(5), torch.arange(5))
x = torch.stack(xs, dim=0)
x = x.unsqueeze(0).repeat(1, 4, 1, 1).float()
direct_shift = torch.clone(x)
direct_shift[:, 0:2, :, 1:] = torch.clone(direct_shift[:, 0:2, :, :4])
direct_shift[:, 2:4, :, :4] = torch.clone(direct_shift[:, 2:4, :, 1:])
direct_shift[:, 4:6, 1:, :] = torch.clone(direct_shift[:, 4:6, :4, :])
direct_shift[:, 6:8, :4, :] = torch.clone(direct_shift[:, 6:8, 1:, :])
print(direct_shift)
pad_x = F.pad(x, pad=[1, 1, 1, 1], mode="replicate") # 这里需要借助padding来保留边界的数据
roll_shift = torch.cat(
[
torch.roll(pad_x[:, c * 2 : (c + 1) * 2, ...], shifts=(shift_h, shift_w), dims=(2, 3))
for c, (shift_h, shift_w) in enumerate([(0, 1), (0, -1), (1, 0), (-1, 0)])
],
dim=1,
)
roll_shift = roll_shift[..., 1:6, 1:6]
print(roll_shift)
k1 = torch.FloatTensor([[0, 0, 0], [1, 0, 0], [0, 0, 0]]).reshape(1, 1, 3, 3)
k2 = torch.FloatTensor([[0, 0, 0], [0, 0, 1], [0, 0, 0]]).reshape(1, 1, 3, 3)
k3 = torch.FloatTensor([[0, 1, 0], [0, 0, 0], [0, 0, 0]]).reshape(1, 1, 3, 3)
k4 = torch.FloatTensor([[0, 0, 0], [0, 0, 0], [0, 1, 0]]).reshape(1, 1, 3, 3)
weight = torch.cat([k1, k1, k2, k2, k3, k3, k4, k4], dim=0) # 每个输出通道对应一个输入通道
conv_shift = F.conv2d(pad_x, weight=weight, groups=8)
print(conv_shift)
offset = torch.empty(1, 2 * 8 * 1 * 1, 1, 1)
for c, (rel_offset_h, rel_offset_w) in enumerate([(0, -1), (0, -1), (0, 1), (0, 1), (-1, 0), (-1, 0), (1, 0), (1, 0)]):
offset[0, c * 2 + 0, 0, 0] = rel_offset_h
offset[0, c * 2 + 1, 0, 0] = rel_offset_w
offset = offset.repeat(1, 1, 7, 7).float()
weight = torch.eye(8).reshape(8, 8, 1, 1).float()
deconv_shift = deform_conv2d(pad_x, offset=offset, weight=weight)
deconv_shift = deconv_shift[..., 1:6, 1:6]
print(deconv_shift)
"""
tensor([[[[0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.]],
[[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.]],
[[0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.]],
[[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.]],
[[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.]],
[[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.]],
[[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.],
[4., 4., 4., 4., 4.]],
[[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.]]]])
tensor([[[[0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.]],
[[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.]],
[[0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.]],
[[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.]],
[[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.]],
[[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.]],
[[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.],
[4., 4., 4., 4., 4.]],
[[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.]]]])
tensor([[[[0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.]],
[[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.]],
[[0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.]],
[[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.]],
[[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.]],
[[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.]],
[[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.],
[4., 4., 4., 4., 4.]],
[[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.]]]])
tensor([[[[0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.]],
[[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.],
[0., 0., 1., 2., 3.]],
[[0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.]],
[[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.],
[1., 2., 3., 4., 4.]],
[[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.]],
[[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.]],
[[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.],
[4., 4., 4., 4., 4.]],
[[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.]]]])
"""
偏移方向的影响

实验是在 ImageNet 的子集上跑的。
V1 中针对不同的偏移方向进行了消融实验,这里的模型中都是按照方向个数对通道分组。从结果中可以看到:
- 偏移确实可以带来性能增益。
- a 和 b:四个方向和八个方向相比,差异并不大。
- e 和 f:水平偏移效果更好。
- c 和 e/f:两个轴的偏移要好于单个轴的偏移。
输入尺寸以及 patchsize 的影响
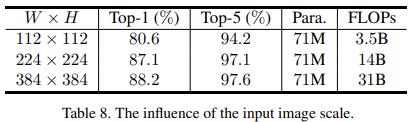
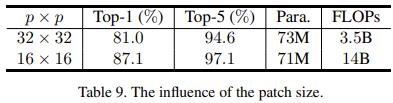
实验是在 ImageNet 的子集上跑的。
V1 中在固定 patchsize 后,不同的输入尺寸 WxH 的表现也不同。过大的 patchsize 效果也不好,会丢失更多的细节信息,但是却可以有效提升推理速度。
金字塔结构的有效性
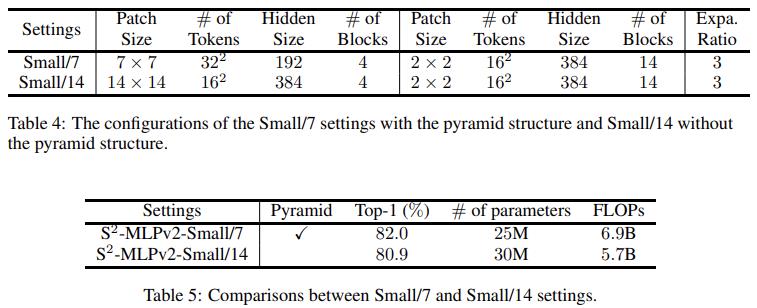
V2 中,构造了两个不同的结构,一个有着更小的 patch,并且使用金字塔结构,另一个更大的 patch,不使用金字塔结构。可以看到,同时受益于小 patchsize 带来的细节信息的性能增强和金字塔结构带来的更优的计算效率,前者获得了更好的表现。
Split-Attention 的效果

V2 将 split-attention 与特征直接相加取平均对比。可以看到,前者更优。不过这里参数量也不一样了,其实更合理的比较应该最起码是加几层带参数的结构来融合三分支的特征。
三分支结构的有效性
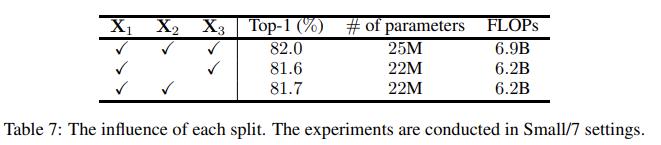
这里的实验说明有些模糊,作者说道“In this section, we evaluate the influence of removing one of them.”但是却没有说明去掉特定分支后其他结构的调整方式。
实验结果
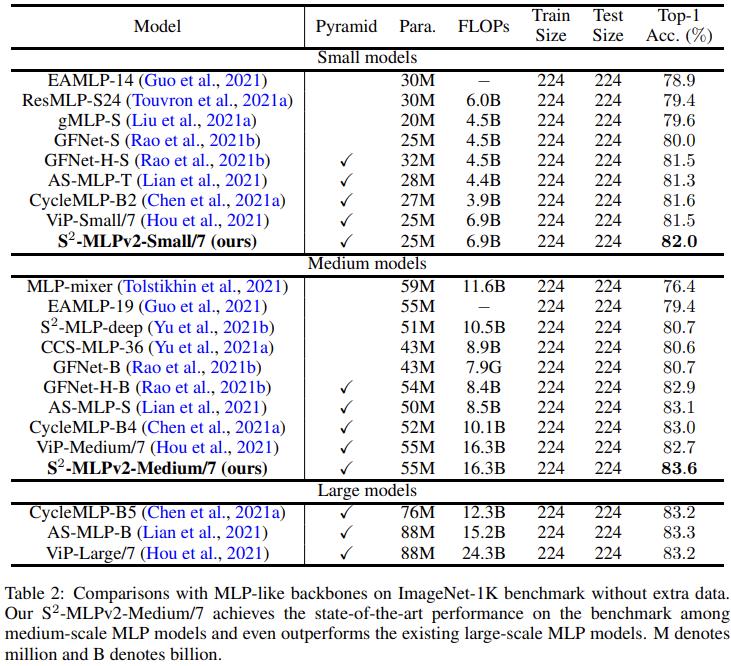
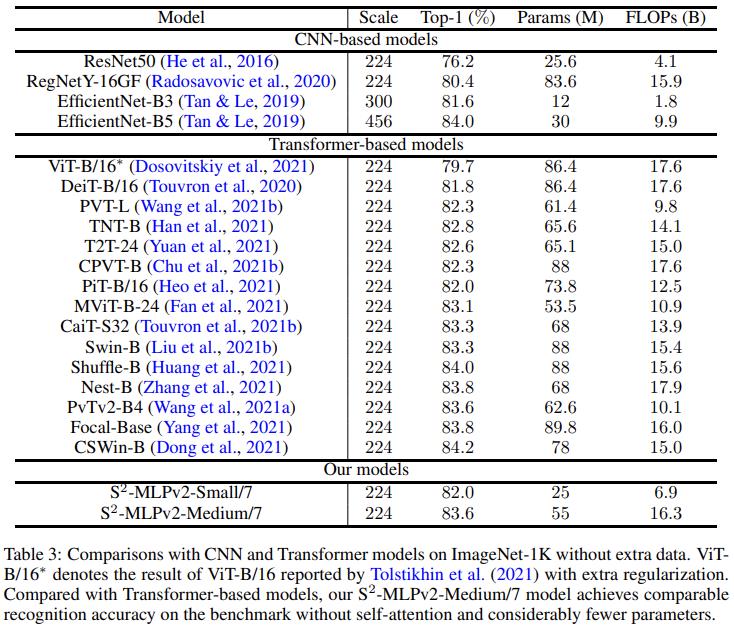
实验结果直接看 V2 论文的表格即可:
链接
- 论文:
- 参考代码:
- CycleFC 的代码有可以借鉴之处: https://github.com/ShoufaChen/CycleMLP/blob/main/cycle_mlp.py
以上是关于Vision MLP之RaftMLP Do MLP-based Models Dream of Winning Over Computer Vision的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读笔记:Hire-MLP Vision MLP via Hierarchical Rearrangement
论文阅读笔记:AS-MLP AN AXIAL SHIFTED MLP ARCHITECTUREFOR VISION
gluon 实现多层感知机MLP分类FashionMNIST
Pytorch CIFAR10图像分类 Vision Transformer(ViT) 篇