论文阅读笔记:AS-MLP AN AXIAL SHIFTED MLP ARCHITECTUREFOR VISION
Posted GrinchWu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读笔记:AS-MLP AN AXIAL SHIFTED MLP ARCHITECTUREFOR VISION相关的知识,希望对你有一定的参考价值。
1.摘要
本文提出了一种轴向移位的MLP体系结构(AS-MLP),更关注局部特征的交互,通过特征图的通道轴移动,AS-MLP能够从不同的轴获取信息,这使得网络能够捕捉局部依赖(可以理解为cnn的空间不变性),这样的操作使我们能够利用一个纯的MLP体系结构来实现与cnn类体系结构相同的局部感受野。我们也可以设计AS-MLP的感受野的大小和块的拓展。本文提出的AS-MLP架构在ImageNet-1K数据集上的表现优于所有基于MLP的架构,并且与基于transformer相比即使FLOPs稍低,也能获得具有竞争力的性能。此外,AS-MLP也是第一个应用于下游任务(如对象检测和语义分割)的基于mlp的体系结构。
2.引入
-
动机
- 最近,Tolstikhin等人(2021)首先提出了基于MLP的架构,其中几乎所有的网络参数都是从MLP(线性层)学习而来的。它取得了惊人的结果,可与cnn类模型相媲美。这些有希望的结果推动了我们对基于mlp架构的探索。
- MLP-Mixer 很少能充分利用局部信息,这在类cnn架构中是非常重要的因为并非所有像素都需要长期依赖,局部信息更多地关注于提取底层特征。Swin Transformer一个窗口(7×7)中计算自注意,而不是全局接收域,这类似于直接使用一个大内核大小的卷积层(7×7)来覆盖局部接收域。在这些思想的驱动下,本文主要探讨局部性对基于mlp的体系结构的影响。
- 如果将窗口切分(比如说7*7)并在窗口内做token混合映射,那么线性层中窗口间共享49 *49参数,这极大的限制了模型的容量,影响了参数的学习和最终结果。相反的,如果线性层没有在窗口之间共享,用固定的图像大小训练的模型权值不能适应不同输入大小的下游任务,因为不固定的输入大小会导致窗口数量的不匹配。因此,更理想的引入局域性的方法是直接对任意位置的特征点与其周围特征点之间的关系建模,而不需要预先设置固定的窗口(以及窗口大小)
-
主要工作
-
提出了一种基于mlp架构的轴向转移策略,在该架构中,我们在水平和垂直方向上对特征进行空间转移。
-
之后,通道混合MLP融合(通过1*1卷积实现)这些特征,使模型能够获得局部依赖关系。

1*1卷积图示
-
3.结论
本文提出了一个轴向移动的MLP架构,命名为AS-MLP,用于视觉。与MLP-Mixer相比更注重局部特征的提取,通过简单的特征轴向移动,充分利用了不同空间位置之间的通道相互作用。通过所提出的AS-MLP,进一步提高了基于mlp的体系结构的性能,实验结果令人印象深刻。本文模型在ImageNet-1K数据集上的Top-1精度为83.3%,参数为88M, GFLOPs为15.2。这种简单而有效的方法优于所有基于mlp的体系结构,并且与基于变压器的体系结构相比,即使FLOPs略低,也能获得具有竞争力的性能。本文也是第一个将AS-MLP应用于下游任务(例如,对象检测和语义分割)的研究。与基于变压器的体系结构相比,结果也具有竞争力,甚至更好,这表明基于mlp的体系结构在处理下游任务方面的能力。
4.相关工作
MLP- mixer (Tolstikhin et al., 2021)设计了一个非常简洁的框架,利用矩阵变换和MLP在空间特征之间传递信息,并取得了很好的性能。并发工作FF (Melas-Kyriazi, 2021)也采用了类似的网络架构,并得出了类似的结论。随后,本文提出了Res-MLP (Touvron et al., 2021a),该算法仅在ImageNet-1K上训练剩余MLP,也获得了令人印象深刻的性能。gMLP (Liu et al., 2021a)和EA (Guo et al., 2021)分别引入了空间门单元(SGU)和外部关注来改善纯基于mlp的架构的性能。最近,Container (Gao等人,2021年)提出了一种统一卷积、变压器和MLP-Mixer的通用网络。S2-MLP (Yu et al., 2021)使用空间平移MLP进行特征交换。ViP (Hou等人,2021年)。提出了一种用于空间信息编码的Permute-MLP层,以捕获远程依赖。与这些工作不同的是,我们专注于在空间维度上捕获具有轴向移动特征的局部依赖关系,从而获得更好的性能,并可应用于下游任务。此外,还提出了与我们最接近的并行工作CycleMLP (Chen et al., 2021b)和S2-MLPv2 (Yu et al., 2021)。S2-MLPv2改进了S2-MLP, CycleMLP设计了Cycle full - connected Layer (Cycle FC),以获得比Channel FC更大的接收域。
5.网络结构
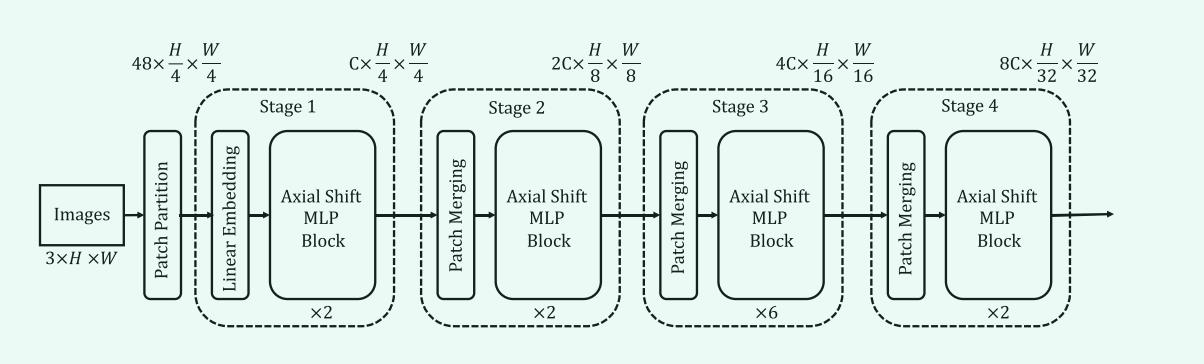
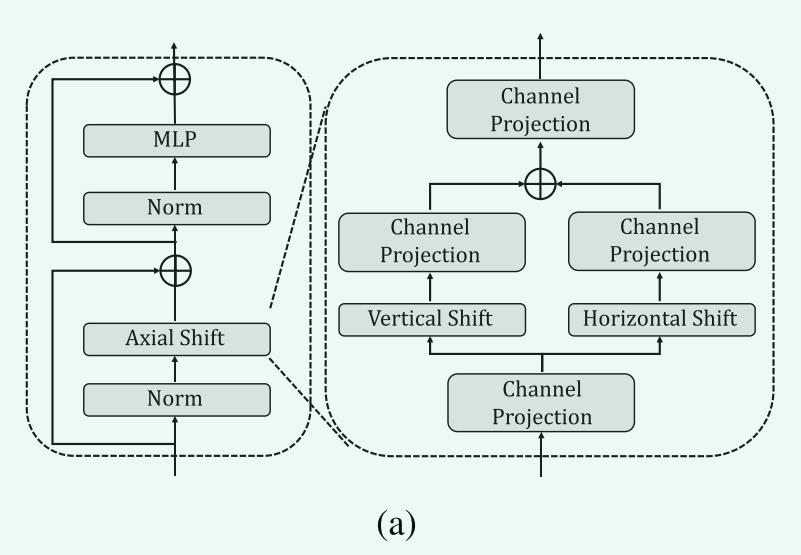
对于一个RGB图像,I \\(\\in R^3 \\times H \\times W\\),H和W代表图像的高度和宽度,同时,AS-MLP进行了patch切分操作,这一操作将原图像切分为大小\\(4 \\times 4\\)的大小,这样的操作,使得所有token(这里token指的是每一个4* 4的图像块)的组合将变为\\(48 \\times \\fracH4 \\times \\fracW4\\)的大小(这样的原因可以理解为原先输入的是单个的像素点,而现在是将4 *4的图像块当作输入),AS-MLP有四个阶段,在第一阶段,对每个token做线性嵌入和AS-MLP,输出大小为\\(C \\times \\fracH4\\times \\fracW4\\);在第二阶段,首先对上一阶段输出的特征进行patch merge,将相邻的2 × 2个patch进行分组,得到\\(4C \\times \\fracH8 \\fracW8\\),然后采用线性层将feature大小变形为\\(2C×\\fracH8 ×\\fracW8\\),然后是级联的AS-MLP块.阶段3和阶段4的结构与阶段2相似,层次表示将在这些阶段生成。下图是一个AS-MLP块内进行的操作。
-
Linear Embedding
PatchEmbed是一个将输入图像转换为图像块的模块。在模块初始化时,我们需要指定输入图像的大小img_size、图像块的大小patch_size、输入图像的通道数in_chans和输出特征图的通道数embed_dim等参数。此外,我们还可以指定一种归一化方法(例如,nn.LayerNorm)作为可选参数norm_layer。在
forward方法中,PatchEmbed首先通过nn.Conv2d将输入图像x划分成多个大小为patch_size的图像块,然后将所有图像块展平成一维向量,最终返回特征向量x。如果指定了归一化方法,则在将图像块展平之前对每个图像块应用归一化操作。经过这个操作之后,输出的形状是(B,embed_dim,H_patch,W_patch),其中H_patch和W_patch是输入图像划分成的patch数量,由输入图像尺寸和patch_size计算得到。输出的图像将传入AS-MLP 块 -
AS-MLP Block
# norm: normalization layer
# proj: channel projection
# actn: activation layer
import torch
import torch.nn.functional as F
def shift(x, dim):
x = F.pad(x, "constant", 0)
x = torch.chunk(x, shift_size, 1)
x = [ torch.roll(x_s, shift, dim) for x_s,
shift in zip(x, range(-pad, pad+1))]
x = torch.cat(x, 1)
return x[:, :, pad:-pad, pad:-pad]
def as_mlp_block(x):
shortcut = x
x = norm(x)
x = actn(norm(proj(x)))
x_lr = actn(proj(shift(x, 3)))
x_td = actn(proj(shift(x, 2)))
x = x_lr + x_td
x = proj(norm(x))
return x + shortcut
为了理解这个过程,我们拿一个(3,5,5)的torch张量,通道1数据设为1,通道2数据设为2,通道3设为3做演示,这里shift_size取5,因此pad=1,这里的proj是1*1卷积。

经过填充之后,

切分之后

x = [ torch.roll(x_s, shift, dim) for x_s,shift in zip(x, range(-pad, pad+1))],这里演示对H维的操作

x = torch.cat(x, 0)

x=x[:, pad:-pad, pad:-pad]

这里是对H维进行shift操作之后的torch张量,我们同样可以得到W维进行shift操作的torch张量

对于得到的两个维度经过shift操作之后的图片,我们在进行1*1卷积进行通道信息融合(proj操作)
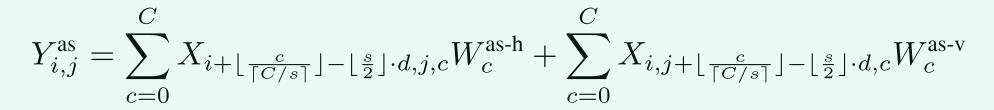
该公式计算的是某一个像素点在经过AS-MLP 块之后的像素值,\\(W^as-h,W^as-v \\in R^C\\)信道投影的可学习权值在水平和垂直方向上。对于一个三通道的图像,\\(Y_i,j\\)也是三通道的,这样需要对X使用三个三通道的1*1卷积,对于每一个通道的\\(Y_i,j\\),我们可以通过上面所举的例子总结规律,\\(Y_i,j\\)的计算实际上是通过\\(X_i\',j\\)和\\(X_i,j\'\\)计算的,这里\\(X_i\',j\\)是经过H维度shift操作之后与\\(Y_i,j\\)对应的像素点,\\(X_i,j\'\\)是经过W维度shift操作之后与\\(Y_i,j\\)对应的像素点,以上面举例的经过H维度shift操作的特征图为例,对于通道一,当前位置为(3,3)的像素点,在经过shift操作之前位置是(5,3),对于通道二,当前位置为(3,3)的像素点,在经过shift操作之前的位置为(3,4),对于通道三,当前位置为(3,3)的像素点,在经过shift操作之前位置为(3,3),由此,我们可以知道,\\(X_i,j\\)位置的像素点,在经过shift操作之后的位置坐标,与通道数、shift_size、膨胀率d有关,我们可以使用不同的通道时、shift_size,膨胀率举例,可以总结出上式的规律。经过AS-MLP后,特征图形状不变,为\\(C \\times \\frach4\\times \\fracW4\\)
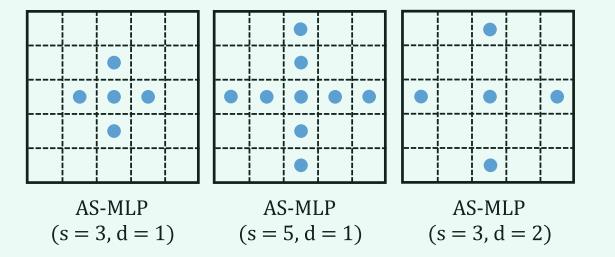
由上式也可推得某一像素点的感受野。
-
LayerNorm:Layer Normalization是一种常见的神经网络正则化方法,它可以用来加速训练和提高模型的性能。相比于Batch Normalization,Layer Normalization不需要对一个批次内的数据进行统计计算,而是对每个样本进行独立的归一化处理。假设有一个大小为\\((n,m)\\)的张量\\(X\\),其中\\(n\\)表示样本数,\\(m\\)表示特征数。对于每个样本\\(x_i\\),可以计算出该样本所有特征值的均值和方差:
\\[\\mu_i=\\frac1m \\sum_j=1^mx_ij \\]\\[\\sigma_i^2=\\frac1m\\sum_j=1^m(x_ij-\\mu_i)^2 \\]然后可以对每个样本进行归一化处理:
\\[\\checkx_ij=\\fracx_ij-\\mu_i\\sqrt\\sigma_i^2+\\epsilon \\]最后,可以将归一化后的特征值\\(\\hatx_i\\)和一个可学习的权重向量\\(w\\)进行线性变换,得到输出特征值:
\\[y_i=\\omega \\cdot \\checkx_i+b \\]其中,\\(w\\)和\\(b\\)是可学习的参数,用来调整输出特征值的幅度和偏置。
与BN的区别:
相比于Batch Normalization,Layer Normalization的主要区别在于计算统计量的方式。Batch Normalization是对一个批次内的所有样本进行统计计算,然后对每个样本进行归一化处理;而Layer Normalization是对每个样本单独进行统计计算和归一化处理,不需要考虑批次的大小和分布。因此,Layer Normalization更加适合处理样本数较少或者样本分布不均匀的情况,而Batch Normalization则更加适合处理大批量的数据。此外,Layer Normalization可以更好地处理RNN等序列模型,因为它不需要对序列进行批次划分。但是,相比于Batch Normalization,Layer Normalization的训练速度和收敛速度较慢,且需要更多的内存空间。
另外,由于Batch Normalization是对整个批次进行归一化处理,因此它可以有效地减少内部协变量移位(Internal Covariate Shift)的影响,从而加速模型训练和提高模型的稳定性。而Layer Normalization在处理协变量移位时的效果相对较差。但是,相比于Batch Normalization,Layer Normalization的输出更加稳定,因为它不会受到批次内样本数量的影响。
-
Patch Merging实现了将一个尺寸为 \\(B\\times C\\times H\\times W\\) 的输入特征 x,转化为一个尺寸为 \\(B\\times 4C\\times \\fracH2\\times \\fracW2\\) 的输出特征,其中输入的 \\(H\\) 和 \\(W\\) 需要是偶数,转化方式如下实际上实现了下采样的过程,通道数加倍,长宽减半:- 将 \\(x\\) 按照 \\(H\\) 和 \\(W\\) 方向上每隔两个元素取一个进行切片,即将 \\(H\\times W\\) 的矩阵转化为 \\(\\fracH2\\times\\fracW2\\times 4\\) 的四维张量,四个维度对应四个切片;
- 将四个切片沿着第二个维度进行拼接,即将 \\(\\fracH2\\times\\fracW2\\times C\\) 的四个张量拼接成 \\(\\fracH2\\times\\fracW2\\times 4C\\) 的张量;
- 对拼接后的张量在第二个维度上应用 LayerNorm;
- 对应用 LayerNorm 后的张量应用 \\(1\\times 1\\) 的卷积变换,将通道数从 \\(4C\\) 减少为 \\(2C\\)。
-
随后将进入下一个AS-MLP块,第三四阶段过程和第二阶段相同
6.实验
-
imagenet-1k数据集上的图像分类:为了评估AS-MLP的有效性,在ImageNet-1K基准上进行了图像分类的实验,该实验收集于(Deng et al., 2009)。它包含1.28万张训练图像和来自1000个类的20K张验证图像。我们报告了单作物Top-1精度的实验结果。我们使用的初始学习率为0.001,带有余弦衰减和20个时期的线性预热。AdamW (Loshchilov & Hutter, 2019)优化器被用于训练300个时代的整个模型,批处理大小为1024。遵循Swin Transformer (Liu et al., 2021b)的训练策略,我们还使用平滑比为0.1的标签平滑(Szegedy et al., 2016)和DropPath (Huang et al., 2016)策略。我们将所有的网络架构划分为基于cnn、基于transformer和基于mlp的架构。输入分辨率为224 × 224。当保持类似的参数和FLOPs时,我们提出的AS-MLP的性能优于其他基于mlp的体系结构。例如,与Mixer-B/16 (Tolstikhin et al., 2021)(76.4%)和ViP-Medium/7 (Hou et al., 2021)(82.7%)相比,AS-MLP-S以更少的参数获得更高的top-1精度(83.1%)。此外,与基于变压器的架构相比,它获得了具有竞争力的性能,例如AS-MLP- b(83.3%)与swi -b (Liu等人,2021b)(83.3%),这表明了我们的AS-MLP架构的有效性。
-
as-mlp块的选择和影响:
-
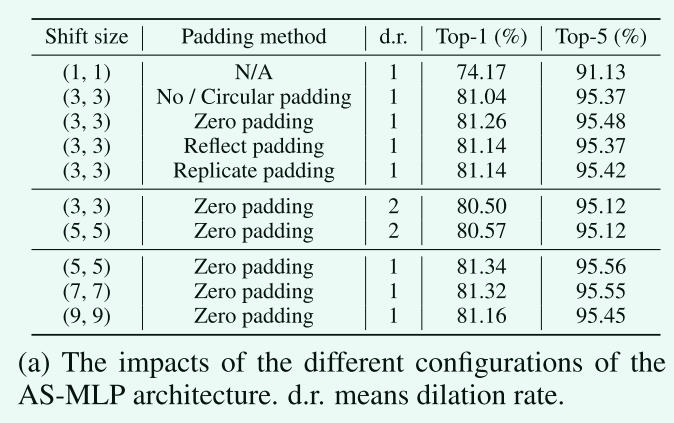
AS-MLP块的不同配置:
- 零填充比其他填充方式更合适
- 增大膨胀率回事AS-MLP性能有所下降,通常使用图像膨胀进行语义分割而不是图像分类
- 当增大shift_size时,精度先增大后减小,可能的原因是接收域被放大时,更关注全局依赖关系,这会使得对局部特征的提取被忽略,因此在实验中使用的是shift size = 5,零填充,膨胀率= 1
-
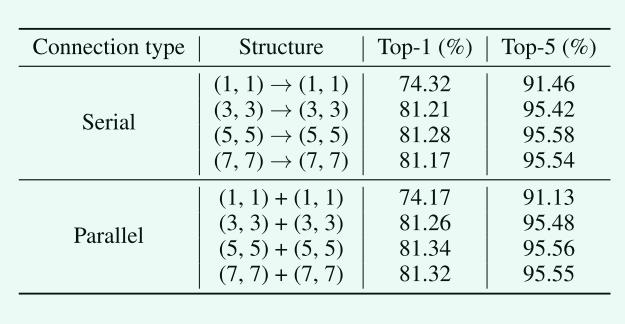
连接类型:在不同的shift_size上,并联方式的性能始终优于串联方式,说明了并联方式的有效性。当位移大小为1时,串行连接较好,但由于只使用信道混合的MLP,串行连接不具有代表性。
-
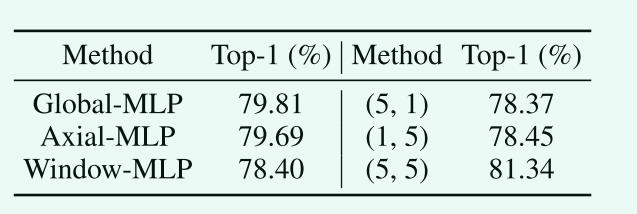
AS-MLP块的影响。我们还评估了表4中AS-MLP块的影响。我们设计了5条基线:i) Global-MLP;ii) AxialMLP;iii) Window-MLP;Iv)位移大小(5,1);v)位移大小(1,5)。前三条基线从如何利用MLP进行不同位置的特征融合的角度设计,后两条基线从单一方向的轴向位移的角度设计。具体设置请参见附录A.5。表4中的结果显示,我们的移动大小为(5,5)的AS-MLP块的表现优于其他基线。
-
-
coco上的对象检测
-
在ade20k上进行语义分割
7.讨论
在本文中,我们提出了一个轴向移动的MLP架构,命名为AS-MLP,用于视觉。与MLP-Mixer相比,我们更注重局部特征的提取,通过简单的特征轴向移动,充分利用了不同空间位置之间的通道相互作用。通过所提出的AS-MLP,我们进一步提高了基于mlp的体系结构的性能,实验结果令人印象深刻。我们的模型在ImageNet-1K数据集上的Top-1精度为83.3%,参数为88M, GFLOPs为15.2。这种简单而有效的方法优于所有基于mlp的体系结构,并且与基于变压器的体系结构相比,即使FLOPs略低,也能获得具有竞争力的性能。我们也是第一个将AS-MLP应用于下游任务(例如,对象检测和语义分割)的研究。与基于变压器的体系结构相比,结果也具有竞争力,甚至更好,这表明基于mlp的体系结构在处理下游任务方面的能力。在未来的工作中,我们将研究AS-MLP在自然语言处理中的有效性,并进一步探讨AS-MLP在下游任务中的性能。
以上是关于论文阅读笔记:AS-MLP AN AXIAL SHIFTED MLP ARCHITECTUREFOR VISION的主要内容,如果未能解决你的问题,请参考以下文章
An improved Otsu method using the weighted object variance for defect detection-论文阅读笔记
参赛作品93openGauss-An Autonomous DatabasePVLDB论文阅读分享
论文笔记:An Experimental Comparison of Performance Metrics for Event Detection Algorithms in NILM
An End-to-End Steel Surface Defect Detection Approach via Fusing Multiple Hierarchical Features-阅读笔记
CV论文阅读An elegant solution for subspace learning
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(阅读笔记)