20191223张俊怡-学习笔记
Posted 北卡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了20191223张俊怡-学习笔记相关的知识,希望对你有一定的参考价值。
第九章-I/O库函数
一、梗概
本章讨论了I/O库函数;解释了I/O库函数的作用及其相对于系统调用的优势;使用示例程序来说明I/O库函数和系统调用之间的关系 并解释了它们之间的相似性和基本区 别;详细介绍了I/O库函数的算法,包括 fread、fw rite 和 fclose 的算法,重点介绍了它们与 read、write和close 系统调用的交互;介绍了I/O库函数的不同模式,包括字符模式、行模式、结构化记录模式和格式化I/0操作:阐述了文牛流缓冲方案,并通过示例程序说明了不同缓冲方案的效果;阐释了有不同参数的函数以及女如何使用stdarg 宏访问参数。
进入本章的学习之前,我觉得有必要了解一下什么是流。
C里的文件流,C里标准文件方式把文件当作流来看,也就是有一个内部缓冲buffer,每次以标准方式打开文件时,读入时先将数据读到这个缓冲区里,写的时候也是先写入缓冲区里。
流分为两种:文本流和二进制流
1.文本流在不同的系统中实现不太相同。
2.二进制流中的字节完全是安照程序编写的形式写入到文件和设备中,而且完全根据他们从文件或者设备读取的方式读入到程序。
文件
说起文件,很多人就会想到在stdio.h里面定义了一个FILE的结构,但是在这里,我要说明的是,千万不要把它和磁盘上的文件混淆,我之前就总是认为FILE嘛,不就是个文件嘛!再次声明,绝对不是!!!
FILE是一种数据结构,用于访问一个流,如果你激活了几个流,那么每个流都会对应一个FILE结构。
对于每一个ANSI C程序而言,至少打开三个流:标准输入(stdin)、标准输出(stdout)、标准错误(stderr),它们都是指向FILE结构的指针。
注:标准输入就是键盘设备输入进去,标准输出就是屏幕终端显示的。
常见的I/O常量
最常见的也是我们所熟知的必定是EOF了,它是文件结束的标志,表示文件到了结尾。 此外还有一些其他的I/O常量: FOPEN_MAX 表示一个程序最多打开文件数。 FILENAME_MAX表示文件名称的最大长度。
I/O函数 文件I/O的一般概况:
1.程序必须给每个文件声明一个指针变量,这个变量的类型为FILE*,当它处于活动状态时为流所用。
2.流通过fopen函数打开,打开的时候必须指定需要访问的文件或者设备以及访问方式。例如:
FILE* fopen(const char* filename,const char*mode)
3.根据需要对文件进行读取和写入。
4.fclose函数可以关闭流,防止与它相关的文件再次被访问,保证存储在缓冲区的数据被正确的写入到文件中。
二、知识点
1、I/O库函数与系统调用
书中9.2节讲到了系统调用函数和I/O库函数的相同点和不同点。示例9.1的代码中,他们的区别体现在:
(1)系统调用程序文件描述符fd是一个整数,库I/O程序中,fp是一个文件流指针。
(2)系统调用open()执行失败返回-1,I/O库函数fopen()执行失败返回NULL。
(3)fopen()发出open()系统调用以获取文件描述符fd。如果open()调用失败,将返回一个NULL指针。否则,它会在程序的堆区分配一个FILE结构体。FILE 结构体包含一个内部缓冲区char fbuf[BLKSIZE]和一个整数fd字段。它记录open()在FILE结构体中返回的文件描述符,将fbuf[]初始化为空,并将FIL E结构体的地址作为fp返回。
(4)fgetc(c,fp)尝试从文件流fp中获取一个字符。如果FILE结构体中的fbufl] 为空,则发出read(fd,fbuf,BLKSIZE)系统调用, 从文件中读取BLKSIZE字节,其中 BLKSIZE与文件系统块大小匹配。然后它从fbuf]返回一个char。随后,fgetc(从fbufl]返回一个char,只要它仍然有数据。这样,库I/O ead函数发出read()系统调用,仅用于重新填充fbufT1,它们总是将BLKSZISE字节的数据从操作系统内核传输到用户空间。
总结:系统调用是需要时间的,程序中频繁使用系统调用会降低程序的运行效率。
当运行内核代码时,CPU工作在内核态,在系统调用发生前需要保存用的栈和内存环境,然后转入内核态工作。
系统调用结束后,又要切换回用户态,这种环境的切会消耗血多时间。
库函数访问文件的时候根据需要,设置不同类型的缓冲区,从而减少了直接调用IO系统的次数,提高了访问效率。
2、I/O库函数的算法
(1)fread()
头文件:#include<stdio.h>
功能:是用于读取二进制数据
原型:
size_t fread(voidbuffer,size_t size,size_t count,FILEstream);
buffer: 是读取的数据存放的内存的指针,
(可以是数组,也可以是新开辟的空间)
#ps: 是一个指向用于保存数据的内存位置的指针(为指向缓冲区保存或读取的数据或者是用于接收数据的内存地址)
size: 是每次读取的字节数
count: 是读取的次数
stream: 是要读取的文件的指针
#ps: 是数据读取的流(输入流)
返回值:
成功:是实际读取的元素(并非字节)数目
失败:返回0
ps:如果输入过程中遇到了文件尾或者输出过程中出现了错误,这个数字可能比请求的元素数目要小
(2)fwrite()
功能:是用于写入二进制数据
头文件:#include<stdio.h>
原型:
size_t fwrite(voidbuffer,size_ size,size_t count,FILEstream)
buffer:是一个指向用于保存数据的内存位置的指针
(是一个指针,对于fwrite来说,是要获取数据的地址)
size: 是每次读取的字节数
count: 是读取的次数
stream: 是数据写入的流(目标指针的文件)
返回值:
是实际写入的元素(并非字节)数目
ps:如果输入过程中遇到了文件尾或者输出过程中出现了失误,这个数字可能比请求的元素数目要小
(3) fopen/fclose
在操作文件之前要用fopen打开文件,操作完毕要用fclose关闭文件。打开文件就是在操作系统中分配一些资源用于保存该文件的状态信息,并得到该文件的标识,以后用户程序就可以用这个标识对文件做各种操作,关闭文件则释放文件在操作系统中占用的资源.
<#include <stdio.h>
FILE *fopen(const char *path, const char *mode);
返回值:成功返回文件指针,出错返回NULL并设置errno
path是文件的路径名,mode表示打开方式。如果文件打开成功,就返回一个FILE *文件指针来标识这个文件。以后调用其它函数对文件做读写操作都要提供这个指针,以指明对哪个文件进行操作。FILE是C标准库中定义的结构体类型,其中包含该文件在内核中标识、I/O缓冲区和当前读写位置等信息。
mode参数是一个字符串,由rwatb+六个字符组合而成,r表示读,w表示写,a表示追加(Append),在文件末尾追加数据使文件的尺寸增大。t表示文本文件,b表示二进制文件,有些操作系统的文本文件和二进制文件格式不同,而在UNIX系统中,无论文本文件还是二进制文件都是由一串字节组成,t和b没有区分,用哪个都一样,也可以省略不写。如果省略t和b,rwa+四个字符有以下6种合法的组合:
"r"
只读,文件必须已存在
"w"
只写,如果文件不存在则创建,如果文件已存在则把文件长度截断(Truncate)为0字节再重新写,也就是替换掉原来的文件内容
"a"
只能在文件末尾追加数据,如果文件不存在则创建
"r+"
允许读和写,文件必须已存在
"w+"
允许读和写,如果文件不存在则创建,如果文件已存在则把文件长度截断为0字节再重新写
"a+"
允许读和追加数据,如果文件不存在则创建
(4)其他I/O库函数
fseek()、ftell(、rewind():更改文件流中的读/写字节位置。
feofO、ferr()、fileno():测试文件流状态。
fdopen():用文件描述符打开文件流。
freopen(:以新名称重新打开现有的流。
setbufO、setvbuf():设置缓冲方案。
popen():创建管道,复刻子进程来调用sh。
3、结构体文件的读写
20191223 张俊怡
20191000 小明
1.定义结构体
//定义一个结构体
typedef struct Student{
int stu_id;
char name[100];
} Stu;
2.写数据
// 定义一个文件指针
FILE *fp ;
// 初始化一个结构体数组
Stu stuw[2] = {
{20191223, "张俊怡" },
{20191000, "小明"}
} ;
// 打开文件,没有文件自动创建
fp = fopen("student.dat","wb"); // b:表示以二进制写入
// 写入数据
fwrite( (char*)stuw,sizeof(Stu),2,fp); //2:表示将数组中两个元素写入文件
// 关闭文件
fclose(fp);
3.读数据
// 定义一个文件指针
FILE *fp ;
// 定义一个buf结构体,用于得到文件内容
struct stat buf;
// 定义一个文件行数记录变量
int rows;
// 定义一个Student结构体
Stu stur[MAX]; // MAX通过#define设置为100
// 求文件中的行数(记录个数)
stat("student.dat",&buf);
rows = buf.st_size/sizeof(Stu);
// 打开文件
fp = fopen("student.dat","rb");
// 读取数据到数组中
fread((char *)stur,sizeof(Stu),rows,fp);
// 关闭文件
fclose(fp);
// 遍历数组,打印数据信息
for(int i=0;i<rows;i++)
printf("%d\\t%s\\n",stur[i].stu_id,stur[i].name);
三、最有收获的内容
本章最有收获的内容是深入理解库函数与系统调用的区别和联系。
·库函数:库函数是语言或应用程序的一部分,可以运行在用户空间中。
·系统调用:又称广义指令,它是由操作系统向程序提供的程序接口,而非直接向用户提供,用户只能通过程序间接的使用这些接口。
1.在概念对比中,可以直观的感触到系统调用是依赖于操作系统的,由于其依赖于平台,所以系统调用的平台移植性较差。
2.而函数库,是将一些已经编写好函数进过封装,存放到函数库(静态库或动态库)中,是具有特定功能函数的集合。 通过库文件向程序员提供相关的函数,以便于调用。程序员不需要关心平台的差异性,如linux或windows,由库对不同平台差异屏蔽。
·关于系统调用的几点说明:
1、系统调用的目的:为了是系统更加稳定安全,防止小白用户、恶意用户进行非法的越权操作。
2、从用户态切换到内核态必须要通过”中断”,只要发生中断,就需要对中断进行处理,也不然会切换到内核点。
总结:
库函数是语言或应用程序的一部分,可以运行在用户空间中。而系统调用是操作系统的一部分,是内核提供给用户的程序接口,运行在内核空间中,而且许多的库函数都会使用系统调用实现功能,如在linux下C中的fopen、fclose、fwrite等文件操作函数其底层就是通过open、close、write等系统调用是实现的。没有使用系统调用的库函数,执行效率通常比系统调用高。因为使用系统调用时,需要通过中断进行上下文的切换以及由用户态向内核态的转移。
四、问题与解决思路
1、文本文件与二进制文件的优缺点是什么?
解决思路:我想文本文件与二进制文件的区别体现在编码方式的不同,简单来说,文本文件是基于字符编码的文件,常见的编码有ASCII编码,UNICODE编码等等。二进制文件是基于值编码的文件。所以他们的优缺点就是编码的优缺点。
文本文件编码基于字符定长,译码容易些;二进制文件编码是变长的,所以它灵活,存储利用率要高些,译码难一些。文本文件的可读性要好些,存储要花费转换时间(读写要编译码),而二进制文件可读性差,存储不存在转换时间。,因为我们用通用的记事本工具就几乎可以浏览所有文本文件,所以说文本文件可读性好;而读写一个具体的二进制文件需要一个具体的文件解码器,所以说二进制文件可读性差。
2、文件操作有哪些?
1.cat命令
一般格式: cat [选项] 文件
有两项功能:在标准输出上显示文件的内容;连接两个或多个文件
如: $ cat f1 f2>f3
常用选项:
-b,–number-noblank 从1开始对所有非空输出行进行编号。
-n,–number 从1开始对所有输出行编号。
-s,–squeeze-blank 将多个相邻的空行合并成一个空行。
–help 打印该命令用法,并退出,其返回码表示成功。
2.more命令
一般格式: more [选项] 文件
说明:该命令一次显示一屏文本,满屏后停下来,并且在屏幕的底部出现一个提示信息,给出至今已显示的该文件的百分比:–More–(XX%)。
常用选项:
-num,这个选项指定一个整数,表示一屏显示多少行。
-d,在每屏的底部显示以下更友好的提示信息:
–More–(XX%)[Press space to continue,\'q\' to quit.]
-c或-p,不滚屏,在显示下一屏之前先清屏。
-s,将文件中连续的空白行压缩成一个空白行显示。
+/,该选项后的模式(Pattern)指定显示每个文件之前进行搜索的字符串。
+num,从行号num开始。
3.less命令
less命令允许用户向前或向后浏览文件,而more命令只能向前浏览。
4.head命令
一般格式: head [选项] file
说明:head命令在屏幕上显示指定文件的开头若干行,行数由参数值来确定。显示行数的默认值是10。
选项:
-c,–bytes=SIZE 显示前面SIZE个字节。
-n,–lines=NUMBER NUMBER的值指定显示前面多少行。默认为10行。
-q,-quiet,–silent 不显示给定文件的标题。
-v,–verbose 始终显示给定文件的标题。
5.tail命令
一般格式: tail [选项] [file] …
说明:tail命令在屏幕上显示指定文件的末尾10行。如果给定的文件不止一个,则在显示的每个文件前面加一个文件名标题。如果没有指定文件或者文件名为“-”,则读取标准输入。
选项:
-c,–bytes=N 输出最后N个字节。
-f 当文件增长时输出附加的数据。
-n,–lines=N 输出最后的N行,而不是默认的10行。
-q,-quiet,–silent 不输出包含给定文件名的标题。
-v,–verbose 始终输出包含给定文件名的标题。
6.touch命令
一般格式: touch [选项] 文件名 …
说明:touch命令将会修改指定文件的时间标签,把已存在文件的时间标签更新为系统当前的时间(默认方式),它们的数据将原封不动地保留下来。如果该文件尚未存在,则建立一个空的新文件。
选项:
-a 仅改变指定文件的存取时间。
-c 不创建任何文件。
-m 仅改变指定文件的修改时间。
-t STAMP 使用STAMP指定的时间标签,而不是系统当前的时间 。
五、实践内容
1、编写一个c程序,将文本文件中的字母由大写转换为小写。
首先在linux下创建一个文本文件,内容为大写字母。

接着编写c语言程序
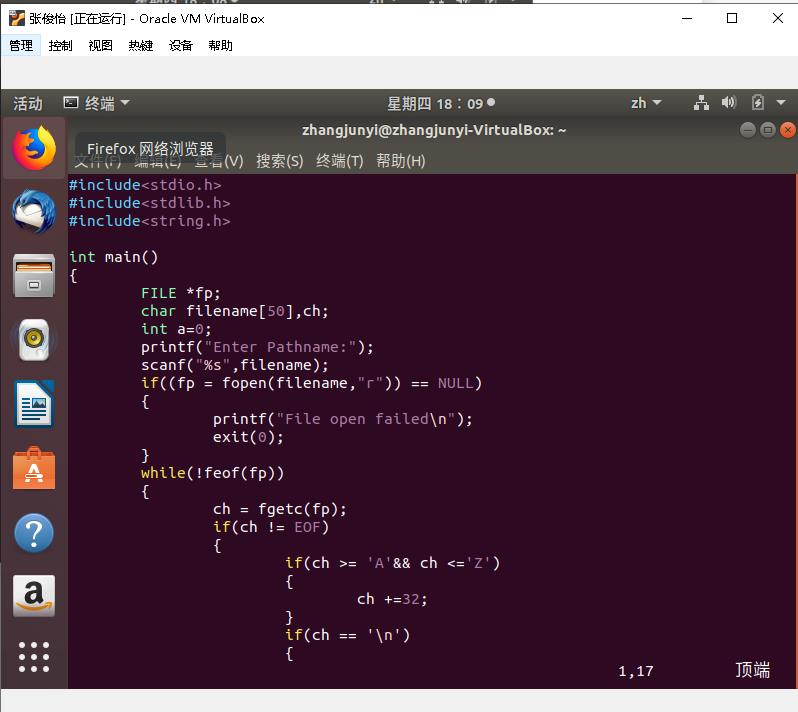
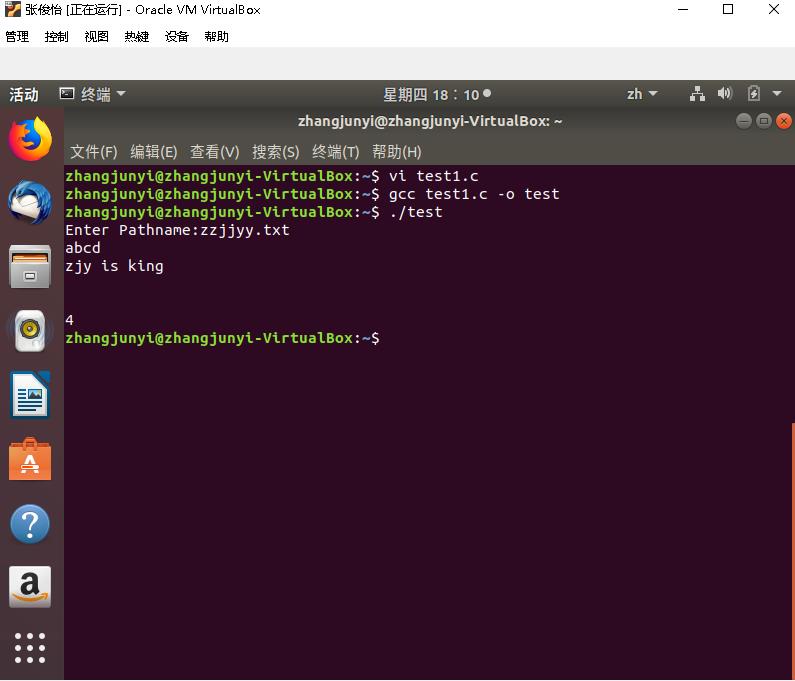
·编译,运行,输入文本文件路径,显示结果:
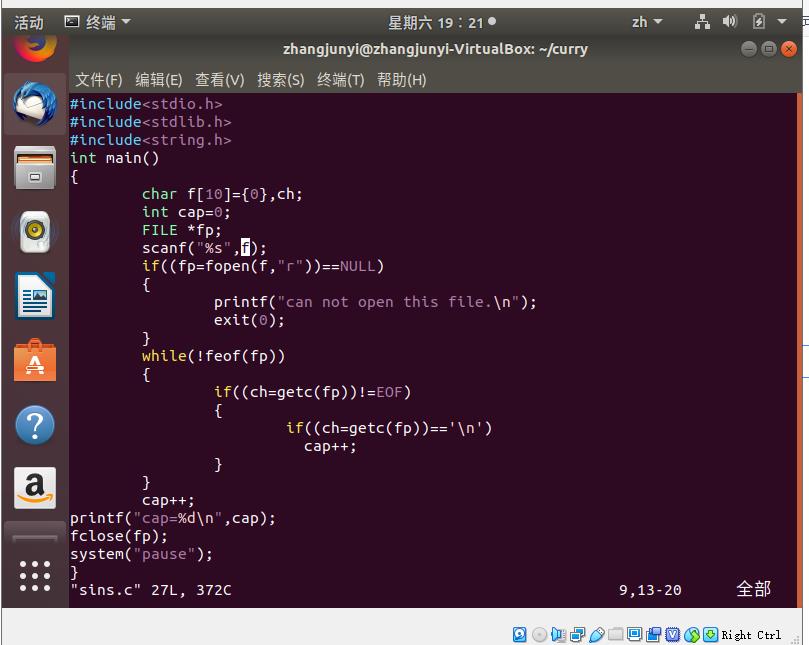
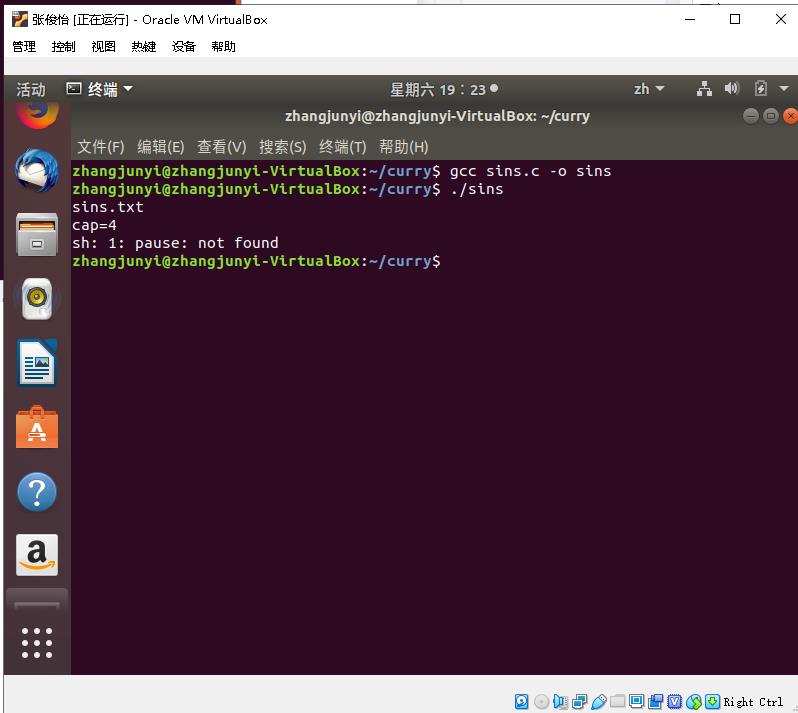
2、编写一个c程序,计算文本文件的行数
代码如图:
文本文件内容:
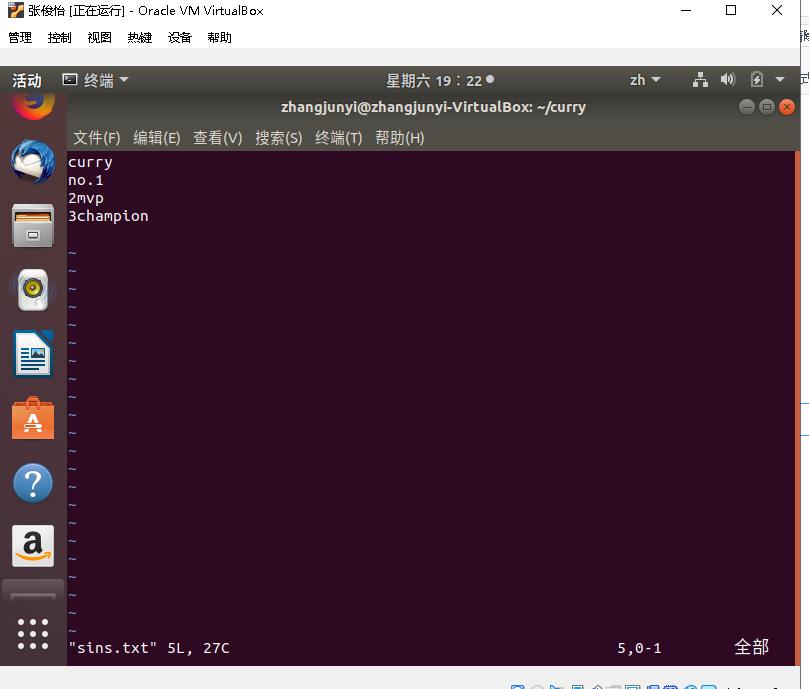
运行结果:
以上是关于20191223张俊怡-学习笔记的主要内容,如果未能解决你的问题,请参考以下文章
[原创]java WEB学习笔记61:Struts2学习之路--通用标签 property,uri,param,set,push,if-else,itertor,sort,date,a标签等(代码片段