深度丨人大宋睿华:自然语言理解的重大突破为何是多模态?
Posted 智源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度丨人大宋睿华:自然语言理解的重大突破为何是多模态?相关的知识,希望对你有一定的参考价值。
智源导读:人是如何在一瞬间将语言理解成意义的?AI可以拥有这样制造意义的心智吗?
在6月3日智源大会的视觉大模型论坛上,中国人民大学高瓴人工智能学院长聘副教授、悟道·文澜团队成员宋睿华作了题为《我们赖以生存的意义和超大规模多模态预训练》的报告。
整理:沈磊贤
校对:李梦佳
01
何以为人
当我们看到一句话“今天我是骑自行车来的”,我们会怎么去理解它?会把它拆分成时间、主语、谓语和介词去分析它吗?
可能一瞬间你根本都没有想这些,我们更容易想到的是一个橘色或者蓝色的共享单车。人类把文字理解成意义的那一瞬间到底发生了什么,这正是报告所关注的问题。
再举一个「北极熊的鼻子」的故事的例子,当我们看到“北极熊爱吃海豹肉,而且爱吃新鲜的”这个句子,一刹那脑袋里会浮现出来《动物世界》里的一只北极熊,也会有海豹隐隐约约的影子。同时看到“它爱吃新鲜的”,甚至有一点要流口水的感觉。当我们看到文字描写北极熊是怎么捉海豹的,讲到了它「一跃而起,伸出爪子,露出獠牙」,我们可能也有一种想动,想张嘴的冲动,其实这是因为我们在理解文字的时候,有可能也调动了自己运动的部分。

图1 北极熊的鼻子文案
故事说到,「北极熊几乎可以完美地将自己隐身于周遭的冰天雪地」,我们可能会想这里面有一点推理和常识,原文中从来也没有提到过颜色相关的词,然而我们可以理解这句话,因为我们自己会补上这样的常识,我们头脑中的北极熊一定是白色的毛覆盖着的一只熊,头脑中的冰天雪地一定是雪白的,所以故事中说北极熊能够隐藏在冰天雪地中,我们一点都不觉得突兀,觉得它是符合常识的,所以我们看到这些文字的一瞬间,已经调动了非常多的细节。
我们每一天都好像遨游在文字的海洋里,就像海里的鱼,在海里遨游、呼吸,好像并没有感觉到自己在呼吸,我们听到别人讲话一瞬间就理解了它,这是一个非常神奇的能力。
《我们赖以生存的意义》这本书为我们解开了上述问题的答案:作者本杰明·伯根(Benjamin K. Bergen)在探讨大脑如何制造意义,同时也在探讨人何以为人。语言的强大之处在于,它可以描述不存在的东西,但是人一样能够理解它,而且这个理解是因人而异的。

(右图是左侧英文图书的中文译本)
在这本书里讲到,为什么认知科学家、脑科学家、计算机科学家都这么着迷文字呢?我们为什么着迷人是怎么把文字变成意义的呢?这个问题可以追溯到六七十年前,在哲学上,大家会争论何以为人,有一派认为人是理性的,而且是在做着推理,最关注的是符号,这和人工智能学科中的符号主义是暗合的。
在前三十年里,这个学派非常占上风,但是大家觉得这个理论好像解释不通,如果把文字想象成符号,把符号的意义当成是字典里的一个字条的话,还是有很多地方不合理。加入每种语言都可以对应到我们头脑中的思想语言,而这种语言又能对应到世界,这种语言本身又是如何做到的呢?其实思想语言并没有解决这一问题,只是把问题往后推了一步。
后来有一些认知科学家就不约而同地想,把语言当成符号去看太过于简单,他们就提出了另外一派学说——体验革命,即人类处理语言并不光是大脑的事情,其实和自己的身体息息相关,包括声音、视觉、味道、气味、触感和运动等模态。
02
意义与我们的亲身经历密切相关
虽然在三四十年前就已经有科学家提到了相关的假说,但是不能进行真正的直接验证,很多科学家设计了一些精妙的实验来间接验证。比如认知心理学家罗尔夫·扎瓦恩做了一系列实验来探究语言在头脑里唤起的只是提到物体的视觉形象,还是模拟了一些细节,比如物体的方向。扎瓦恩让被试者坐在屏幕前,然后屏幕上会打出一个句子,比如:一位木匠把钉子敲到了墙里。
接着,他会看到一张图片,这张图片可能是一个钉子,也可能是一头大象,然后他问被试者看到的图片是不是之前句子里提及的物品。这里面有个实验控制的环节,就是他放出的钉子图片其实并不一定是同一张图片——钉子有可能横着,也有可能竖着。
为什么这样做?因为实验人员很巧妙地加了另外一个句子,那就是:木匠把钉子敲到了地板里。然后罗尔夫·扎瓦恩的研究团队发现:人们在做判断的时候,时间上有了明显的差异。如果图片里的钉子是敲到墙里的,而且图片展示的是水平的钉子的话,人们判断的速度会更快。如果这个钉子是敲到地板上,而且图片展示的是垂直的钉子的话,人们的判断速度也会加快。所以这个实验就刚好验证了大家的猜测:人们在理解一个句子的时候,可能在脑海中模拟了它的场景,包括存在的方向性指引。
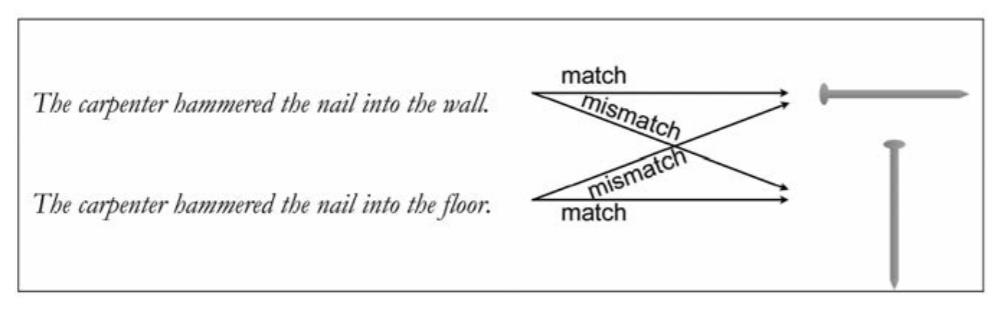 图2 罗尔夫·扎瓦恩的系列实验
图2 罗尔夫·扎瓦恩的系列实验
一些科学家制造出奇怪的工具来做间接的实验。下图所示的装置叫格拉斯帕龙,科学家们用恐龙命名法来给它起名。它是一个半圆形平台,平台上放置大大小小的器件,分为粗细,横放竖放等不同种类,之后向被试者朗读,医生、学者、杯子等词语。实验发现,朗读「杯子」时,人们握竖着的圆柱体比去拿细小或者横放的圆柱体明显要快。这解释了,人可能听到「杯子」的一瞬间,就调动了自己做出「手握」动作的部分。这是他们实验的结论。

图3 格拉斯帕龙系列实验
体验模拟假说讲的是,人类听到一个语言时,很有可能是在调动过去的经验来模拟语言中描述的内容,从而得到这种体验,而这种体验可以是各方面的,视觉、听觉、嗅觉,甚至运动。意义(meaning)很可能不是从我们亲身经历中提炼出来的东西,而始终跟我们的亲身经历密不可分。
比如说到狗,在不同人心里有不同的感觉。很多人养狗,一听到它就会感觉温暖,想起摸着它毛时候的触感。但是也有人小时候被狗咬过,一听到狗就不寒而栗。研究人员一直在研究语言和图像的标准意义,但我们忽略了一点——语言和图像对每个人来说意义是不同的。
03
AI可以拥有能制造意义的心智吗?
AI可以拥有这样制造意义的心智吗?这是计算机科学家所感兴趣的一个问题。
人其实很爱听故事,我们如果听到了故事脑海里会想象出一些画面,那么一种检测自然语言理解的方法是:AI可不可以也具有这样的能力呢?以儿童故事为例,先用传统方法对文字进行抽取工作。比如说下图故事是「小象的大耳朵」:太阳火辣辣照着大地,牛伯伯在田间劳作,这时我们可以抽出这个场景是「在田间」,也可以抽取出一个人物,有一个「牛伯伯」,同样的方式还可以抽取更多的信息,并且在段落中进行一些推理(如果这些地点都没有换,可能之前的场景就会归属到上一个地点),于是我们可以自动地去拼接艺术家创作的剪贴画来生成故事。
如果我们说到牛伯伯,就让牛伯伯站在一个位置上,当说到小象拉拉要为他煽动大耳朵的时候,就让小象拉拉出现,以及他说话的时候,可以出现一个气泡,可以分析他的情感并调动不同的画面。这样一来,瞬间可以生出几百、几千个故事。但是很遗憾的是这中间丢失了很多细节,比如当故事中说到小象把小老鼠一下子扇到了芭蕉叶上,怎么去表现把小老鼠扇到芭蕉叶上是一个难题,角色之间,或者是角色跟环境之间进行交互会产生无穷无尽的可能性。艺术家是画不过来的。

图4 小象的大耳朵案例
后续我们有工作发现从语言到画面需要更好的整句理解。下图是2019年ACM Multimedia的一篇工作,展现了画饼充饥的故事,我们将成语写成了白话文,用图解电影中的图片代替了剪切画,最终生成的效果如下,前面红色对应的是第一段,蓝色的是第二段,黄色的框是第三段,可以看出它的确抓住了很多故事里的细节,比之前手动做的剪切画要丰富很多。
此外,第八幅图说到孩子被父母找到了,虽然只是简单的几个词,但图片显示,孩子被爸爸抱在怀里,妈妈在旁边露出很小一部分脸,在哭泣的样子,非常像久别重逢的场面。从中可以得到了一个非常大的激励,即我们是有可能从非常简约的文字信息去做跨模态的检索,也许就像人听到文字的一瞬间,可以用经历补上了细节,于是就有了图中拥抱和哭泣的细节。这是一个很有价值的结论。

图5 图解电影理解文字信息
04
多模态是AI开启常识之门的钥匙
人从小到大有丰富的经历在脑海中,我们有各种感官的数据。但是人工智能很难,因为它现在还没有能力用全感官的方式识别这个世界。但好在我们有电影,电影其实是非常接近于体验的东西。
然而,无论是语言还是影视作品,都不是连续的流水账。跳跃和留白才是心智喜欢的方式。人类能很容易的在那些缝隙和留白里脑补上细节。那么AI是不是也有这种脑补细节的能力呢?仅仅通过文字是很难做到的,一个大胆的预言是:对多模态的研究可能会带来自然语言理解的重大突破, 多模态将是AI开启常识之门的钥匙。
文澜项目开始的目标是做一个大规模的图文多模态预训练模型,并回答多模态模型到底比单模态模型多了什么?在做第一代文澜时,我们就观察到一个有趣的差别。下面展示的两张图:一张是用BERT文本预训练模型得到的结果,而另一张则是用UNITER多模态预训练模型得到的结果。回到之前的例子,“自行车”到底在文本的数据上学到的相似词有哪些?我们可以发现它周围有很多不同句子里出现了自行车,或者是摩托车,或者是汽车。而我们看多模态这张图可以发现,如果利用了图片,我们可以知道自行车周围有一些“骑”、“男人、女人”一类的词,因为他们是骑车的人,还有“头盔”,“停车”,甚至有“on”这样表示“位于车上”的词。
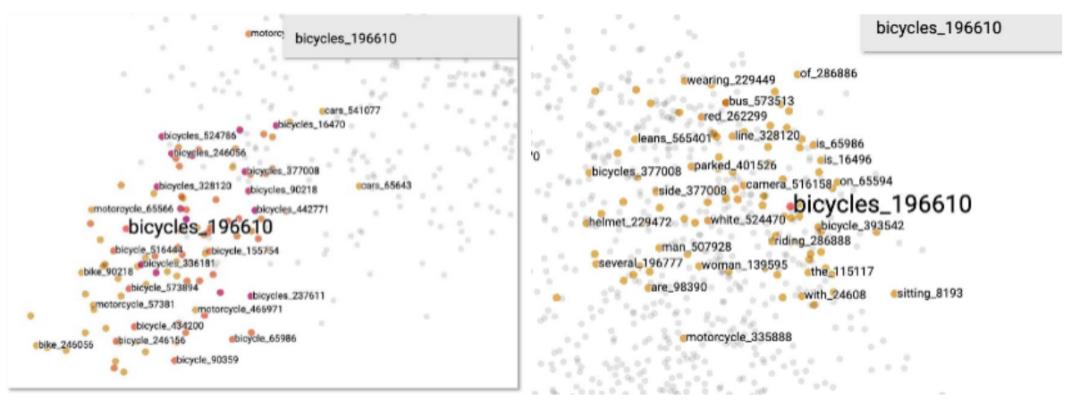
图6 BERT文本单模态预训练模型(左)和UNITER图文多模态预训练模型(右)
05
第二代悟道·文澜大规模预训练模型
悟道·文澜的出发点是面对千万甚至亿级的图文对,并且关注以下三个问题,一是怎样的模型才能比较好地刻画互联网上图文弱相关的关系?二是是否能以已有的单模态预训练大模型的成果作为基础?三是能否节约资源,可以应用落地到大中小型企业?
第二代文澜主要有三个特点,一是巨规模,6.5亿通用图文对作为训练数据,使用BriVL-2双塔模型进行训练;二是多语言,支持7种语言,使用MLMM单塔模型;三是易落地,53亿参数可以实现单卡落地。第二代文澜替换了第一代文澜的目标检测器,采用Multi-Grid Split池化技术,显著地提高了计算效率。在分布式预训练方面采用了DeepSpeed的数据并行、混合精度训练以及零冗余优化器三大技术来减少预训练模型所占的GPU显存,最大化GPU和CPU的使用率,最优地支持大规模的跨模态对比学习。国内外都非常重视多模态方面这个领域,Open AI也在研制多模态的模型并在1月份推出了CLIP。经过实验对比,文澜二代的性能是比CLIP要好很多的。
为了让更多的人体验到文澜的效果,我们还特意开发了一款小应用——布灵的想象世界。它是基于悟道∙文澜双塔模型,事先我们把图片库里的图象编码成一个高维向量,当用户输入文字时,文澜模型又可以将文字映射到同一个空间,于是通过向量检索,获得相关的图片。这种纯跨模态检索的方式有别于目前的图片搜索,首先文澜支持整句理解,而非关键字,句子可以很长;其次,传统的图片搜索实质上是用文本查询去检索图像周边的文本,而非图像本身。因此,布灵的想象世界首次实现了高效的跨模态检索。

如果用“今天我是骑自行车来的”去问布灵,结果如下图所示:
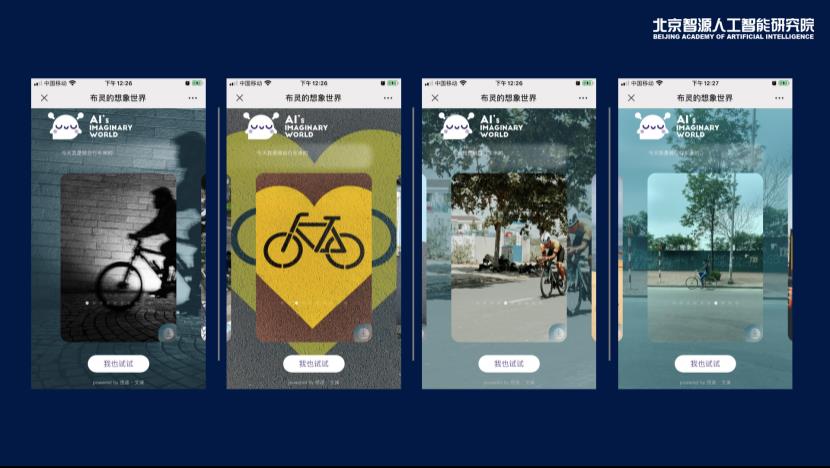
我们欣喜的看到,通过悟道∙文澜跨模态检索,AI也可以从这句话联想到头盔、骑行的细节,甚至自行车道的简笔画,就像我们人类听到那句话的一刹那一样。
06
总结
多模态是AI拥有常识的钥匙,我不认为知识图谱是表示常识的好方式,因为常识是无穷无尽、不断变化的多模态体验。我很喜欢《我们赖以生存的意义》里的一句话:“人未必是思考的机器,而是可以思考的感觉机器。”
以上是关于深度丨人大宋睿华:自然语言理解的重大突破为何是多模态?的主要内容,如果未能解决你的问题,请参考以下文章
科大讯飞全球1024开发者节:多模感知深度理解多维表达运动智能