干货丨深度学习实战篇-基于RNN的中文分词探索
Posted 人工智能爱好者俱乐部
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货丨深度学习实战篇-基于RNN的中文分词探索相关的知识,希望对你有一定的参考价值。
随着深度学习在越来越多的领域中取得了突破性进展,自然语言处理这一人工智能的重要领域吸引了大批的研究者的注意力。
自然语言处理是人工智能和语言学的交叉学科,在搜索引擎,问答系统,机器翻译等人工智能领域发挥着重要作用。本篇就结合我们近期的一些探索从中文分词角度探索深度学习在自然语言处理中的应用。
中文分词是将自然语言文本划分成词语序列,目前主流方法为序列标注,即用BMES这个四个标签去标注句子中的每一个字(B是词首,M是词中,E是词尾,S是单字词)。
对于 { 京东 搜索 与 大数据 平台 数据挖掘 算法部 }
其标注为{ BE BE S BME BE BMME BME }
使用Keras实现了基于RNN的中文分词,接下来就分别介绍一下Keras和中文分词实战。
1. Keras介绍
Keras 是一个高度模块化的深度学习框架,使用python编写,封装了大量的函数接口,可支持CPU和GPU训练。Keras提供了一系列模块,这样我们在实验模型的时候只需要调用这些模块就可以完成模型搭建,不用自己在去实现各层网络。
使用Keras进行模型试验,可分为四个步骤(数据准备,模型构建, 模型训练, 模型测试),本文也将基于这四个步骤探索基于RNN的中文分词。
2. 中文分词实战
数据准备
训练数据使用的是bakeoff2005中的北京大学的标注语料,train作为训练样本,test作为测试样本。
统计训练样本中出现的字符并生成字典,同时将训练样本中字符全部映射成对应的字典索引(为了处理未登录词,将出现次数低于2次的字符映射为未登录词)。在序列标注分词中,一个字的标签受到上下文的影响,因而取该字的前后3个字作为特征。
模型构建

本文模型由一层Embedding层,2层LSTM,一个Dense输出层构成,目标函数为交叉熵,优化函数选择adam。为了验证方法的有效性,本文未采用外部语料预训练词向量,而是在训练数据上训练词向量。
Embedding层完成从词典索引到词向量的映射过程,即输入一个词典索引,输出该索引对应的词向量,第一层LSTM层输入为词向量序列,输出为隐层输出序列,第二层LSTM层输入为前一层输出序列,输出为隐层个数,Dense输出层输入为第二层LSTM输出,输出为类别数。
在这里embeddingDim设为128,RNN序列长度设为7,LSTM隐层个数设为100,outputDims设为4,batch_size设为128。
模型训练
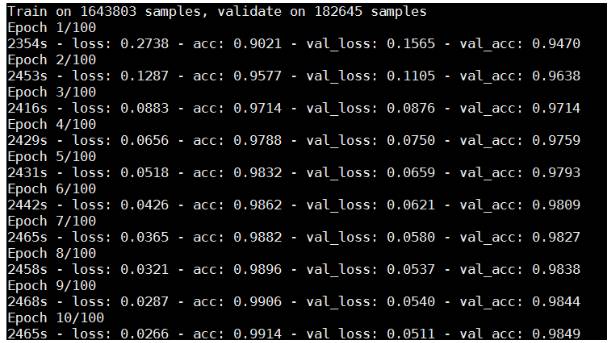
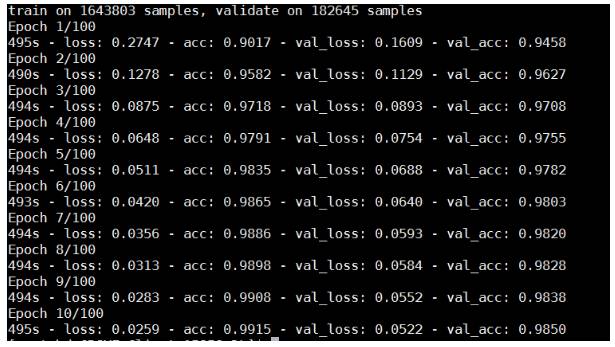
分别在CPU和GPU(使用单卡)上进行模型训练,使用单卡GPU的速度为CPU的4.7倍,未来还会测试单机多卡和多机多卡的性能。
CPU
GPU
模型测试
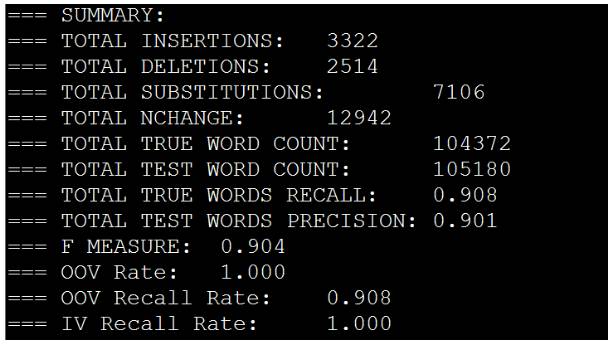
使用北京大学test进行测试,并使用bakeoff2005的测试脚本进行测试,结果如下所示:
3.总结和展望
深度学习的优点是可以自动发现特征,大大减少了特征工程的工作量。目前深度学习已经在语音和图像等领域取得重大进展,自然语言与语音、图像不同,是抽象符号,因而如何将深度学习应用于自然语言处理需要进行更多的研究和探索。
以上是关于干货丨深度学习实战篇-基于RNN的中文分词探索的主要内容,如果未能解决你的问题,请参考以下文章