突破次元壁障,Python爬虫获取二次元女友
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了突破次元壁障,Python爬虫获取二次元女友相关的知识,希望对你有一定的参考价值。
前言
(又到了常见的无中生友环节了)我有一个朋友,最近沉迷二次元,想要与喜欢的二次元角色度过一生,就像11区与初音未来结婚的阿宅那样。于是作为为朋友两肋插刀的正义的化身,决定为其充满魔幻现实的人生再添加一抹亮色,让他深陷其中无法自拔,于是在二次元的宇宙里,帮他用Python获取了二次元女友(们)。

尽管二次元知识人类幻想出来的唯美世界,但其本质上还是我们心中模糊的对梦想生活的憧憬和对美好未来的期望,这卡哇伊的颜,爱了爱了,我给你讲。
程序说明
通过爬取知名二次元网站——触站,获取高清动漫图片,并将获取的webp格式的图片转化为更为常见的png格式图片。
二次元女友获取程序
使用requests库请求网页内容,使用BeautifulSoup4解析网页,最后使用PIL库将webp格式的图片转化为更为常见的png格式图片。
观察网页结构
首先选择想要获取的图片类型,这里已女孩子为例,当然大家也可以选择生活或者脚掌,甚至是男孩子。
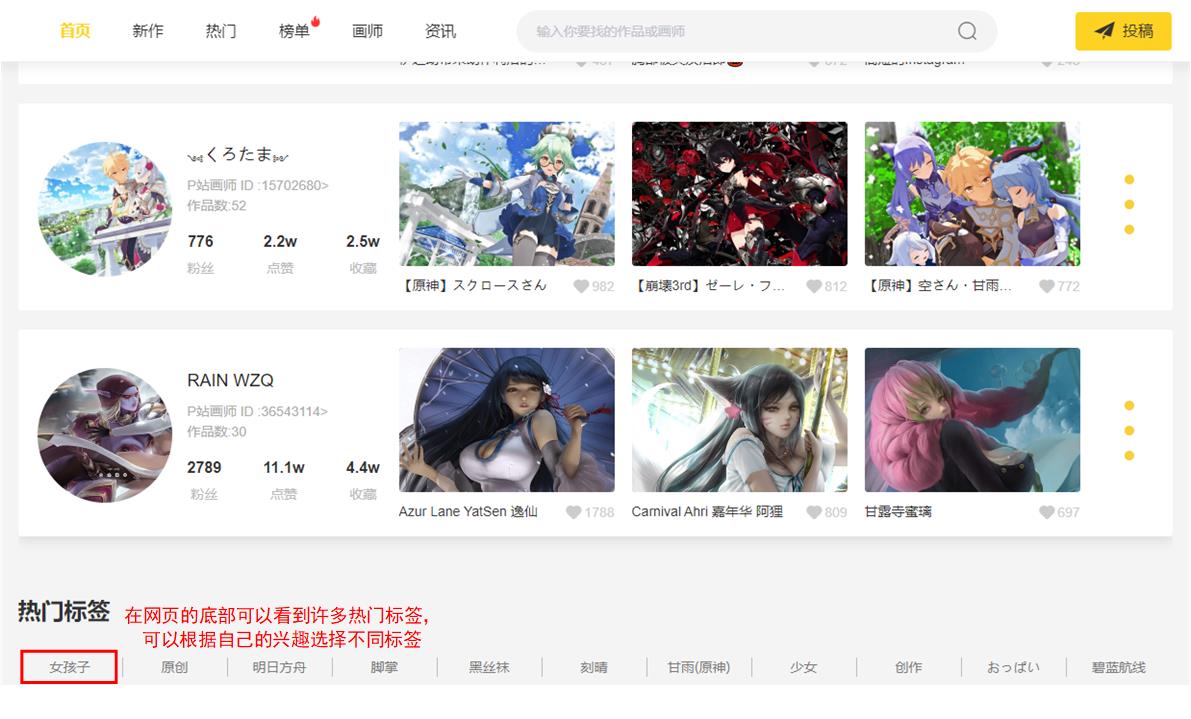 进入
进入女孩子标签页面,观察页面链接,爬取多个页面,查看第2页链接为:
https://www.huashi6.com/tags/161?p=2
第3页链接为:
https://www.huashi6.com/tags/161?p=3
可以看出,不同页面网址仅改变了页面数字,因此可以构造如下模式,并使用循环,爬取所有页面:
url_pattern = "https://www.huashi6.com/tags/161?p={}"
for i in range(1, 20):
url = url_pattern.format(i)
接下来,在爬取网页前,使用浏览器“开发者工具”,观察网页结构。首先尝试定位图片元素:
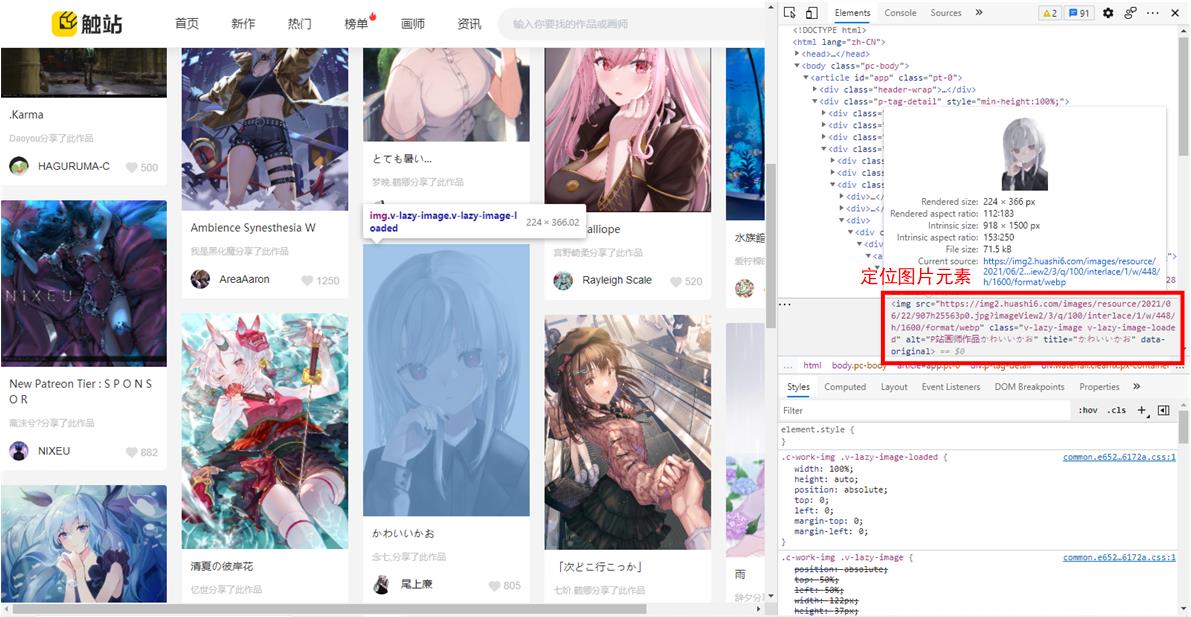
于是自然想到使用find_all语法获取所有class=‘v-lazy-img v-lazy-image-loaded’的标签:
img_url = soup.find_all('img', attr={'class': 'v-lazy-img v-lazy-image-loaded'})
但是发现并未成功获取,于是经过进一步探索发现,其图片信息是在script元素中动态加载的:
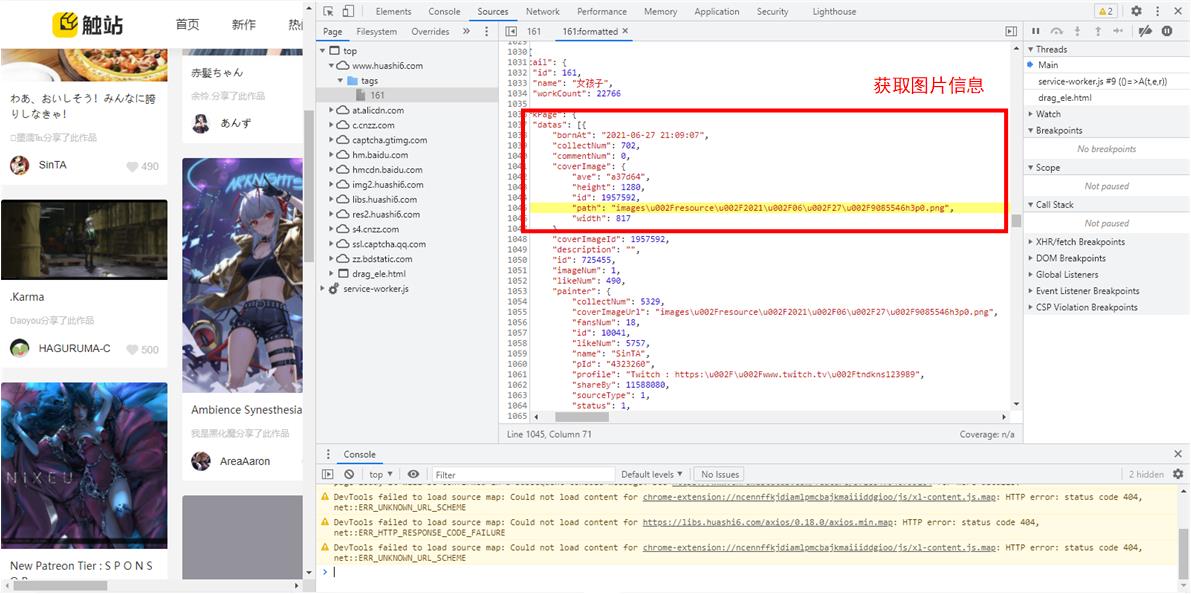
需要注意的是,在请求页面时,可以在构造请求头时,添加'Cookie'键值,但是没有此键值也能够运行。
headers = {
'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:86.0) Gecko/20100101 Firefox/86.0',
# 根据自己的情况修改Cookie值
#'Cookie':''
}
url_pattern = "https://www.huashi6.com/tags/161"
response = requests.get(url=url, headers=headers)
页面解析
使用beautifulsoup解析页面,获取JS中所需数据:
results = soup.find_all('script')[1]
为了能够使用re解析获取内容,需要将内容转换为字符串:
image_dirty = str(results)
接下来构造正则表达式获取图片地址:
pattern = re.compile(item, re.I|re.M)
然后查找所有的图片地址:
result_list = pattern.findall(image_dirty)
为了方便获取所需字段,构造解析函数
def analysis(item,results):
pattern = re.compile(item, re.I|re.M)
result_list = pattern.findall(results)
return result_list
打印获取的图片地址:
urls = analysis(r'"path":"(.*?)"', image_dirty)
urls[0:1]
发现一堆奇怪的字符:
'images\\\\u002Fresource\\\\u002F2021\\\\u002F06\\\\u002F20\\\\u002F906h89635p0.jpg',
这是由于网页编码的原因造成的,由于一开始使用utf-8方式解码网页,并不能解码Unicode:
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
因此虽然可以通过以下方式获取原始地址:
url = 'images\\u002Fresource\\u002F2021\\u002F05\\u002F22\\u002F90h013034p0.jpg'
decodeunichars = url.encode('utf-8').decode('unicode-escape')
但是我们可以通过response.encoding = 'unicode-escape'进行更简单的解码,缺点是网页的许多中文字符会变成乱码,但是字不重要不是么?看图!

创建图片保存路径
为了下载图片,首先创建图片保存路径:
# 创建图片保存路径
if not os.path.exists(webp_file):
os.makedirs(webp_file, exist_ok=True)
if not os.path.exists(png_file):
os.makedirs(png_file, exist_ok=True)
图片下载
当我们使用另存为选项时,发现格式为webp,但是上述获取的图片地址为jpg或png,如果直接存储为jpg或png格式,会导致格式错误。
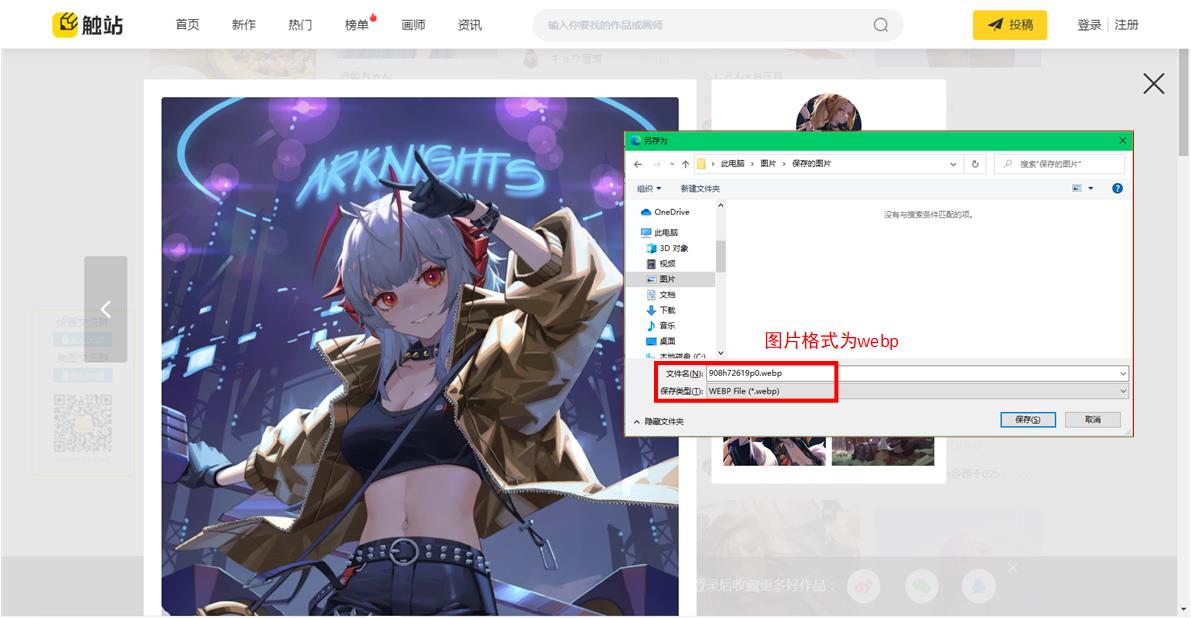 因此需要重新构建
因此需要重新构建webp格式的文件名:
name = img.split('/')[-1]
name = name.split('.')[0]
name_webp = name + '.webp'
由于获取的图片地址并不完整,需要添加网站主页来构建图片地址:
from urllib.request import urljoin
domain = 'https://img2.huashi6.com'
img_url = urljoin(domain,img)
接下来就是下载图片了:
r = requests.get(img_url,headers=headers)
if r.status_code == 200:
with open(name_webp, 'wb') as f:
f.write(r.content)
格式转换
最后,由于得到的图片是webp格式的,如果希望得到更加常见的png格式,需要使用PIL库进行转换:
image_wepb = Image.open(name_webp)
image_wepb.save(name_png)
爬取结果展示
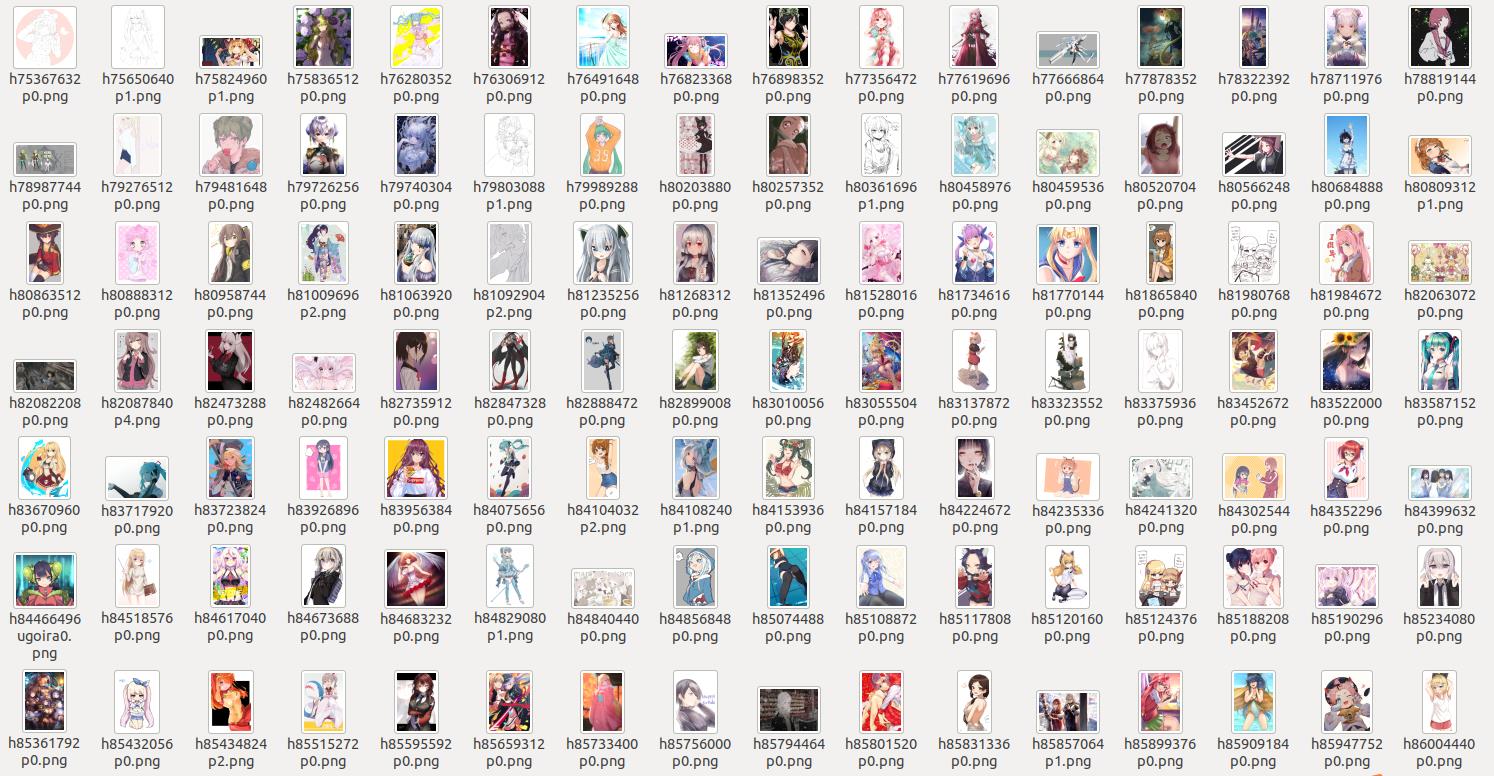
完整程序
import time
import requests
from bs4 import BeautifulSoup
import os
import re
from urllib.request import urljoin
from PIL import Image
webp_file = 'girlfriends_webp'
png_file = 'girlfriends_png'
print(os.getcwd())
# 创建图片保存路径
if not os.path.exists(webp_file):
os.makedirs(webp_file, exist_ok=True)
if not os.path.exists(png_file):
os.makedirs(png_file, exist_ok=True)
headers = {
'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:86.0) Gecko/20100101 Firefox/86.0',
#'Cookie':''
'Connection': 'keep-alive'
}
url_pattern = "https://www.huashi6.com/tags/161?p={}"
domain = 'https://img2.huashi6.com'
# 图片地址获取函数
def analysis(item,results):
pattern = re.compile(item, re.I|re.M)
result_list = pattern.findall(results)
return result_list
# 图片格式转换函数
def change_webp2png(name_webp, name_png, img_url):
try:
image_wepb = Image.open(name_webp)
image_wepb.save(name_png)
except:
download_image(name_webp, name_png, img_url)
# 图片下载函数
def download_image(name_webp, name_png, img_url):
if not os.path.exists(name_png):
if os.path.exists(name_webp):
os.remove(name_webp)
print(img_url)
r = requests.get(img_url,headers=headers)
# print(r.content)
time.sleep(5)
if r.status_code == 200:
with open(name_webp, 'wb') as f:
f.write(r.content)
change_webp2png(name_webp, name_png, img_url)
for i in range(1, 20):
time.sleep(5)
url = url_pattern.format(i)
response = requests.get(url=url, headers=headers)
# 解码
# response.encoding = 'utf-8'
response.encoding = 'unicode-escape'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.find_all('script')
image_dirty = str(results[1])
urls = analysis(r'"path":"(.*?)"', image_dirty)[:20]
for img in urls:
img_url = urljoin(domain,img)
# 获取文件名
name = img.split('/')[-1]
name = name.split('.')[0]
name_webp = name + '.webp'
name_webp = os.path.join(webp_file, name_webp)
name_png = name + '.png'
name_png = os.path.join(png_file, name_png)
download_image(name_webp, name_png, img_url)
以上是关于突破次元壁障,Python爬虫获取二次元女友的主要内容,如果未能解决你的问题,请参考以下文章
渣男,你为什么有这么多小姐姐的照片?因为我Python爬虫学的好啊❤️!