渣男,你为什么有这么多小姐姐的照片?因为我Python爬虫学的好啊❤️!
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了渣男,你为什么有这么多小姐姐的照片?因为我Python爬虫学的好啊❤️!相关的知识,希望对你有一定的参考价值。
前言
大家心心念的三次元来了,又又到了无中生友的环节了,自从上次出了突破次元壁障,Python爬虫获取二次元女友后,很多朋友都在评论说想要一期三次元小姐姐的爬虫教程,这个问题就来了,虽然三次元小姐姐的图片网站有很多,但是本着学习交流的目的,要找一个尺度合适的就太难了,但是我没有放弃,经过了夜以继日的长时间不懈努力,终于为大家找到了一个适合学习研究爬虫技术的治愈系图库分享网站,这从每篇图册的名字就可以看出来,例如《你依旧是你》、《你的美好适逢其时》、《时光都走慢了》等等就可以看出来了,如果你还是不相信,我只能将网页展示一下了。
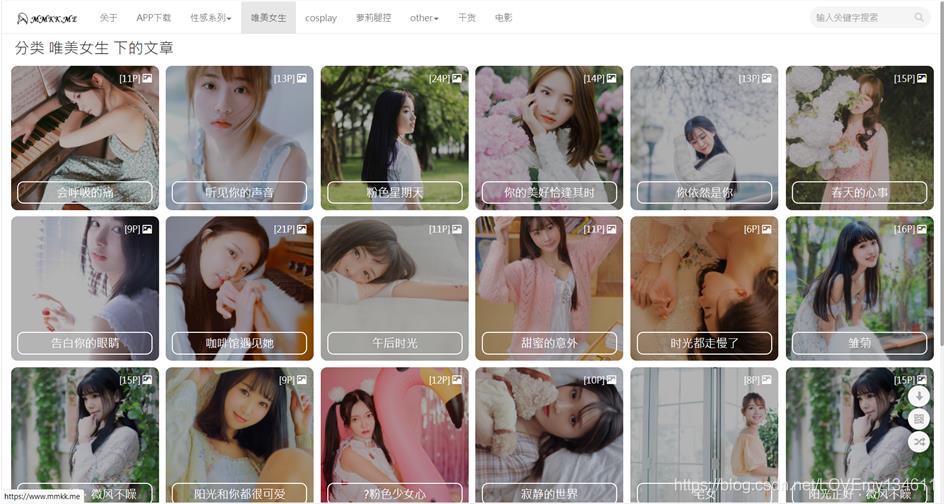
怎么样,没骗人吧?都是治愈系的小姐姐。
程序说明
通过爬取小姐姐图库分享网站——mmkk.me,获取高清小姐姐照片,使用库包括:requests 和 BeautifulSoup。
爬虫程序
有很多小伙伴可能会想都是爬图片,那和突破次元壁障,Python爬虫获取二次元女友中介绍的方法有什么区别呢,直接换下网址,解析不同的元素不就可以了?如果真的只是这样,那我直接给出网站不就可以了(虽然可能很多小伙伴的真实目的就只需要这个),但如果你也是这么想的,那你就想的太简单了。
观察网页结构
在网页结构这里我们就能看到第一个区别,就是此网站的加载方式,是页面滚动动态加载数据,也就是说下拉滚动条或鼠标滚轮滚动到页面底部时才会动态即时加载下一页新内容,这就需要我们认真观察网络选项卡中页面动态加载时的变化了。
经过观察,可以看到每次加载新的图册时,都会显示有数字标记的页面请求,点击查看详情,可以看到新的页面请求,如下图所示:
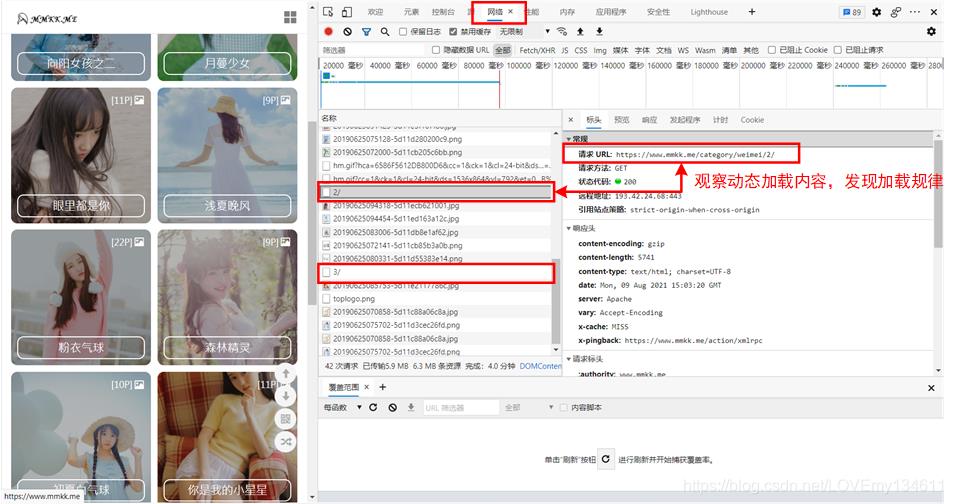
因此如果想要获取前10页的图册,可以采用如下方式构造请求页:
url_pattern = "https://www.mmkk.me/category/weimei/{}/"
for i in range(1,11):
url = url_pattern.format(i)
页面解析
第二个区别就是,此网站中的数据是直接镶嵌在页面元素中的,也就是说可以直接通过使用 BeautifulSoup 解析获取。
首先需要获取图册的地址,使用浏览器“开发者工具”,定位图册链接:
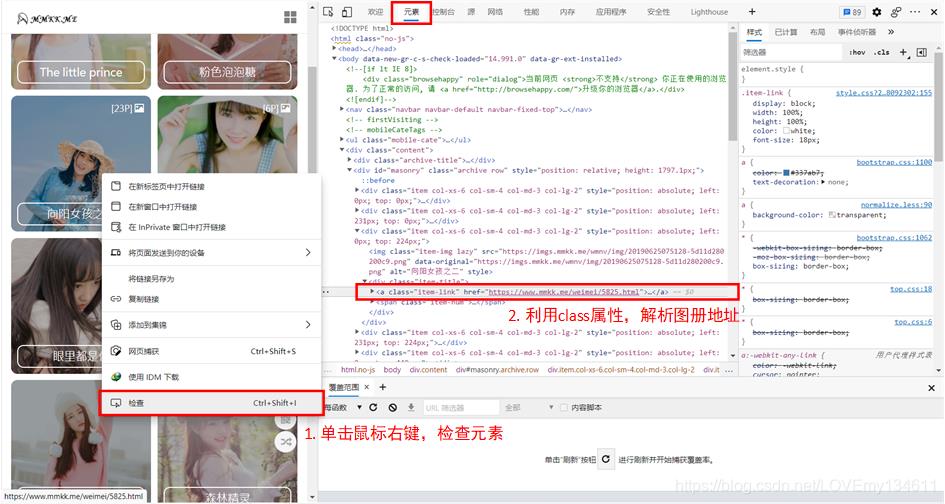
因此,例如要获取第一页中所有图册地址,可以使用如下方式:
url = url_pattern.format(1)
response = requests.get(url=url, headers=headers)
# 解码
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.find_all('a',attrs={"class":"item-link"})
# 打印查看获取的图册链接
for j in results:
print(j.attrs['href'])
# 为了对每个图册分别存储,获取每个图册的标题信息
path_name=j.get_text().strip()
打印查看获取的图册链接:
https://www.mmkk.me/weimei/5537.html
https://www.mmkk.me/weimei/5438.html
https://www.mmkk.me/weimei/5991.html
https://www.mmkk.me/weimei/6278.html
https://www.mmkk.me/weimei/5827.html
获取图册地址后,就可以请求图册页面,然后在图册中解析获取每张图片的地址(方法与解析图册地址类似):
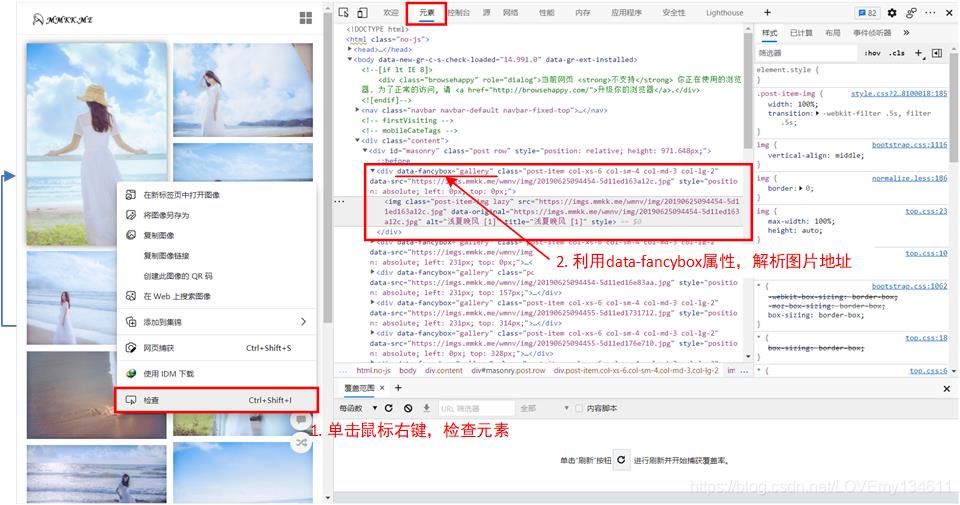
例如要获取第一个图册中所有的图片地址:
url_imgs = results[0].attrs['href']
response_imgs = requests.get(url=url_imgs, headers=headers)
# 解码
response_imgs.encoding = 'utf-8'
response_imgs.raise_for_status()
soup_imgs = BeautifulSoup(response_imgs.text, 'html.parser')
results_imgs = soup_imgs.find_all('div',attrs={"data-fancybox":"gallery"})
# 打印查看获取的图片地址
for k in range(len(results_imgs)):
print(results_imgs[k].attrs['data-src'])
打印查看获取的图片地址链接:
https://imgs.mmkk.me/wmnv/img/20190625081910-5d11d8fe5422b.png
https://imgs.mmkk.me/wmnv/img/20190625081910-5d11d8feae474.png
https://imgs.mmkk.me/wmnv/img/20190625081911-5d11d8ff282b1.png
...
创建图片保存路径
根据在页面解析中获取到图册名,创建保存路径:
if not os.path.exists(path_name):
os.makedirs(path_name, exist_ok=True)
图片下载
首先利用获取的图册名以及图片顺序,构建保存的图片名:
file_name = path_name +'_'+str(k+1)+'.png'
file_name = os.path.join(path_name, name_webp)
然后将获取的图片内容写入文件中:
# 以第一张图片为例
r = requests.get(results_imgs[0].attrs['data-src'], headers=headers)
if r.status_code == 200:
with open(file_name, 'wb') as f:
f.write(r.content)
爬取结果展示
接下来看下爬取程序结果:

完整程序
import time
import requests
from bs4 import BeautifulSoup
import os
import random
url_pattern = "https://www.mmkk.me/category/weimei/{}/"
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62',
'Connection': 'keep-alive'
}
# 爬取前5页
for i in range(1, 6):
time.sleep(10)
url = url_pattern.format(i)
response = requests.get(url=url, headers=headers)
# 解码
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# 相册链接
results = soup.find_all('a',attrs={"class":"item-link"})
# 循环所有相册链接
for j in results:
time.sleep(random.randint(8,13))
url_imgs = j.attrs['href']
# 相册名
path_name = j.get_text().strip()
# 创建图片保存路径
if not os.path.exists(path_name):
os.makedirs(path_name, exist_ok=True)
response_imgs = requests.get(url=url_imgs, headers=headers)
# 解码
response_imgs.encoding = 'utf-8'
response_imgs.raise_for_status()
soup_imgs = BeautifulSoup(response_imgs.text, 'html.parser')
# 图片链接
results_imgs = soup_imgs.find_all('div',attrs={"data-fancybox":"gallery"})
# 循环所有图片链接
for k in range(len(results_imgs)):
img = results_imgs[k].attrs['data-src']
file_name = path_name + '_' + str(k+1) + '.png'
file_name = os.path.join(path_name, file_name)
if not os.path.exists(file_name):
time.sleep(random.randint(3,8))
r = requests.get(img, headers=headers)
if r.status_code == 200:
with open(file_name, 'wb') as f:
f.write(r.content)
最后
当然网站中也包含其他分类的图册,但是我并没有点开,毕竟大家都喜欢治愈唯美系的小姐姐,如果有小伙伴对其他分类感兴趣,也可以自行修改程序.
为了给大家谋取更多福利,博主都被骂成渣男了,求求各位给个三连,不过分吧?
以上是关于渣男,你为什么有这么多小姐姐的照片?因为我Python爬虫学的好啊❤️!的主要内容,如果未能解决你的问题,请参考以下文章
迷倒小姐姐的程序员小哥亲自告诉你什么叫凭本事单身,看完我笑哭了~