爬虫学习笔记:爬取单张图片
Posted howard2005
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习笔记:爬取单张图片相关的知识,希望对你有一定的参考价值。
文章目录
一、爬取目标
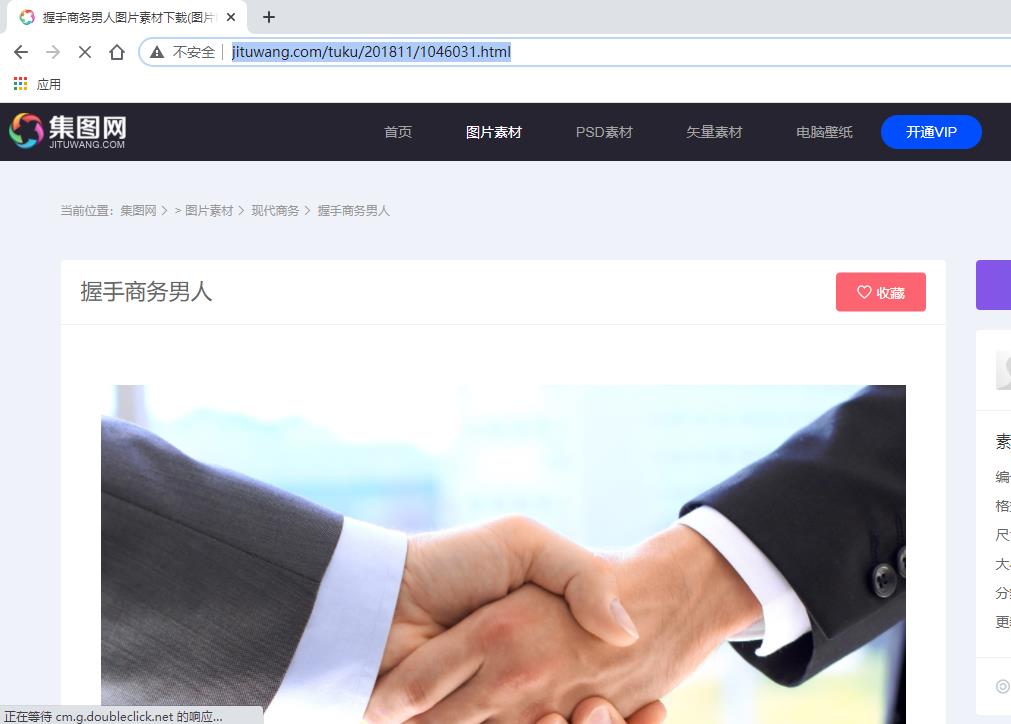
(一)网页地址
http://www.jituwang.com/tuku/201811/1046031.html
(二)网页源码
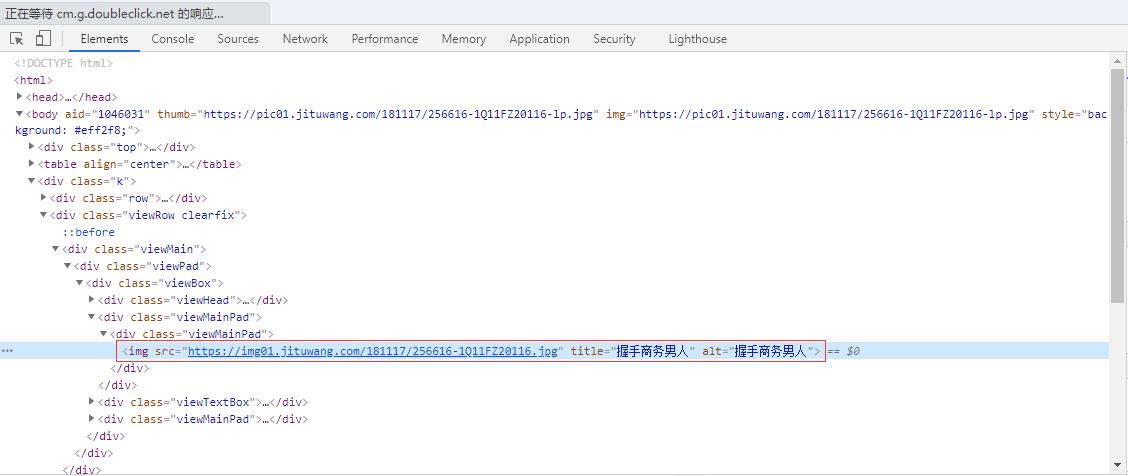
- 需要爬取图像标签
<img src="https://img01.jituwang.com/181117/256616-1Q11FZ20116.jpg" title="握手商务男人" alt="握手商务男人">的src和title属性值
二、实现步骤
- 创建Python程序 - 爬取单张图片.py
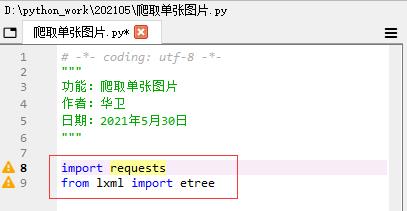
(一)导入案例所需库
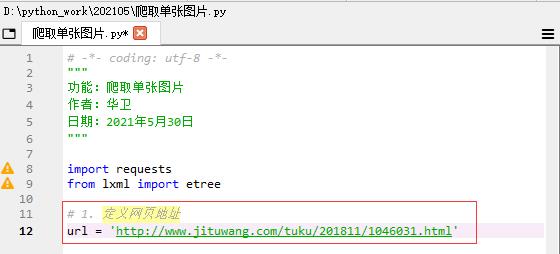
(二)定义待爬取的网页地址
(三)模拟发送请求,获取网页内容
- 运行程序,查看结果
(四)规则提取数据 - 待爬取图片的标题与网址
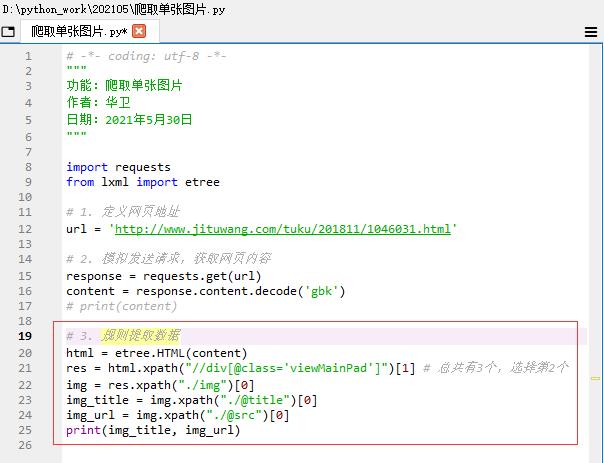
- 查看源代码,class属性为viewMainPad的div有三个,包含待爬取图片的div是第二个,因此
html.xpath("//div[@class='viewMainPad']")[1],列表下标是从0开始计数的。
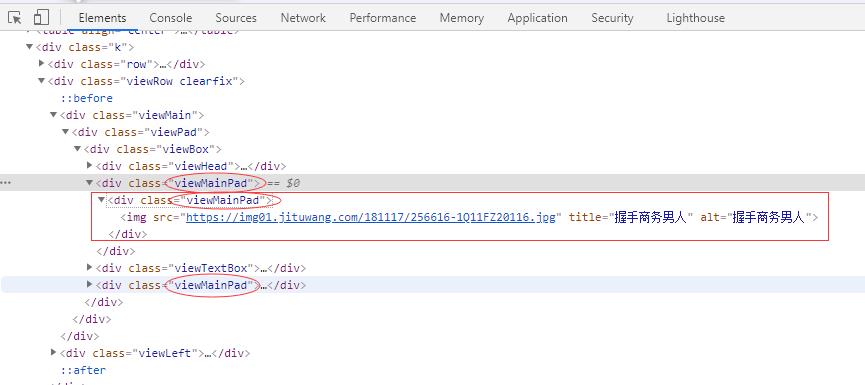
- 运行程序,查看结果

(五)下载爬取的图片并保存到本地
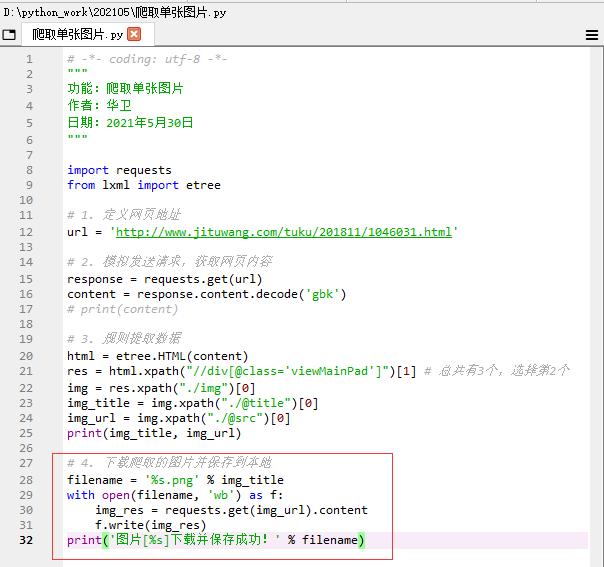
- 运行程序,查看结果

- 查看爬取的图片
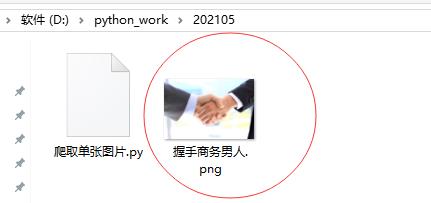
以上是关于爬虫学习笔记:爬取单张图片的主要内容,如果未能解决你的问题,请参考以下文章
Python3网络爬虫:这个帅哥肌肉男横行的世界(爬取帅哥图)