小爬虫学习——使用 requests 爬取百度图片
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小爬虫学习——使用 requests 爬取百度图片相关的知识,希望对你有一定的参考价值。
一、抓取首页图片
静态页面
流程:
1.1、找到目标数据
这里用狗的图片来举例,接下来我们就要分析然后爬取这个页面所有狗的图片的规律
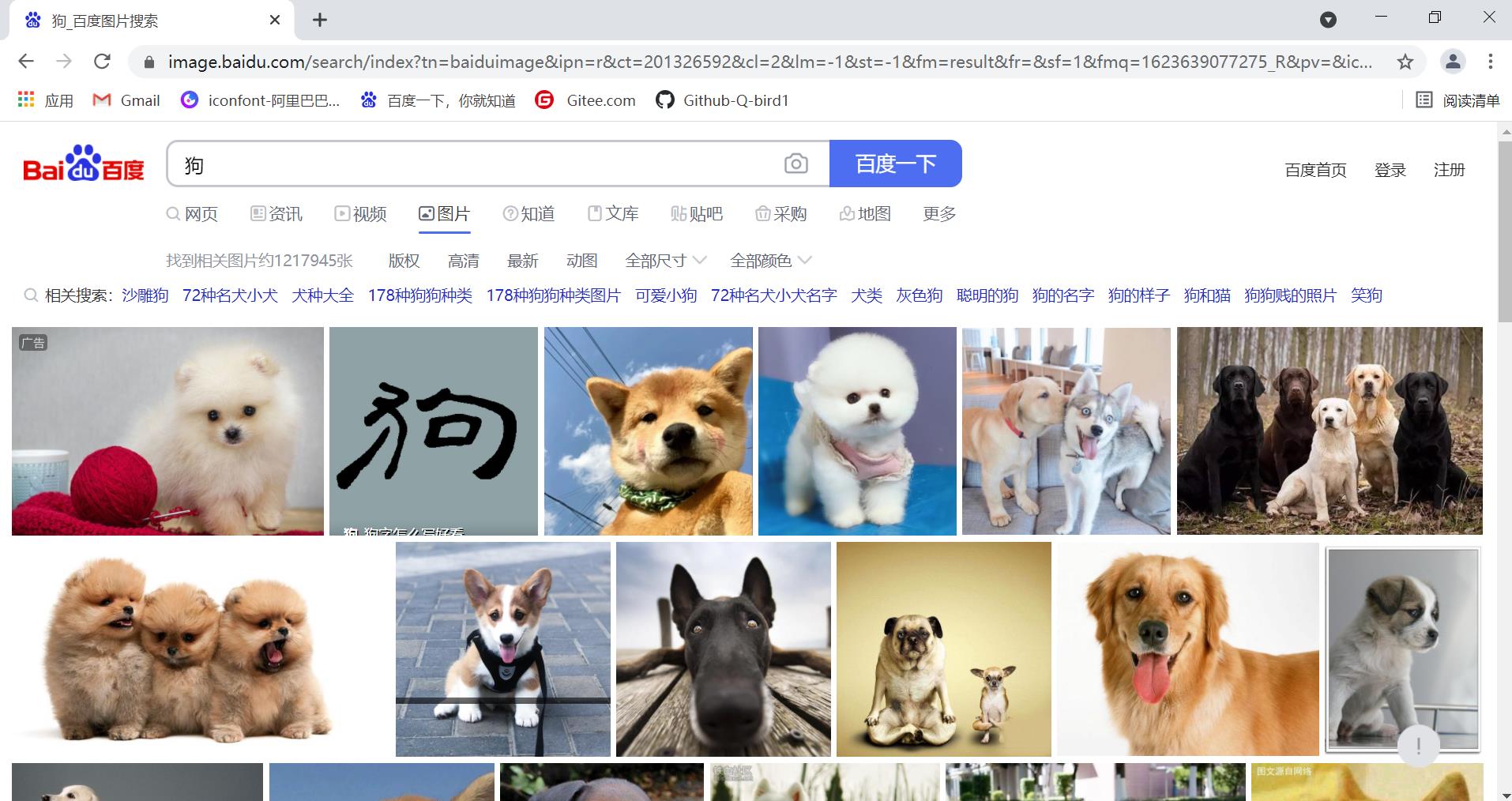
1.2、分析请求流程
先访问page页获取网页的源代码
# 网页的URL地址
url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1623639077275_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E7%8B%97'
#添加请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
#访问page页面 获取网页源代码
res = requests.get(url,headers=headers)
print(res.text)
可以观察到网页源代码的提取并不完整,因此我们可以按“F12”——NetWork——ALL——Name(排在第一个)查看到请求头,把所有的请求头内容复制到代码里(一般反爬我们有User-Agent就行,不行我们就把所有的请求头加进去)
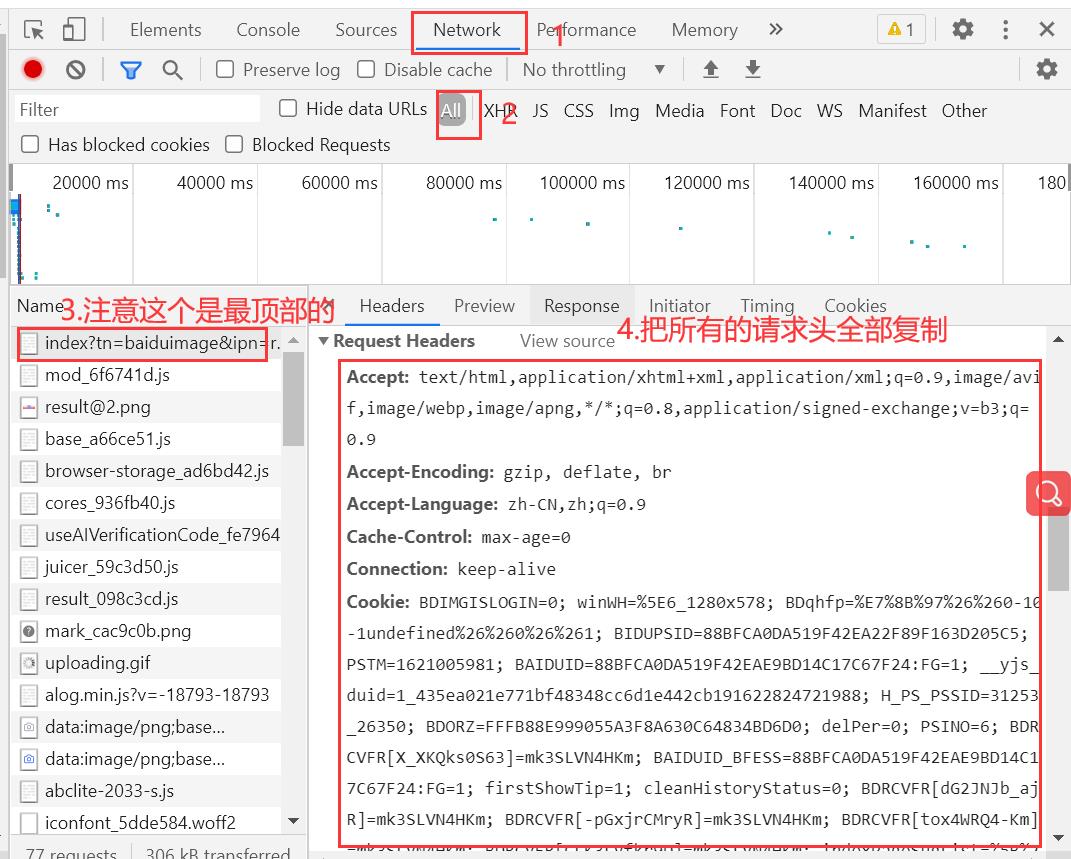
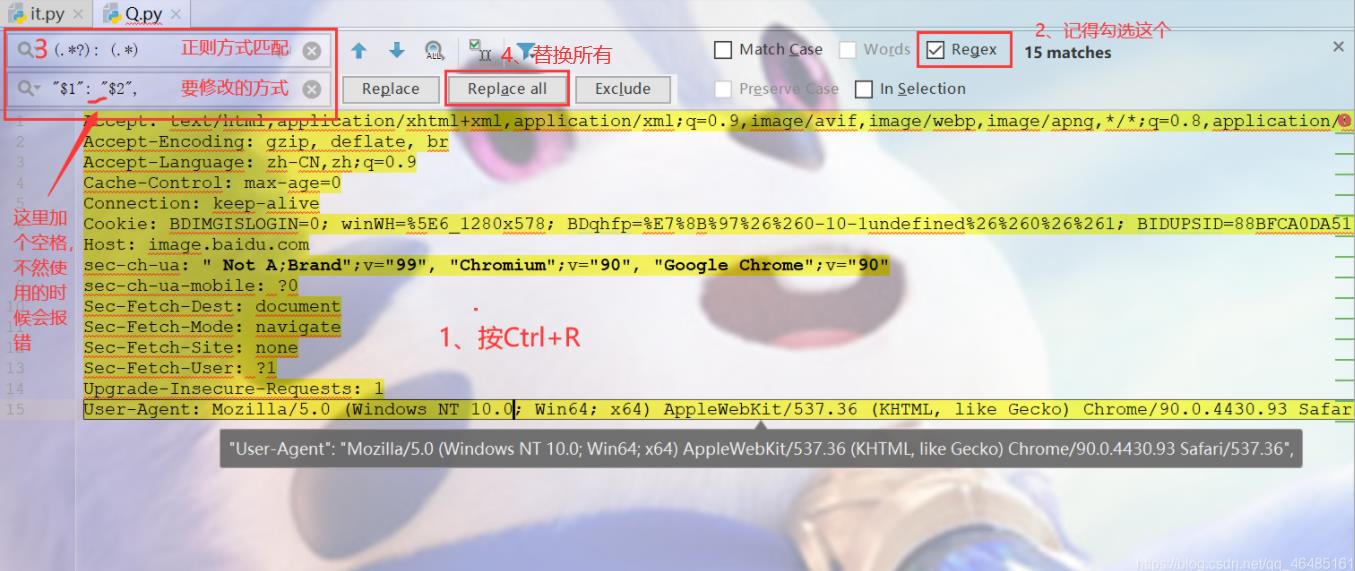
但是,每个都要改写成键值对形式有点麻烦,这里有个小技巧;
我们可以在pycharm上新建一个py文件,然后把复制的请求头放进去,按“Ctrl+R”——勾选“Regex”(这里可以让我们使用正则方式修改我们需要的内容),这样就能获取到网页的源代码了。
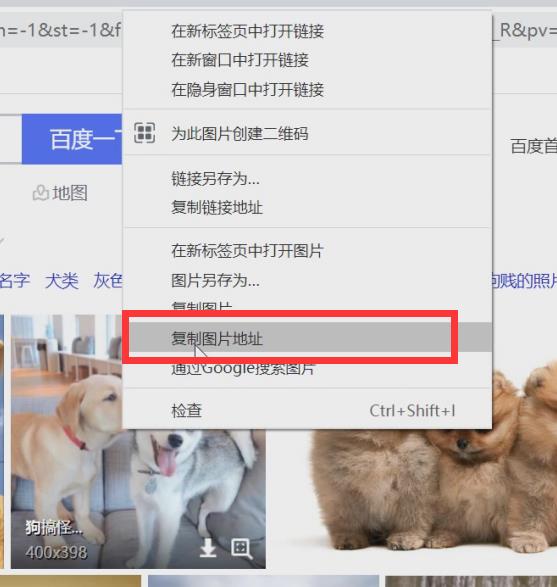
1.3、提取数据
我们先找随机找一张图片右击“复制图片地址”,然后在网页空白部分右击“查看网页源代码”,在网页源代码页面“Ctrl+F”查看它在网页源代码里是如何显示的;
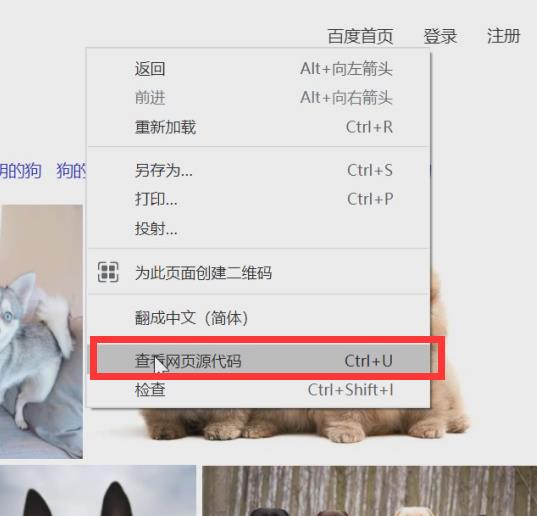
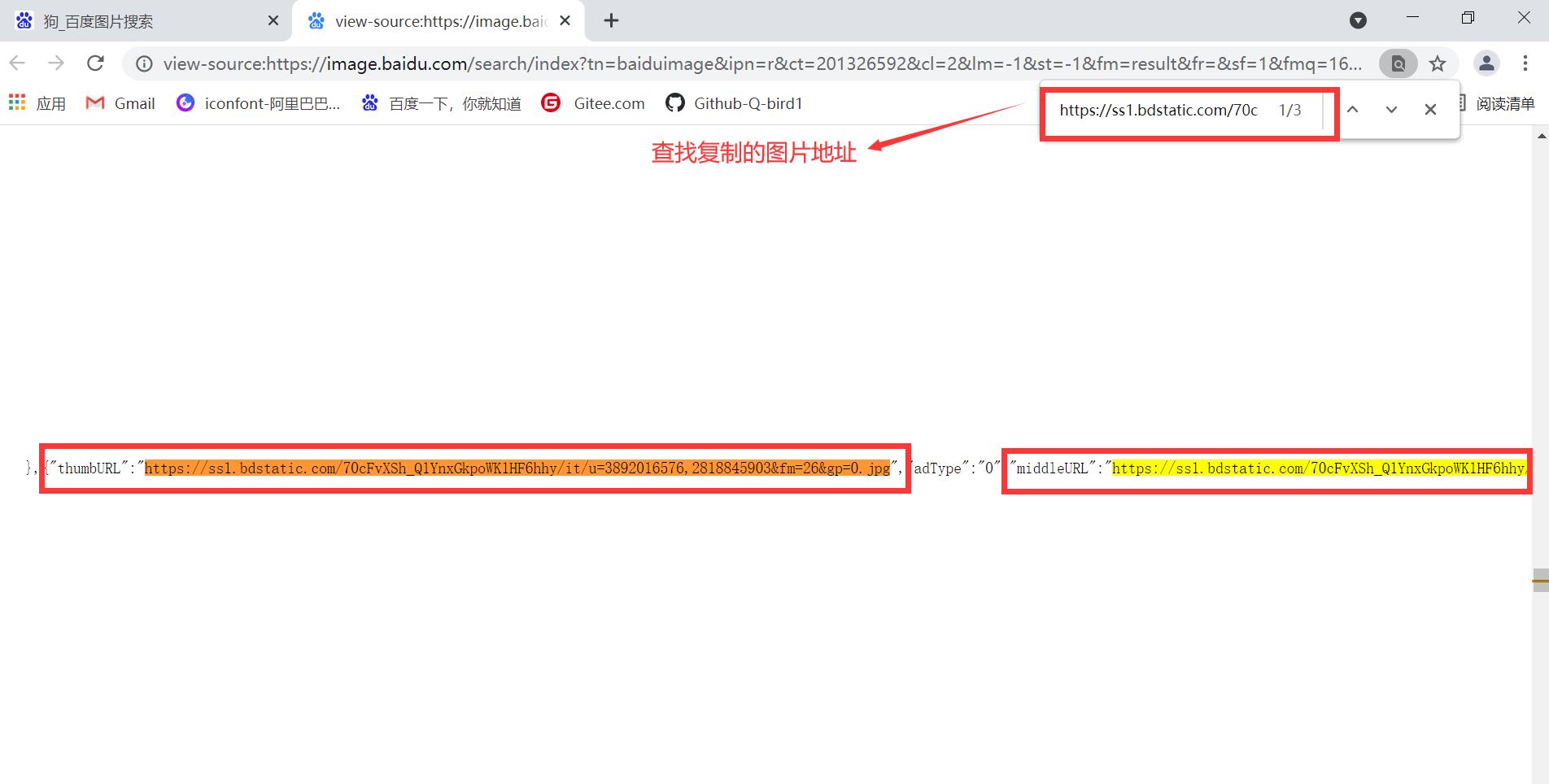
同理我们可以多找几张图片来进行比较,通过对比可得知图片加载格式有 3 种方式(找到图片之间的规律了):"thumbURL":"xxx.jpg"、"middleURL":"xxx.jpg"、"hoverURL":"xxx.jpg",接下来我们就可以通过正则表达式获取到图片的 URL 地址了,最后通过循环就可以爬取到该页面的图片了。
1.4、完整代码
import requests
import re
import os
# 网页的URL地址
url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1623639077275_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E7%8B%97'
#添加请求头
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "BDIMGISLOGIN=0; winWH=%5E6_1280x578; BDqhfp=%E7%8B%97%26%260-10-1undefined%26%260%26%261; BIDUPSID=88BFCA0DA519F42EA22F89F163D205C5; PSTM=1621005981; BAIDUID=88BFCA0DA519F42EAE9BD14C17C67F24:FG=1; __yjs_duid=1_435ea021e771bf48348cc6d1e442cb191622824721988; H_PS_PSSID=31253_26350; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; delPer=0; PSINO=6; BDRCVFR[X_XKQks0S63]=mk3SLVN4HKm; BAIDUID_BFESS=88BFCA0DA519F42EAE9BD14C17C67F24:FG=1; firstShowTip=1; cleanHistoryStatus=0; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm; BDRCVFR[CLK3Lyfkr9D]=mk3SLVN4HKm; indexPageSugList=%5B%22%E7%8B%97%22%2C%22%E6%A2%A6%E7%90%AA%22%5D; ab_sr=1.0.1_ODM0ZmQ5MDFiNzQ3MzE4NzIyMDg2MWU5NTg5MDgzNmY4OTFhODgwYjUwOWYzZGZiYjZlMTQ4YWNhZjdlMDJiMDM1YmY0NjljZDljMmU5YzM0ZDZhNWYwODIyZWFkZWZkNjcwNjFmM2UxZmU1M2NjOGQxZjc3NGNmNWE5NjA2NWVlMzhiMTlkM2IyNzBlOTgyNDBjMDhjZmEyZDFjM2QyOQ==",
"Host": "image.baidu.com",
"sec-ch-ua": '" Not A;Brand";v="99", "Chromium";v="90", "Google Chrome";v="90"',
"sec-ch-ua-mobile": "?0",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
#访问page页面 获取网页源代码
res = requests.get(url,headers=headers)
#提取数据 狗图片url
urls = re.findall('"thumbURL":"(.*?)"',res.text)
# 创建存放的图片文件夹
if not os.path.exists('images'):
os.mkdir('images')
#url发起请求,获取图片数据
for index,img_url in enumerate(urls):
# 若图片的地址中存在\\\\则替换掉
if '\\\\' in img_url:
img_url = img_url.replace("\\\\","")
res = requests.get(img_url) #res 包含 狗图片数据
#图片下载位置、及图片名称
picname = './images/'+'cat'+ str(index) +'.png'
print(picname)
with open(picname,'wb') as f:
f.write(res.content)
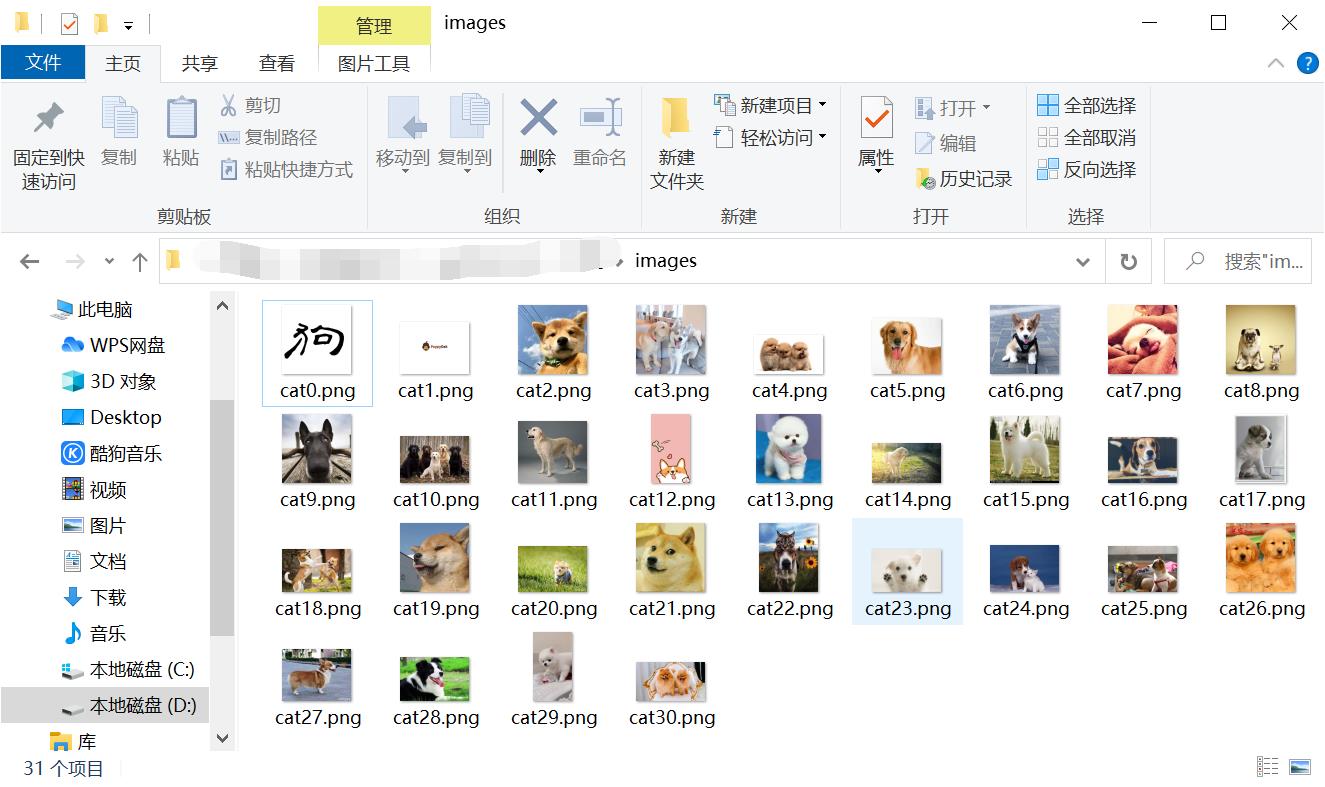
结果:
二、抓取多页图片
还是以狗的图片为例,当我们鼠标往下滑的时候,我们会发现会有图片不断加载出来,其实这已经是加载到下一页了。那如果我们不仅想爬第一页图片,还想爬第二页、第三页呢?
2.1、分析请求流程
构造page页,即找到多个page页之间的规律
首先,按“F12”——点击“NetWork”——点击“XHR”,然后随着鼠标滚轮不断的往下,我们可以看到各个页面的网页源代码被加载出来。
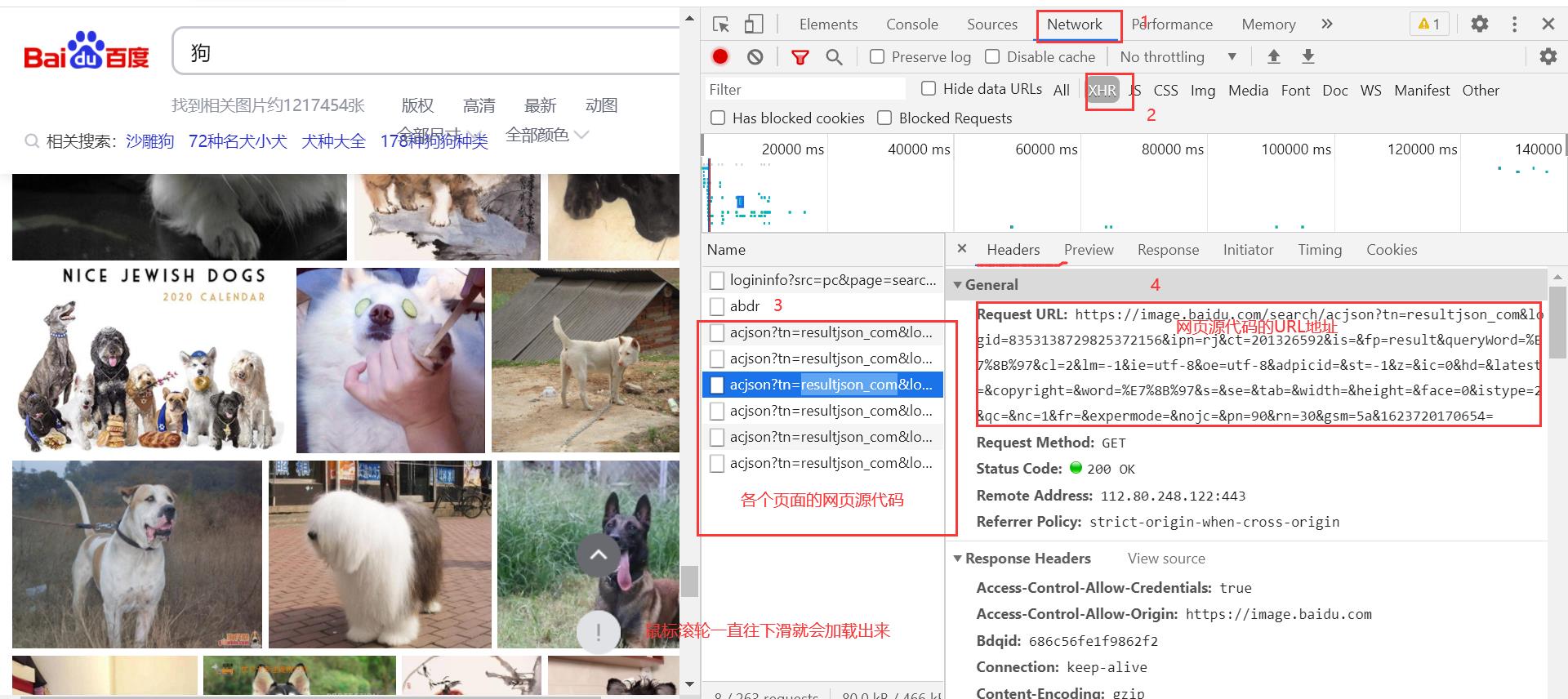
接下来我们可以复制几个网页页面的URL地址进行比价找出它们之间的规律
https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8353138729825372156&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%8B%97&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E7%8B%97&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&nojc=&pn=90&rn=30&gsm=5a&1623720170654=
https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8353138729825372156&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%8B%97&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E7%8B%97&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&nojc=&pn=120&rn=30&gsm=78&1623720170795=
(这里我只列举了两个,要比较的话最好多找几个)通过比较我们可以看出只有后面部分存在差异,&pn后数值相差是 30 的倍数,其他的数值差异不影响结果(这个有兴趣的可以自己去尝试),因此我们就可以通过修改 &pn 后的值来获取多个网页
&pn=120&rn=30&gsm=78&1623720170795= #就&pn开始往后存在差异
接下来,就是找一个网页进行图片分析(这里 分析过程上面已经讲了)
2.2、完整代码
import requests
import re
import os
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
def getimg(urls,filename):
"""
功能:获取百度图片,存储到文件夹
参数:
img_urls:图片url列表
filename:图片存储文件夹
"""
for index,img_url in enumerate(urls):
if '\\\\' in img_url:
img_url = img_url.replace('\\\\',"")
# url发起请求,获取图片数据
res = requests.get(img_url, headers=headers)
picname = filename+'/'+'dog'+str(index)+'.png'
print(picname)
with open(picname,'wb') as f:
f.write(res.content)
for i in range(1,4):
url = "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8443544291319646945&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%8B%97&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E7%8B%97&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&nojc=&pn={0}&rn=30&gsm=1e&1623687251585="
index = i*30
url = url.format(index)
res = requests.get(url,headers=headers)
#提取数据 狗图片url
img_urls = re.findall('"thumbURL":"(.*?)"',res.text)
# 创建存放的图片文件夹
filename = 'dog'+str(i)+'.png'
if not os.path.exists(filename):
os.mkdir(filename)
getimg(img_urls,filename)
结果:
以上是关于小爬虫学习——使用 requests 爬取百度图片的主要内容,如果未能解决你的问题,请参考以下文章