数值分析×机器学习稀疏矩阵向量乘(SpMV)的运行时间预测(有点意思)
Posted 囚生CY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数值分析×机器学习稀疏矩阵向量乘(SpMV)的运行时间预测(有点意思)相关的知识,希望对你有一定的参考价值。
- 英文标题:Performance Modeling of the Sparse Matrix-vector Product via Convolutional Neural Networks
- 中文标题:稀疏矩阵向量积的卷积神经网络性能建模
- 论文下载链接:DOI@10.1007
- 项目代码地址:GitHub@SpMV-CNN
序言
这其实是一件很有趣的事情,假设 A ∈ R m × n A\\in\\R^{m\\times n} A∈Rm×n,以及 x ∈ R n x\\in\\R^n x∈Rn,现在想要计算 A x Ax Ax,显然我们正常来算的话需要进行 m n 2 mn^2 mn2次乘法,并且需要 x x x中的每个元素需要被重复检索 m m m次。
现在有一个好消息和一个坏消息:
- 好消息是矩阵 A A A一定会是一个稀疏矩阵;
- 坏消息是我们并不知道 A A A到底是怎么个稀疏法,非零元的位置每次来得都千奇百怪,且 m m m和 n n n都大的离谱;
于是问题就来了,既然是一个稀疏矩阵,我们当然不需要总是重复的检索 x x x的每个位置的元素(只需要检索矩阵 A A A中非零元所在列索引对应的 x [ i ] x[i] x[i]即可),并且如果我们可以做缓存的话,就可以大大地加快运算速度。
可惜因为上面那个坏消息,我们并不知道 x [ i ] x[i] x[i]在被用了一次后,到底还会何时再被用到(非零元分布不规则),因此如果做了缓存,可能也只是增大空间开销,得不偿失。
这件事情其实再【数值分析×机器学习】使用CNN进行雅可比预条件子的生成(烦)给出了一个办法,就是将稀疏矩阵转换成雅可比快,因为同一个雅可比块内的非零元相对集中,这样就使得缓存命中率大大提高,运算速度就会提升。
本文却做了一个看起来很奇怪的任务,就是去预测某个稀疏矩阵 A A A在给定的硬件环境下到底做 A x Ax Ax需要运算多长时间。但是这个任务还是很有意义的,这至少可以做一个先验,如果时间太久的话可能就会需要一些预条件子的介入,如果不久的话就可以省略预处理的步骤。
总的来说其实还是个挺简单的事情,可以考虑做这个方向。
P S \\rm PS PS:
开始进入无事一身轻的状态。可惜天真的热,跑不动了,好在月头已经分别完成 10 k m 10\\rm km 10km p b \\rm pb pb和历史第三长的耐力跑了,好好休整吧。
搞个运动手环,看看自己心肺承受的极限在哪里。
今天还是没忍住中午去 801 801 801看了一下,其实只是想去隔壁休息室开空调躺沙发睡一觉,离开时路过 801 801 801还是无可避免地看到了,天热了还是那件衣服。
唉,眼不见心不烦吧,也见不到几次了。
摘要 Abstract
- 对稀疏矩阵向量乘法(sparse matrix-vector multiplication,下简称为SpMV)在目前的CPU架构上进行建模是非常复杂的,原因有以下三点:
- 非常规的内存访问(irregular memory accesses);
- 间接的内存查询(indirect memory referencing);
- 低算术强度(low arithmetic intensity);
- 虽然解析模型(analytical models)可以生成缓存命中与丢失(cache hits and misses)的精确估计,但是这些模型往往无法精确预测总运行时间。
- 本文利用卷积神经网络(convolutional neural networks,下简称为CNNs)来提供对于SpMV运算操作性能的有效估计(区别于传统的解析方法)。
- 本文针对问题矩阵(problem matrix)展示一种稀疏模式(sparsity pattern)的高级抽象概念(high-level abstraction),并提出一个块级的策略(blockwise strategy)给CNNs模型进行输入(即输入一块块非零的元素)。
- 本文的实验评估是基于SuitSparse Matrix数据集进行的训练与测试,实验结果表明CNNs模型在预测SpMV上的性能具有鲁棒性。
- 关键词:
- 稀疏矩阵向量乘法(Sparse matrix–vector multiplication,SpMV);
- 性能建模(Performance modeling);
- 监督学习(Supervised learning);
- 卷积神经网络(Convolutional neural networks,CNNs);
引入 Introduction
-
SpMV是科学计算与工程应用中常常进行的操作,如在稀疏线性系统的迭代求解算法(如 GMRES \\text{GMRES} GMRES,共轭梯度)中就会大量涉及稀疏矩阵的运算。一些在数据分析处理中的应用,比如网页搜索引擎,信息检索等。
-
备注:
这里其实倒是和自然语言处理(Natural Language Processing,下简称为NLP)有点关联,简单举例比如给定一个文档库的词袋(wordbag)矩阵(即正向索引),即标注每个单词在每个文档中的出现次数,这样一个矩阵一般来说会是一个非常稀疏的矩阵,因为常用单词是非常少的,一般来说这种矩阵中非零元的数量不到 1 % 1\\% 1%,一些相关的训练矩阵与测试矩阵可以在LIBSVM Data: Regression上找到,比如链接页面上的E2006-tfidf数据集就是一个非常典型的稀疏矩阵,如果我们在这种大规模的稀疏矩阵上执行最小二乘的迭代求解算法,如果使用矩阵的全量表示,一般来说是不太切实际的。
-
-
上述这些应用中,SpMV核是时间耗用最大的一个元素,如何估计SpMV的执行时间是困难的,难点正如摘要中提到的那样,这里做进一步的解释:
-
非常规的内存访问(irregular memory accesses);即低时间局部性(low temporal locality);
-
间接的内存查询(indirect memory referencing);即低空间局部性(local spatial locality);
-
低算术强度(low arithmetic intensity);
The arithmetic intensity is defined as the ratio of total floating-point operations to total data movement (in bytes)
-
备注:
关于时间局部性与空间局部性的定义可以参考时间局部性和空间局部性;
在CPU访问寄存器时,无论是存取数据抑或存取指令,都趋于聚集在一片连续的区域中,这就被称为局部性原理。
- 时间局部性:被引用过一次的存储器位置在未来会被多次引用。
- 空间局部性:如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
这个东向似乎很难理解,笔者是这样理解的,下面是一个生成 1000 × 1000 1000\\times 1000 1000×1000的稀疏矩阵 X X X(稠密度为 1 % 1\\% 1%):
import numpy as np import scipy.sparse as ss import matplotlib.pyplot as plt num_col = 1000 num_row = 1000 num_ele = 10000 a = [np.random.randint(0, num_row) for _ in range(num_ele)] b = [np.random.randint(0, num_col) for _ in range(num_ele - num_col)] + [i for i in range(num_col)] c = [np.random.rand() for _ in range(num_ele)] rows, cols, v = np.array(a), np.array(b), np.array(c) sparseX = ss.coo_matrix((v,(rows,cols))) X = sparseX.todense() print(sparseX.shape) print(sparseX.count_nonzero()) print((np.dot(sparseX.T, sparseX).count_nonzero()))笔者想测试的事情是 X ⊤ X X^\\top X X⊤X中稠密度如何,多次测试之后会发现 X ⊤ X X^\\top X X⊤X中包含的非零元大约是 X X X中非零元的 10 10 10倍,即稠密度为 10 % 10\\% 10%左右,这个事情就很有意思了,SpMV可能会使稀疏矩阵变得不稀疏,这种现象是很不好的,因为会极大的增加内存占用。而稀疏矩阵的全量表示在存储空间上是很不连续的,且很可能在多次运算迭代后稀疏矩阵的样子会变得很大(非零元位置变化),这可能是上述低时间局部性与低空间局部性的一种理解。
看到后面笔者又有了新的理解,考察 y = A x y=Ax y=Ax,其中 A A A是一个稀疏矩阵,那么事实上在做乘法时相当于是将矩阵 A A A的每一行与 x x x相乘,因此 x x x会被频繁的查询,但是我们不可能说将 x x x的每一个元素都缓存,只有那些一段时间内被经常用到的 x [ i ] x[i] x[i]才会被缓存,但是由于稀疏矩阵实在是太不规则,每一行的非零元位置迥异,因此很多时候缓存的 x [ i ] x[i] x[i]很久都没有被用到,然后就被丢弃了,或者就是过了很久才被用到,那时候已经不在缓存中了。其实上一篇雅可比预条件子就是将稀疏矩阵转换为块状,这样就可以使得缓存命中的几率大大增加,因为同一雅可比块是相邻的若干行,这些行的非零元位置是相似的。
-
-
相关研究:
-
参考文献 [ 3 ] [ 4 ] [3][4] [3][4]发现典型的序列式SpMV实现方法总体上不超过商用微处理器上的机器峰值浮点速率的 10 % 10\\% 10%(就是很慢呗);
最好的情况下,SpMV在FP32上的算法强度为 0.5 0.5 0.5,这意味着算法性能主要受制于目标频台的峰值内存带宽(peak memory bandwidth);
其他对SpMV的性能有贡献的是非零稀疏模式(nonzero sparsity pattern)与稀疏矩阵的行密度(row-density in the sparse matrix);
-
参考文献 [ 5 ] [ 6 ] [ 7 ] [5][6][7] [5][6][7]对SpMV的性能进行建模,这些解析式的模型,常常依赖于简化缓存替代策略与算法开销,总体上只能提供算术运算和内存占用的理论估计;
-
参考文献 [ 8 ] [8] [8]指出这些分析需要对处理器有较深的理解以及对于SpMV的实现有详细地分析;
-
-
本文希望通过机器学习方法来(具体而言即使用CNNs)来捕获空间依赖与时间依赖;具体而言:
- 使用CNNs来对SpMV的执行时间进行建模(硬件为Intel Xeon core,存储格式为CSR);
- 使用块级实现(blockwise realization)来使得CNNs模型架构可以独立于稀疏矩阵的维度,从而有利于增加训练集与验证集的样本容量;
- 对基于CNNs的模型进行精确度评估以及鲁棒性论述,测试集来自真实应用(SuiteSparse Matrix collection)中的一个代表子集(representative subset);
- 将CNNs模型移植到ARM架构上对该模型的可扩展性进行了评估;
2 背景 Background
本节简要回归SpMV核(kernel)以及CNNs的一些知识,这些概念是本文提出的用于估计SpMV时间耗用的CNNs模型的基础。
2.1 稀疏矩阵向量乘积 The sparse matrix-vector product
-
考察SpMV运算: y = A x y=Ax y=Ax,其中 A ∈ R m × n A\\in\\R^{m\\times n} A∈Rm×n是稀疏矩阵,其中包含 n n z nnz nnz个非零元;
x ∈ R n × 1 x\\in\\R^{n\\times1} x∈Rn×1是一个稠密的输入向量, y ∈ R m × 1 y\\in\\R^{m\\times 1} y∈Rm×1是稠密的输出向量;
一般来说矩阵 A A A会以压缩格式存储,比如压缩稀疏行(Compressed Sparse Row,下简称为CSR),压缩稀疏列(Compressed Sparse Column,下简称为CSC),以及COO或ELLPACK等,本文使用的压缩格式为CSR,如 Figure 1 \\text{Figure 1} Figure 1所示:
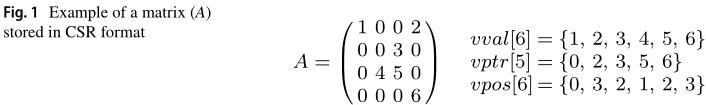
- v v a l vval vval数组长度为 n n z nnz nnz,按照行优先的顺序依次记录所有非零元的数值;
- v p t r vptr vptr数组长度为 n + 1 n+1 n+1, v p t r [ i + 1 ] − v p t r [ i ] vptr[i+1]-vptr[i] vptr[i+1]−vptr[i]的数值代表第 i i i行有多少个非零元;
- v p o s vpos vpos数组长度为 n n z nnz nnz,记录每个非零元的列索引;
备注:暂时没有搞明白 n n z nnz nnz是什么东西,可能是作者勘误。好了,搞明白了,就是 number of nonzeros \\text{number of nonzeros} number of nonzeros的意思… 艹
-
Algorithm 1 \\text{Algorithm 1} Algorithm 1中展示了CSR的存储格式下SpMV核的实现:(其实就是怎么计算 y = A x y=Ax y=Ax)

2.2 卷积神经网络 Convolutional neural networks
本节内容略,主要是在讲卷积神经网络的最基础的知识,没有提到在数值计算领域的应用。
3 使用卷积神经网络建模稀疏矩阵向量乘法 Modeling SpMV using CNNs
- SpMV的内存受限(memory-bound)本质是源于矩阵 A A A中低密度的非零元以及不规则的稀疏模式(irregular sparsity patterns),从而导致大量的缓存丢失(cache misses)。
- 考虑到这一点, v p o s vpos vpos数组就显得非常重要(因为它存储了每个非零元的列索引,对应的就是 x x x的索引,我们期望能够将那些列索引相似的行集中到一起处理,这样对 x x x的缓存就变得有意义了)。
- 我们期望通过CNNs可以捕获到 v p o s vpos vpos数组中有用的特征,比如非零元之间距离的模式(pattern),这就可以通过每秒浮点运算速度/每秒峰值速度(float-point operations per second,下简称为FLOPS)与缓存命中/丢失(cache hits/misses)之间的关系生成对于SpMV的性能评估。
3.1 方法论 Methodology
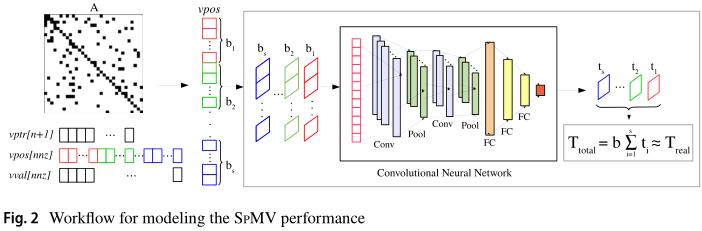
-
Figure 2 \\text{Fig
以上是关于数值分析×机器学习稀疏矩阵向量乘(SpMV)的运行时间预测(有点意思)的主要内容,如果未能解决你的问题,请参考以下文章