数值分析×机器学习以SVD的分解形式进行深度神经网络的训练(逐渐熟练)
Posted 囚生CY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数值分析×机器学习以SVD的分解形式进行深度神经网络的训练(逐渐熟练)相关的知识,希望对你有一定的参考价值。
- 英文标题:Learning Low-rank Deep Neural Networks via Singular Vector Orthogonality Regularization and Singular Value Sparsification
- 中文标题:学习低秩深度神经网络通过奇异向量正交正则化与奇异值稀疏化
- 论文下载链接:arxiv@2004.09031v1
- 论文项目地址:暂时没找到
序言
写proposal前的最后一篇paper,这部分内容还是很有意思的,很开拓思路,值得深究。
其实一共是看了四篇,前两篇的笔注:
第三篇因为太短我放在本文最后做个收尾,这个第四篇很有东西,可惜没能找到项目地址,不知道具体代码实现情况如何。
总之利用这些数值分析的方法来优化DNNs确实是一条很有趣的道路。
Prescript \\text{Prescript} Prescript
好天气碰上休假,手环刚到,去试个半马,晚上开写proposal,到底还是这样平淡的生活比较适合我,其实现在一个人待在空屋里还是会有点躁动,从俭入奢易,由奢入俭难,体验过两个人的生活,总是就很难一下子再习惯孤独,不过倒也无妨,这种日子我也不是第一次过了,人总归还是要做回自己才行。
应当期待好的事情终会发生。
文章目录
摘要 Abstract
-
深度神经网络(deep neural networks,下简称为DNNs)需要大量的算力成本,所以为了使得DNNs能够在移动设备上使用,一系列诸如因子化(factorization)的方法已经得到了广泛的应用。
所谓因子化即将DNNs模型中网络层的权重矩阵分解为若干低秩矩阵的乘积,然而在模型训练过程中往往很难衡量矩阵的秩。
因此前人的工作主要是在模型训练的每一步中引入间接近似(implicit approximations)或高成本的奇异值分解(singular),前者往往会导致较高的训练损失,后者则运行效率很低。
-
本文结合两种方法的优势,提出奇异值分解训练(SVD training)的方法概念,这是目前第一种无需在训练中采用SVD即可直接取得低秩DNNs的方法。
SVD训练首先将每个网络层的权重矩阵分解成满秩SVD的形式,然后直接就可以在分解得到的一系列权重矩阵上进行训练。
-
备注:满秩SVD应该就是thin SVD的意思,即 A = U D V ⊤ A=UDV^\\top A=UDV⊤,其中 D = R rank ( A ) × rank ( A ) D=\\R^{\\text{rank}(A)\\times\\text{rank}(A)} D=Rrank(A)×rank(A)
修正:满秩SVD就是不省略任何奇异值的分解,因为 A = ∑ i = 1 rank ( A ) σ i u i v i ⊤ A=\\sum_{i=1}^{\\text{rank}(A)}\\sigma_iu_iv_i^\\top A=∑i=1rank(A)σiuivi⊤,这就是满秩分解,如果求和项只取到前 k k k项,即只取前 k k k大的奇异值,就是近似分解。
-
-
本文在奇异值向量中加入正则化(regularization),从而确保SVD的形式有效(valid form),且可以避免梯度消失或梯度爆炸(gradient vanishing/exploding)。低秩可以通过对每个网络层应用稀疏导出正则器(sparsity-inducing regularizers)来促成。最后会采用奇异值剪枝(Singular value pruning)来直接得到一个低秩模型。
-
本文经验性地(empirically)证明SVD训练可以显著地减小DNNs网络的秩,并且与目前常规的因子化方法以及先进的过滤剪枝方法(filter pruning methods)可以在相同的精确度下大大减少算力开销。
1 引入 Introduction
-
DNNs的高性能的背后是极高的内存占用与计算负载:
如 ResNet-50 \\text{ResNet-50} ResNet-50模型大约需要 4G \\text{4G} 4G次浮点运算(floating-point operations,下简称为FLOPs)来分类一张 224 × 224 224\\times224 224×224像素的图片。这是制约DNNs模型在移动智能设备上运行的主要原因。
-
DNNs模型的压缩技术的相关研究:
- 参考文献 [ 7 , 21 , 38 ] [7,21,38] [7,21,38]:元素级别的剪枝(element-wise pruning);
- 参考文献 [ 33 , 25 , 20 ] [33,25,20] [33,25,20]:结构化剪枝(structural pruning);
- 参考文献 [ 23 , 31 ] [23,31] [23,31]:离散化(quantization);这个可以参考二进制的嵌入,应该算是一种离散化方法。
- 参考文献 [ 15 , 39 , 36 , 35 ] [15,39,36,35] [15,39,36,35]:因子化(factorization);
方法 1 1 1和 3 3 3可以有效地减少模型的内存占用,但是需要特殊的硬件来实现高效的计算。
方法 2 2 2是通过移除冗余的filters和channels来减少计算负载,但是这种方法可能会导致移除后相邻网络层的输出输入无法衔接,因此是需要一些调整技巧的。
方法 4 4 4即使用若干低秩矩阵的乘积来近似权重矩阵,这种方法天然地可以保持网络层输入输出的维度。
- 备注:关于结构化剪枝可以参考文章,综合写了多篇与结构化剪枝相关的问题,其实就是丢掉一些冗余的网络层。
-
权重矩阵近似的相关研究:
-
参考文献 [ 15 , 39 , 26 , 4 , 19 ] [15,39,26,4,19] [15,39,26,4,19]:使用预训练的DNNs模型生成低秩矩阵的乘积来近似权重矩阵,但是这些方法基变通过了后微调,仍然会严重损害原模型的性能。
-
参考文献 [ 34 , 20 ] [34,20] [34,20]:调整filters的方向(directions)来间接地给权重矩阵降秩,但是训练地困难性以及以及矩阵秩的隐含性(implicitness)使得这些方法很难取得一个较高的压缩率。
-
参考文献 [ 1 , 35 ] [1,35] [1,35]:使用矩阵的核模(nuclear norm)来作为衡量矩阵秩的依据,但是优化矩阵的核模的效率是很低。
- 备注:关于矩阵的核模,定义为 ∥ X ∥ ∗ = tr ( X ⊤ X ) = ∑ i X ∣ σ i ∣ \\|X\\|_*=\\text{tr}\\left(\\sqrt{X^\\top X}\\right)=\\sum_{i}^{\\text{X}}|\\sigma_{i}| ∥X∥∗=tr(X⊤X)=∑iX∣σi∣,即所有奇异值绝对值的加和。
-
-
本文的研究:
-
本文旨在直接在模型训练过程中获得一个低秩DNNs模型,而无需在训练的每一步采用SVD;
-
本文提出SVD训练的方法,通过训练得到每一层的权重矩阵的满秩SVD形式,权重矩阵分解为左奇异向量,奇异值和右奇异向量,然后训练的目标就是这些分解得到的变量。
- 备注:这里的意思应该是说神经网络的训练是基于这些分解得到的矩阵进行的,而不是直接用权重矩阵介入网络的训练,其实这件事情应该是可行的,虽然笔者还没有看到下面,但是本身来说你可以理解为是把一个网络层分解成三个低秩的网络层,这个其实并不影响神经网络的反向传播,然后在定义损失函数的时候把这些网络层和秩相关的数字给加进去就可以了。
-
进一步地,本文在SVD训练中提出两种技术用于在保持高性能,且可以导出低秩性:
-
奇异向量正交正则化(singular vector orthogonality regularization):可以使得奇异向量矩阵在训练过程中尽可能地接近正交矩阵(unitary),这样可以缓和模型训练中梯度消失与梯度爆炸的问题,且可以确保最后得到的SVD形式是合理的,可以用于降秩。
-
奇异值稀疏化(singular value sparisification):在模型训练中将稀疏导出正则器(sparsity-inducing regularizers)应用在奇异值上,从而得到低秩矩阵。最终低秩模型是通过奇异值剪枝(singular value pruning)。
-
-
本文对每一种技术都进行了评估(通过消融实验),结果表明本文在提出的方法在各种任务与模型架构上都击败了先进的因子化以及结构化剪枝方法。
-
就我们所知,这是第一个用来对每个DNNs网络层在训练过程中(无需进行矩阵分解)对最优秩进行搜索的方法。
-
2 低秩深度神经网络的相关工作 Related Works on Low-rank DNNs
使用低秩矩阵的乘积来近似权重矩阵是压缩DNNs模型的一个非常直接的想法,前人的工作主要集中在设计矩阵或张量分解的架构。
- 参考文献 [ 19 ] [19] [19]:对四维卷积核张量的分解研究。如张量秩分解(CPD),可以将四维卷积核直接分解为四个低秩的卷积层。
- 备注:CPD这个词我第一次是在RE2RNN那篇paper里碰到的,在那篇博客里有关于CPD的详细说明,对于三维张量的CPD应该是会分解成三个二维矩阵,但是对于四维张量的话,分解得到的矩阵数量可能会非常多。
-
参考文献 [ 29 ] [29] [29]:上述张量分解技术会使得模型中网络层的数量变得非常多,因此很难通过微调得到很好的性能,尤其是对又大又深的模型进行分解时。
-
参考文献 [ 39 ] [39] [39]:因此后续有学者研究如何将一个四维张量重构(reshape)成一个二维矩阵,然后再使用针对二维矩阵的分解方法(如SVD),最终再把分解得到的合成结果再重构回四维张量,得到两个连续的网络层(consecutive layers)。在这篇参考文献中,作者提出channel级别的分解(channel-wise decomposition),使用的是SVD来分解卷积层(卷积核的大小维 w × h w\\times h w×h)得到两个连续的网络层(大小分别为 w × h w\\times h w×h和 1 × 1 1\\times1 1×1),然后通过考察channel级别上的冗余(redundancy),如那些带有较小奇异值的channel就可以被移除。
- 备注:channel在卷积层中一般指图片的通道数,如RGB格式的图片通道数为 3 3 3,RGBA的通道数则为 4 4 4。filter在卷积层中就是卷积核的意思,如果channel数大于 1 1 1,则就是channel数个卷积核的整体称为filter。
-
参考文献 [ 15 ] [15] [15]:作者类似地也提出一种将卷积层分解成两个连续的网络层的方法,且这两个连续的网络层之间的channel数更少,然后再进一步地利用空间级别的(spatial-wise)冗余来减少卷积核的大小,最终得到的分解网络层的大小分别是 1 × h 1\\times h 1×h和 w × 1 w\\times1 w×1。这里作者提到说可以在得到满秩分解后手动地选取若干较大的奇异值得到最终的近似结果,但是这样无可避免地会导致较高地精确度损失,虽然压缩率会提升。
一些其他研究着重于如何在降秩的前提下,还能保证模型的精确度损失不会太大。
-
参考文献 [ 34 ] [34] [34]:采用attractive force正则器来提高某一网络层中不同filters的相关性(correlation)。
-
参考文献 [ 5 ] [5] [5]:采用centripetal SGD,将多个filters移向一套聚合中心。(不懂,要看原文才行)
这两种方法都可以减少权重矩阵的秩,而无需在训练中进行低秩分解。
但是在这两种方法中矩阵的秩都是间接表示的(不知道是什么间接表示),因此正则化的效用的很弱的,可能会导致模型性能骤降(因为追求高处理速度)
-
参考文献 [ 1 , 35 ] [1,35] [1,35]:使用核模(即所有奇异值绝对值的加和)来表示矩阵的秩,这些方法需要进行SVD,算法复杂度为 O ( n 3 ) \\mathcal{O}(n^3) O(n3),且梯度下降法不能直接作用在SVD上(参考文献 [ 6 ] [6] [6]),因此是不太行得通的。
-
参考文献 [ 29 ] [29] [29]:提出直接训练神经网络得到低秩分解形式,从而直接获得一个低秩网络,无需在训练中的每一步进行高成本的矩阵分解。
-
参考文献 [ 14 ] [14] [14]:解决矩阵分解后的梯度消失与梯度爆炸问题。
但是这些方法需要在训练前先对每个网络层的秩进行设定,而手动选择低秩可能无法取得最优的压缩,且训练低秩模型意味着模型优化非常困难,因为低秩意味着模型的容量(capacity)是很低的。
3 提出的方法 Proposed Method
-
本文结合分解训练(decomposed)与训练低秩(trained low-rank)两种思想,如 Figure 1 \\text{Figure 1} Figure 1所示:
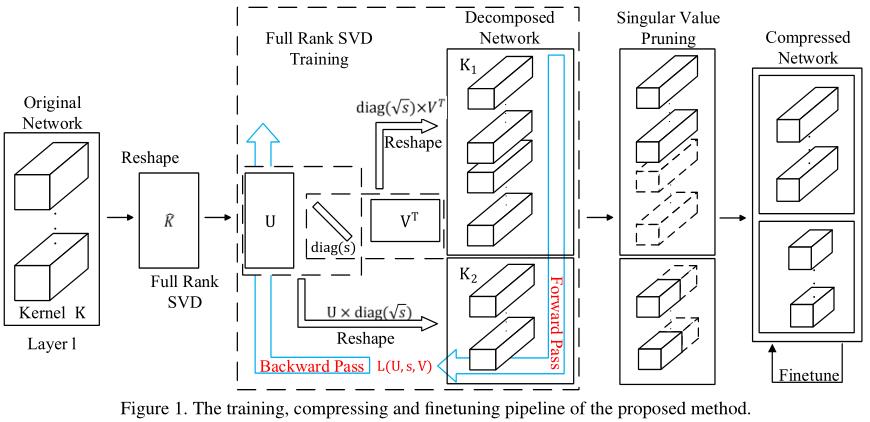
模型首先通过满秩SVD训练的分解后形式进行训练,然后进行奇异值剪枝(用于降秩),最后再进行进一步的微调(提升精确度)。
-
在Section 3.1中将会说明本文的模型将以空间级(spatial-wise,参考文献 [ 15 ] [15] [15])或者管道级(channel-wise,参考文献 [ 39 ] [39] [39])分解的形式进行训练,这样可以避开耗时的SVD。
与参考文献 [ 29 ] [29] [29]提出的训练步骤不同,本文将对模型进行满秩分解,以确保模型的容量(capacity)。
在SVD训练中,本文对奇异向量矩阵采用正交正则化(orthogonality regularization),每一层对奇异值采用稀疏导出正则器(sparsity-inducing regularizers),细节分别见Section 3.2&3.3。
在Section 3.4中论述SVD训练的目标函数以及总体模型的压缩管道(compression pipeline),目的是取得最好的压缩效果。
3.1 深度神经网络的SVD训练 SVD training of deep neural networks
-
本文提出通过神经网络的SVD形式来训练神经网络,其中每个网络层都被分解为两个连续的层(它们之间不存在额外的运算),具体而言对于权重矩阵 W ∈ R m × n W\\in\\R^{m\\times n} W∈Rm×n,可以分解为 U ∈ R m × r , V ∈ R n × r , s ∈ R s U\\in\\R^{m\\times r},V\\in\\R^{n\\times r},s\\in\\R^{s} U∈Rm×r,V∈Rn×r,s∈Rs三部分,其中 U U U与 V V