Hbase Compaction 队列数量较大分析(压缩队列刷新队列)
Posted 格格巫 MMQ!!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase Compaction 队列数量较大分析(压缩队列刷新队列)相关的知识,希望对你有一定的参考价值。
前几天朋友公司Hbase集群出现Compaction队列持续处于比较大的情况,并且mem flush队列也比较大,一起看了下问题,大概情况如下图
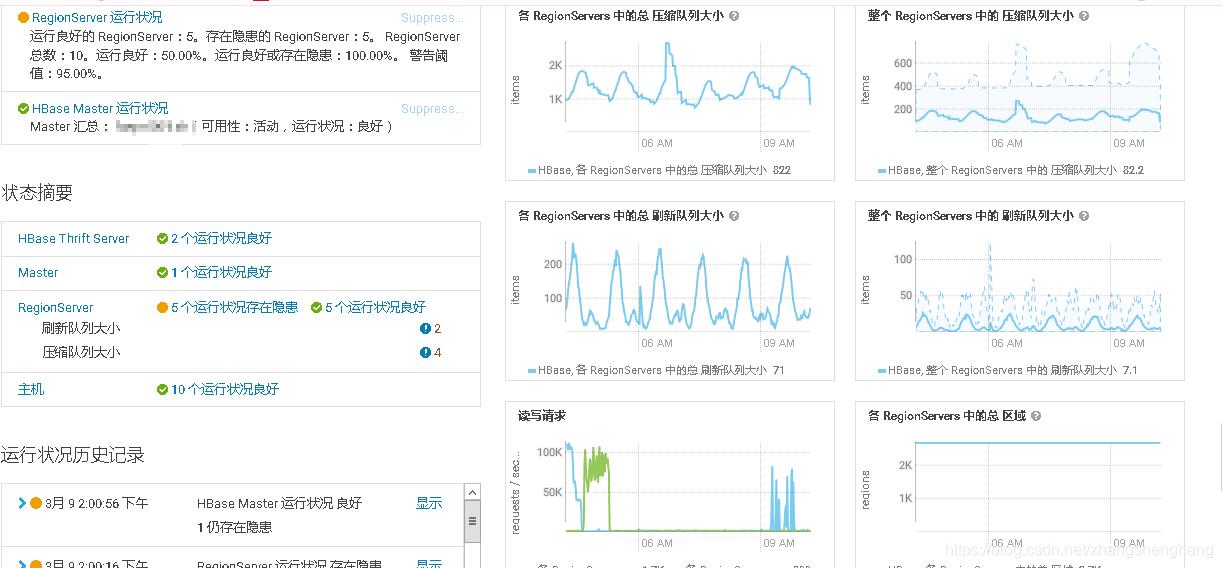
从图中可以看出来压缩队列总和持续在1000-2000,平对压缩队列在200左右,刷新队列也比较高,当然压缩队列高的原因就是因为我们 MemStore Flush 比较频繁,导致写入的StoreFile数量增加,触发了Compcation。
问题原因分析
我们先说下什么情况下会触发Compaction
1.后台线程周期性检查:
multiplier=1000,chore定期执行,每隔 hbase.server.thread.wakefrequency=10秒 默认 10 * 1000,也就是每隔10s*1000=10000s=2.77小时,会执行一次
具体介绍可以参考:https://datamining.blog.csdn.net/article/details/104711339
2.MemStore Flush
触发时机可以参考:https://datamining.blog.csdn.net/article/details/82745205
3.手动触发
根据上面CDH的监控页面我们推测是MemStore Flush 刷新频繁导致的问题
查看Hbase集群相关信息
当前配置参数为:
hbase.hregion.memstore.flush.size = 512M
hbase.hregion.memstore.block.multiplier = 20
hbase.hstore.compactionThreshold (hbase.hstore.compaction.min) = 3
hbase.hstore.compaction.max = 10
hbase.hstore.blockingStoreFiles = 16
hbase.regionserver.global.memstore.size=0.4
hbase RegionServer 堆内存 16g
region个数为3000左右,平均每台服务器300个region左右
这里介绍下参数的含义
配置参数 默认值 含义
hbase.hregion.memstore.flush.size 128M MemStore达到该值会Flush成StoreFile
hbase.hregion.memstore.block.multiplier 4 当region中所有MemStore大小超过hbase.hregion.memstore.flush.size*hbase.hregion.memstore.block.multiplier服务则停止写入
hbase.hstore.compactionThreshold (hbase.hstore.compaction.min) 3 当一个 Store 中 HFile 文件数量超过该阈值就会触发一次 Compaction(Minor Compaction)
hbase.hstore.compaction.max 10 一次 Compaction 最多合并的 HFile 文件数量,超过该值的文件会被过滤掉,本次不做Compcation
hbase.hstore.blockingStoreFiles 16 一个 Store 中 HFile 文件数量达到该值就会阻塞写入,等待 Compaction 的完成
hbase.regionserver.global.memstore.size 0.4
regionServer的全局memstore的大小,超过该大小会触发flush到磁盘的操作,默认是堆大小的40%,而且regionserver级别的flush会阻塞客户端读写
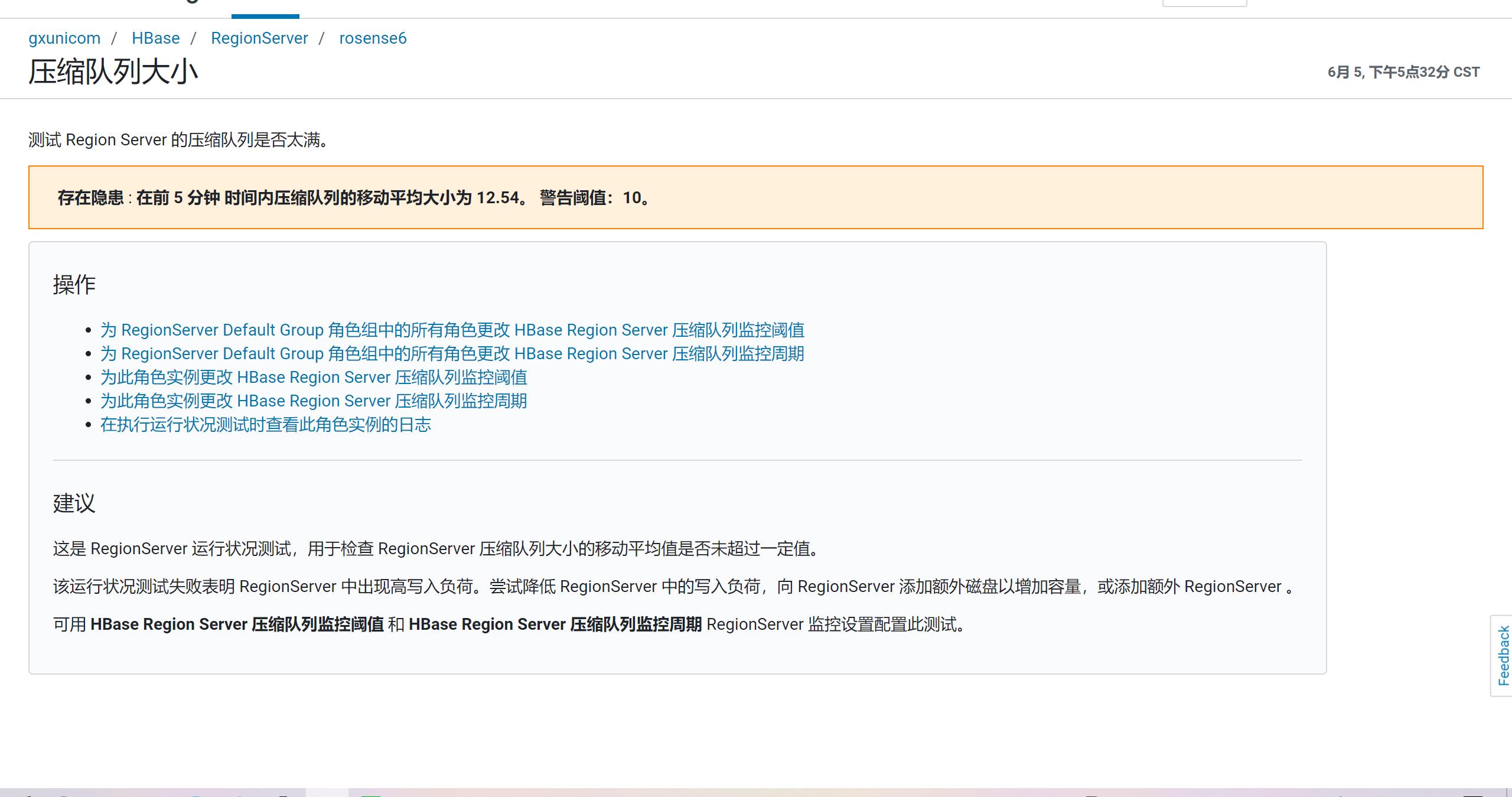
对不合理的参数进行修改,修改后配置为
hbase.hregion.memstore.flush.size = 256M
hbase.hregion.memstore.block.multiplier = 8
hbase.hstore.compactionThreshold (hbase.hstore.compaction.min) = 10
hbase.hstore.compaction.max = 20
hbase.hstore.blockingStoreFiles = 50
hbase RegionServer 堆内存 16g
hbase.hregion.memstore.flush.size
如果我们每个region写入数据都比较平均的话,当每个region的MemStore 大小达到 22M(下面有计算公式)就会触发RegionServer级别的Flush,所以集群中没有必要设置到512,我们改成256(其实改回默认128也不会影响)
16( RS JVM ) * 1024M * 0.4 / 300(region个数) ≈ 22 M
hbase.hregion.memstore.block.multiplier
该值是为了防止写入数据量过大导致服务停止写入,上面有解释,该值不宜设置过大,一般使用默认即可,这里我们暂时设置为8
hbase.hstore.compactionThreshold (hbase.hstore.compaction.min)
MemStore Flush 默认至少每一个小时会自动Flush一次数据(其他条件不满足,会系统自动flush),当StoreFile达到该值会触发Minor Compaction,线上我们可以调大该参数,这里设置为10
hbase.hstore.compaction.max
最大合并文件数量,我们设置为20,该值要比hbase.hstore.compactionThreshold大
hbase.hstore.blockingStoreFiles
一个Store中文件数量大于该值就停止写入,生产环境可以调整大一些,我们调整为50
重启服务,持续观察一段时间,看看效果如何
观察了一段时间,发现每次MemStore Flush 还是会导致队列很大
用工具看了下当前的Compaction压缩状态,查看下正在压缩的region,发现该region只有三个StoreFile就开始Compaction,再仔细一看正在执行的Compaction的Region都是在 hbase.hregion.majorcompaction 时间范围内。
去看了下配置,MajorCompaction的确没有关闭,实际生产环境我们可以根据每个Region下的StoreFile数量、大小,自行进行判断何时执行MajorCompaction,设置为手动就可以,能更灵活的运用服务器,将 hbase.hregion.majorcompaction 设置为 0 ,等待一段时间观察效果
总结建议
1.合理的控制MemStoreFlush频率
2.合理的进行表的预分区,提前进行数据量预估,减少表的分裂(在某些特定的业务下,可以禁止Region分裂,比如该表的数据大小我们可以预估出来)
3.尽量手动执行MajorCompaction
4.Region个数不宜太多
最佳数量:((RS memory) * (total memstore fraction)) / ((memstore size)*(# column families)) =16 1024 * 0.4 /(2561)= 25.6
实际使用,我们一般不会用这么少,我们公司配置是32G,管理着400Region左右,目前来看没什么影响
以上是关于Hbase Compaction 队列数量较大分析(压缩队列刷新队列)的主要内容,如果未能解决你的问题,请参考以下文章