HBase MetaStore和Compaction剖析
Posted 哥不是小萝莉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase MetaStore和Compaction剖析相关的知识,希望对你有一定的参考价值。
1.概述
客户端读写数据是先从Zookeeper中获取RegionServer的元数据信息,比如Region地址信息。在执行数据写操作时,HBase会先写MemStore,为什么会写到MemStore。本篇博客将为读者剖析HBase MemStore和Compaction的详细内容。
2.内容
HBase的内部通信和数据交互是通过RPC来实现,关于HBase的RPC实现机制下篇博客为大家分享。客户端应用程序通过RPC调用HBase服务端的写入、删除、读取等请求,由HBase的Master分配对应的RegionServer进行处理,获取每个RegionServer中的Region地址,写入到HFile文件中,最终进行数据持久化。
在了解HBase MemStore之前,我们可以先来看看RegionServer的体系结构,其结构图如下所示: 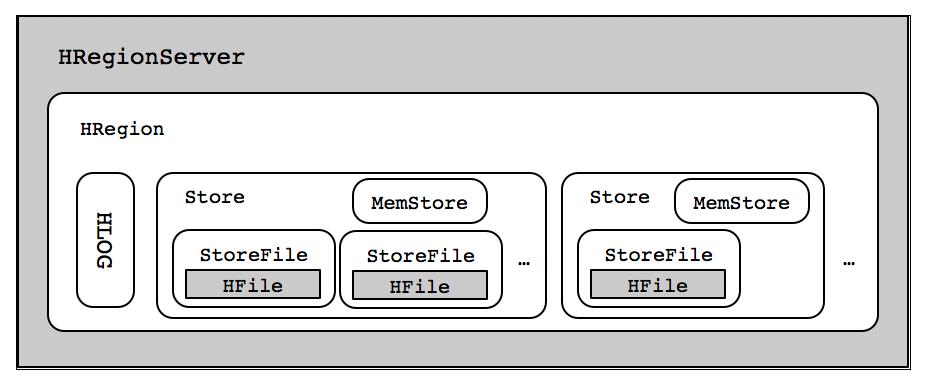
在HBase存储中,虽然Region是分布式存储的最小单元,单并不是存储的最小单元。从图中可知,事实上Region是由一个或者多个Store构成的,每个Store保存一个列族(Columns Family)。而每个Store又由一个MemStore和0到多个StoreFile构成,而StoreFile以HFile的格式最终保存在HDFS上。
2.1 写入流程
HBase为了保证数据的随机读取性能,在HFile中存储RowKey时,按照顺序存储,即有序性。在客户端的请求到达RegionServer后,HBase为了保证RowKey的有序性,不会将数据立即写入到HFile中,而是将每个执行动作的数据保存在内存中,即MemStore中。MemStore能够很方便的兼容操作的随机写入,并且保证所有存储在内存中的数据是有序的。当MemStore到达阀值时,HBase会触发Flush机制,将MemStore中的数据Flush到HFile中,这样便能充分利用HDFS写入大文件的性能优势,提供数据的写入性能。
整个读写流程,如下所示:
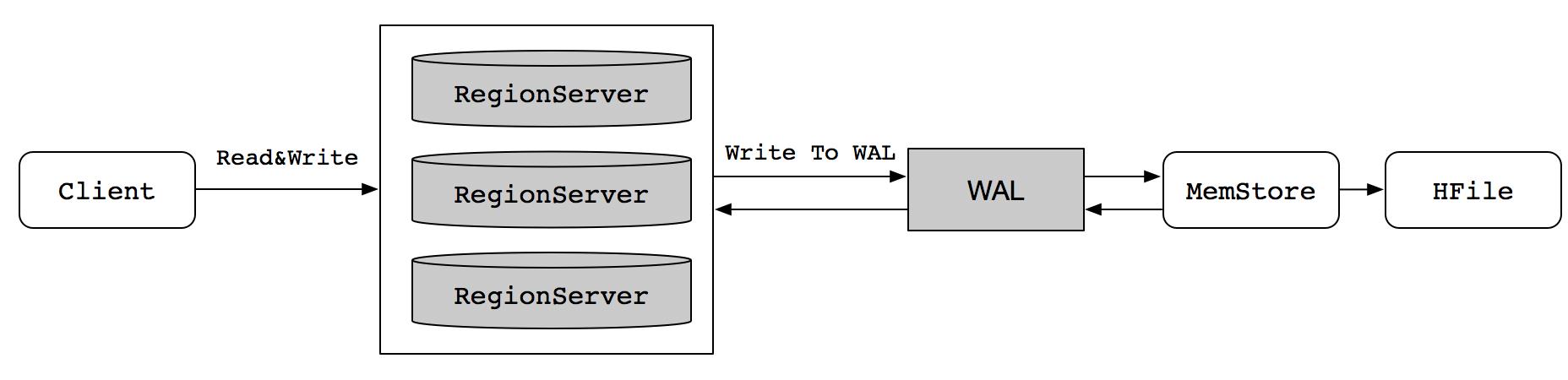
由于MemStore是存储放在内存中的,如果RegionServer由于出现故障或者进程宕掉,会导致内存中的数据丢失。HBase为了保证数据的完整性,这存储设计中添加了一个WAL机制。每当HBase有更新操作写数据到MemStore之前,会写入到WAL中(Write AHead Log的简称)。WAL文件会通过追加和顺序写入,WAL的每个RegionServer只有一个,同一个RegionServer上的所有Region写入到同一个WAL文件中。这样即使某一个RegionServer宕掉,也可以通过WAL文件,将所有数据按照顺序重新加载到内容中。
2.2 读取流程
HBase查询通过RowKey来获取数据,客户端应用程序根据对应的RowKey来获取其对应的Region地址。查找Region的地址信息是通过HBase的元数据表来获取的,即hbase:meta表所在的Region。通过读取hbase:meta表可以找到每个Region的StartKey、EndKey以及所属的RegionServer。由于HBase的RowKey是有序分布在Region上,所以通过每个Region的StartKey和EndKey来确定当前操作的RowKey的Region地址。
由于扫描hbase:meta表会比较耗时,所以客户端会存储表的Region地址信息。当请求的Region租约过期时,会重新加载表的Region地址信息。
2.3 Flush机制
RegionServer将数据写入到HFile中不是同步发生的,是需要在MemStore的内存到达阀值时才会触发。RegionServer中所有的Region的MemStore的内存占用量达到总内存的设置占用量之后,才会将MemStore中的所有数据写入到HFile中。同时会记录以及写入的数据的顺序ID,便于WAL的日志清理机制定时删除WAL的无用日志。
MemStore大小到达阀值后会Flush到磁盘中,关键参数由hbase.hregion.memstore.flush.size属性配置,默认是128MB。在Flush的时候,不会立即去Flush到磁盘,会有一个检测的过程。通过MemStoreFlusher类来实现,具体实现代码如下所示:
private boolean flushRegion(final FlushRegionEntry fqe) { HRegion region = fqe.region; if (!region.getRegionInfo().isMetaRegion() && isTooManyStoreFiles(region)) { if (fqe.isMaximumWait(this.blockingWaitTime)) { LOG.info("Waited " + (EnvironmentEdgeManager.currentTime() - fqe.createTime) + "ms on a compaction to clean up \'too many store files\'; waited " + "long enough... proceeding with flush of " + region.getRegionNameAsString()); } else { // If this is first time we\'ve been put off, then emit a log message. if (fqe.getRequeueCount() <= 0) { // Note: We don\'t impose blockingStoreFiles constraint on meta regions LOG.warn("Region " + region.getRegionNameAsString() + " has too many " + "store files; delaying flush up to " + this.blockingWaitTime + "ms"); if (!this.server.compactSplitThread.requestSplit(region)) { try { this.server.compactSplitThread.requestSystemCompaction( region, Thread.currentThread().getName()); } catch (IOException e) { LOG.error( "Cache flush failed for region " + Bytes.toStringBinary(region.getRegionName()), RemoteExceptionHandler.checkIOException(e)); } } } // Put back on the queue. Have it come back out of the queue // after a delay of this.blockingWaitTime / 100 ms. this.flushQueue.add(fqe.requeue(this.blockingWaitTime / 100)); // Tell a lie, it\'s not flushed but it\'s ok return true; } } return flushRegion(region, false, fqe.isForceFlushAllStores()); }
从实现方法来看,如果是MetaRegion,会立刻进行Flush,原因在于Meta Region优先级高。另外,判断是不是有太多的StoreFile,这个StoreFile是每次MemStore Flush产生的,每Flush一次就会产生一个StoreFile,所以Store中会有多个StoreFile,即HFile。
另外,在HRegion中也会检查Flush,即通过checkResources()方法实现。具体实现代码如下所示:
private void checkResources() throws RegionTooBusyException { // If catalog region, do not impose resource constraints or block updates. if (this.getRegionInfo().isMetaRegion()) return; if (this.memstoreSize.get() > this.blockingMemStoreSize) { blockedRequestsCount.increment(); requestFlush(); throw new RegionTooBusyException("Above memstore limit, " + "regionName=" + (this.getRegionInfo() == null ? "unknown" : this.getRegionInfo().getRegionNameAsString()) + ", server=" + (this.getRegionServerServices() == null ? "unknown" : this.getRegionServerServices().getServerName()) + ", memstoreSize=" + memstoreSize.get() + ", blockingMemStoreSize=" + blockingMemStoreSize); } }
代码中的memstoreSize表示一个Region中所有MemStore的总大小,而其总大小的结算公式为:
BlockingMemStoreSize = hbase.hregion.memstore.flush.size * hbase.hregion.memstore.block.multiplier
其中,hbase.hregion.memstore.flush.size默认是128MB,hbase.hregion.memstore.block.multiplier默认是4,也就是说,当整个Region中所有的MemStore的总大小超过128MB * 4 = 512MB时,就会开始出发Flush机制。这样便避免了内存中数据过多。
3. Compaction
随着HFile文件数量的不断增加,一次HBase查询就可能会需要越来越多的IO操作,其 时延必然会越来越大。因而,HBase设计了Compaction机制,通过执行Compaction来使文件数量基本保持稳定,进而保持读取的IO次数稳定,那么延迟时间就不会随着数据量的增加而增加,而会保持在一个稳定的范围中。
然后,Compaction操作期间会影响HBase集群的性能,比如占用网络IO,磁盘IO等。因此,Compaction的操作就是短时间内,通过消耗网络IO和磁盘IO等机器资源来换取后续的HBase读写性能。
因此,我们可以在HBase集群空闲时段做Compaction操作。HBase集群资源空闲时段也是我们清楚,但是Compaction的触发时段也不能保证了。因此,我们不能在HBase集群配置自动模式的Compaction,需要改为手动定时空闲时段执行Compaction。
Compaction触发的机制有以下几种:
- 自动触发,配置hbase.hregion.majorcompaction参数,单位为毫秒
- 手动定时触发:将hbase.hregion.majorcompaction参数设置为0,然后定时脚本执行:echo "major_compact tbl_name" | hbase shell
- 当选中的文件数量大于等于Store中的文件数量时,就会触发Compaction操作。由属性hbase.hstore.compaction.ratio决定。
至于Region分裂,通过hbase.hregion.max.filesize属性来设置,默认是10GB,一般在HBase生产环境中设置为30GB。
4.总结
在做Compaction操作时,如果数据业务量较大,可以将定时Compaction的频率设置较短,比如:每天凌晨空闲时段对HBase的所有表做一次Compaction,防止在白天繁忙时段,由于数据量写入过大,触发Compaction操作,占用HBase集群网络IO、磁盘IO等机器资源。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉。
以上是关于HBase MetaStore和Compaction剖析的主要内容,如果未能解决你的问题,请参考以下文章