HBASE Compaction 简介
Posted 青冬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBASE Compaction 简介相关的知识,希望对你有一定的参考价值。
HBASE Compaction 简介
序
since: 2021年4月8日 9:43
auth: Hadi
参考:
https://blog.csdn.net/u011598442/article/details/90632702
http://hbasefly.com/2016/07/25/hbase-compaction-2/?oudery=krl7p&xovahc=btigk
为什么要执行Compaction
HBase 是基于LSM-Tree 存储模型设计的,写入路径上是先写入WAL,
在写入memstore缓存,满足一定条件后执行flush操作将缓存数据刷新到磁盘,
生成一个HFile数据文件。
随着HFile文件越来越多,就会影响查询性能(io次数增加)
所以HBase会合并小的HFile,来减少文件数量,这种合并叫做Compaction。
Compaction 类型
是一个资源密集型操作(磁盘和网络皆有),网络IO在于HFile最终是存储在HDFS上的,HDFS通常会有副本同步,造成网络IO。
Compaction 分类
Minor Compaction 和 Major Compaction两种,图示如下:
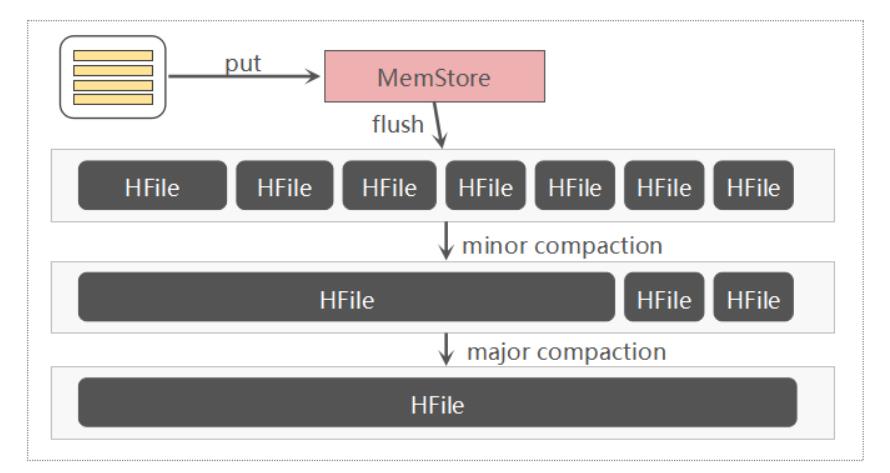
Minor
选取一些小的、相邻的HFile合并成一个更大的HFile。
默认情况下,minor会删除TTL过期数据。
Major
将一个Store中的所有的HFlie合并成一个HFile。
物理删除 delete,TTL,version 数据。
生产环境下请关闭major功能,在业务低峰期手动触发
Compaction 触发条件
HBase触发Compaction的条件有三种: memstore Flush、后台线程周期检查、手动触发。
memstore flush
compaction的根源就是flush,
memstore达到一定阈值或者其他条件时就会触发flush操作,刷写到磁盘生成HFile文件。
HBase每次flush后,会判断是否需要进行compaction,满足minor/major的条件便会触发执行。
后台线程周期检查
CompactionChecker 会定期检查,
周期:
hbase.server.thread.wakefrequency * hbase.server.compactchecker.interval.multiplier
一段事件内没有写入请求仍然需要做compact检查。
hbase.server.thread.wake.wakefrequency(默认10000 10s )HBase服务端线程的唤醒时间
用于周期性检查 log roller、memstore flusher 等操作的周期性检查
hbase.server.compactchecker.interval.multiplier(默认1000)
compaction周期性检查乘数因子
默认算下来就是10*1000=1hrs,46mins,40sec
Compaction参数解析
Major Compaction
大合并时间间隔
hbase.hregion.majorcompaction
605800000 (ms)
默认为7天调度(0.96及以前为1天一次),设置为0表示禁用触发major compaction
生产环境请配置为0,手动进行触发major compaction
Major compaction 抖动参数
hbase.hregion.majorcompaction.jitter
0.5
避免major compaction 同时在各个regionserver上同时发生,避免此操作给集群带来很大压力。
major compaction就会在+或-两者乘积的时间范围内随机发生。
Minor Compaction
最少合并HFile数量
hbase.hstore.compaction.min
3
最少3个符合HFile的合并文件才进行合并
建议调大,如果过小,则会带来更频繁的Minor Compaction
最多合并HFile数量
hbase.hstore.compaction.max
10
最多满足Hfile 10个进行合并。
不建议调大,过大导致压缩时间的延长
小于多少的HFile参与合并
hbase.hstore.compaction.min.size
128MB (memstoreFlushSize)
HFile如果小于128MB,则会被选中进行compaction
一般别改,但如果write-heavy,写压力很大的场景,需要微调该参数,减小参数值。
加入每次memsotre大小达到1~2M就flush,生成HFile了,此时生成的每个HFile都会加入压缩队列。
而且压缩生成的HFile又会进入压缩队列,继续压缩。
大于多少的HFile不参与合并
hbase.hstore.compaction.max.size
Long.MAX_VALUE
HFile如果小于128MB,则会被选中进行compaction
一般别改。
hbase.hstore.compaction.ratio
1.2
这个ratio参数的作用是判断 文件大小 > hbase.hstore.compaction.min.size的HFile是否也是适合进行minor
一般别改。建议取值范围在1.0~1.4之间
hbase.hstore.compaction.ratio.offpeak
5.0
此参数与compaction ratio参数含义相同,是在原有文件选择策略基础上增加了一个非高峰期的ratio控制
这个参数受另外两个参数 hbase.offpeak.start.hour 与 hbase.offpeak.end.hour 控制,
这两个参数值为[0, 23]的整数,
用于定义非高峰期时间段,默认值均为-1表示禁用非高峰期ratio设置。
compaction 线程池选择
Hbase RegionServver 内部专门有一个CompactSplitThread
用于维护执行minor compaction 、major compaction、split、merge操作的线程池。(前面有CompactionChecker检查)
其中与compaction操作有关的线程池称之为
largeCompactions(又名longCompactions) 与 smallCompactions (又名shortCompactions)
前者处理大规模compaction,后者处理小规模compaction。
线程池大小都默认为1.
这里major compaction的操作并不是一定指向largeCompactions 操作。
判定方法为:
hbase.regionserver.thread.compaction.throttle
默认为2 * hbase.hstrore.compaction.max* hbase.hregion.memstore.flush.size
如果flush size 大小事128MB,则计算出来为2.5G。
一次compaction的文件总大小如果超过改配置,就会分配给largeCompactions,不然就是smallCompactions
hbase.regionserver.thread.compaction.large
hbase.regionserver.thread.compaction.small
这两个配置可以进行调整,建议范围为2~5之间,不建议设置过大否则可能消费过多的服务端资源,造成不良影响。
Compaction 策略原则
compaction的设计必须要有一个平衡点,一方面保证compaction的基本效果,另一方面不能带来严重的IO压力。
所以compaction的策略必须根据应用场景和数据集来进行设计。
HBase在后续就提供一种机制来针对不同设计策略进行测试,让用户针对自己的业务场景选择合适的compaction策略。
0.96版本中HBase对架构进行了一定的调整,
提供了Compaction插件接口,用户实现这些接口就可能根据自己的应用场景和数据集定制特定的compaciton策略。
并且Compaction可以支持table/cf粒度级别的策略设置,是的用户可以根据应用场景的不同设计不同的策略。
所以:根据业务场景和数据集来设定Compaction的策略!
减少Compaction的文件数
文件根据rowkey、version等属性进行分割,再将这些重要的属性合并
不要合并大文件,合并时间会很长
不要合并不需要合并的文件
TSDB时序数据场景下的老数据,基本上就不会查询到,因此不进行合并也不会影响查询的性能
小region更有利于合并
小region在进行合并的时候,只会生成少量文件
写入放大的概率和频率小一丢丢
Compaction 策略介绍
HBase的compaction policy 有四种:
RatioBasedCompactionPolicy
0.96.X以前的默认
ExploringCompactionPolicy
0.96.X以后的默认
性能更高
一般不会进行更改
FIFOCompactionPolicy
收集所有过期的数据文件并删除
不会执行真正的重写
适合时序数据
StripeCompactionPolicy
将一个大Region切分为很多小subRegion
适用于Region大小大于2G的场景,要求Rowkey具有一定的统一格式。
来规避Major Compaction
加快查询速度
Compaction 对读写请求的影响
写入放大
Hbase Compaction会带来写入放大,特别是在写多读少的情况下,就会比较明显。
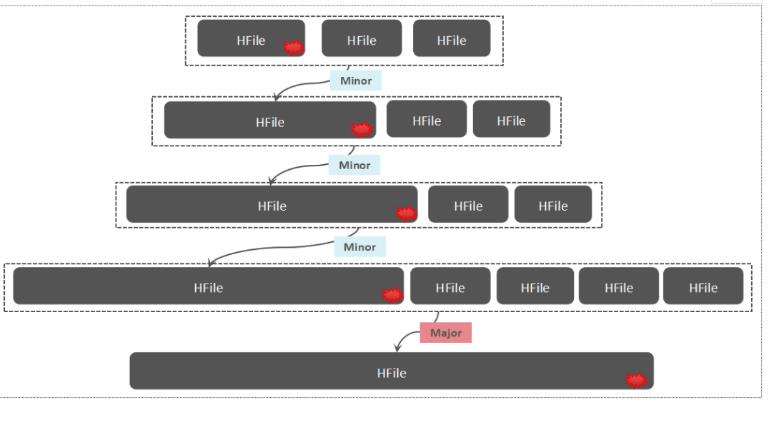
随着minor compaction 以及major Compcation 的发生,数据会被反复读取/写入。
这里会涉及到网络IO和磁盘IO (HDFS中的副本)
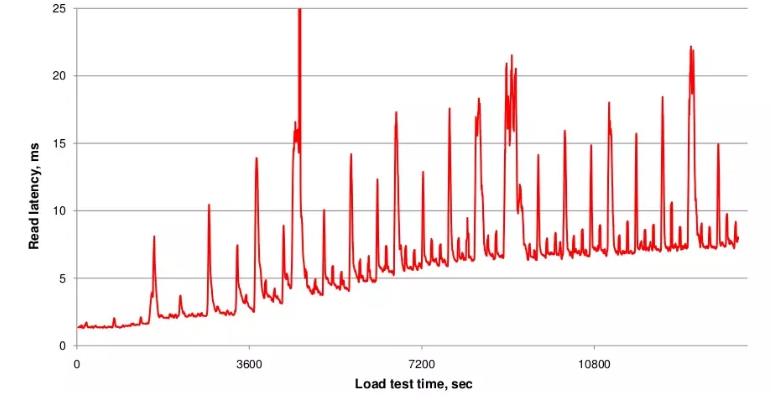
读路径上的延时毛刺
HBase执行compaction操作结果会使文件数基本稳定,进而IO Seek次数相对稳定。
延迟就会稳定在一定范围内,然而,compaction操作会带来很大的带宽压力,以及短时间的IO压力。
因此compaction就是使用短时间的磁盘网络IO来换取后续的查询的低延迟。
这种短时间的压力就会造成读请求在实验上会有比较大的毛刺。
写请求上的短暂阻塞
Compaction对写请求也有很大的影响。
主要表现在HFile较多的场景下,会对写请求的速度进行限制。
如果底层HFile数量超过
hbase.hstore.blockingStoreFiles
10
flush操作将会受到阻塞,阻塞时长为
hbase.hstore.blockingWaitTime
90000 (1.5min)
在这段时间内,如果compaction操作使得HFile下降到了预设阀值,则停止阻塞。
如果超过时间后,也会恢复进行flush操作。
Compaction总结
Hbase Compation操作是为了数据读取做的优化,总的来说是以牺牲了磁盘网络IO来换取了读性能的基本稳定。
在实际运用中,合理使用Compaction策略是极为重要的。
以上是关于HBASE Compaction 简介的主要内容,如果未能解决你的问题,请参考以下文章