HDFS其实很简单,分分钟学会前菜篇
Posted 大数据客栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS其实很简单,分分钟学会前菜篇相关的知识,希望对你有一定的参考价值。
回复"资源"获取更多资源
关注我,可了解更多有趣的技术问题
本篇收录于《hadoop框架系列》
注:底部有PDF文档领取
编者荐语:

数据量越来越大,在一个操作系统管辖的范围内存不下了,那么就会分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
在目前的公司环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理分布在集群上的文件系统称为分布式文件系统。而一旦在系统中,便自然引入网络,那么就不可避免地引入了所有网络编程的复杂性,例如挑战之一是如果保证在节点不可用的时候数据不丢失?思路:可用时直接备份
传统的网络文件系统(NFS)虽然也称为分布式文件系统,但是其存在一些限制。因为NFS中,文件是存储在单机上,它是无法提供可靠性保证,当很多客户端同时访问NFS Server时,很容易造成服务器压力,造成性能瓶颈。另外如果我们要对NFS中的文件进行操作,需要首先同步到本地,这些修改要在同步到服务端之前,其他客户端是不可见的。某种程度上,NFS不是一种典型的分布式系统,虽然它的文件的确放在远端(单一)的服务器上面。



*常见面试题及附答案
请列出正常的hadoop集群中hadoop都分别需要启动 哪些进程,他们的作用分别都是什么?请尽量列的详细一些。
答:namenode:负责管理hdfs中文件块的元数据,响应客户端请求,管理datanode上文件block的均衡,维持副本数量
Secondname:主要负责做checkpoint操作;也可以做冷备,对一定范围内数据做快照性备份。
Datanode:存储数据块,负责客户端对数据块的io请求
Jobtracker :管理任务,并将任务分配给 tasktracker。
Tasktracker: 执行JobTracker分配的任务。
Resourcemanager Nodemanager Journalnode Zookeeper Zkfc
请列出你所知道的hadoop调度器,并简要说明其工作方法
答:Fifo schedular :默认,先进先出的原则
Capacity schedular :计算能力调度器,选择占用最小、优先级高的先执行,依此类推。
Fair schedular:公平调度,所有的 job 具有相同的资源。
5.0 请列出你在工作中使用过的开发mapreduce的语言
答:java,hive,(python,c++)hadoop streaming
10.简述hadoop实现jion的几种方法
Map side join----大小表join的场景,可以借助distributed cache Reduce side join
9.0 请简述hadoop怎样实现二级排序(就是对key和value双排序)
第一种方法是,Reducer将给定key的所有值都缓存起来,然后对它们再做一个Reducer内排序。但是,由于Reducer需要保存给定key的所有值,可能会导致出现内存耗尽的错误。
第二种方法是,将值的一部分或整个值加入原始key,生成一个组合key。这两种方法各有优势,第一种方法编写简单,但并发度小,数据量大的情况下速度慢(有内存耗尽的危险),
第二种方法则是将排序的任务交给MapReduce框架shuffle,更符合Hadoop/Reduce的设计思想。这篇文章里选择的是第二种。我们将编写一个Partitioner,确保拥有相同key(原始key,不包括添加的部分)的所有数据被发往同一个Reducer,还将编写一个Comparator,以便数据到达Reducer后即按原始key分组。
这里列出了几个常见的面试题,让我们先热热身,看是否都比较熟悉,本文不涉及其他的知识,比如在HDFS底层原理什么是RPC?有什么好处等等,还有关于高可用性(High Availability)和元数据管理,在后面逐个会拆解,只是单纯把学习过程记录。
一 HADOOP背景
首先HADOOP最早起源于Nutch。它目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等,但是随着抓取网页数量的增加,遇到了极为严重的扩展性问题——如何解决数十亿网页的存储以及索引问题。
在2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。-分布式文件系统(GFS)诞生,可处理海量网页的存储,以及分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月份,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
1.1HDFS设计原则
HDFS设计出初就非常明确其应用场景,适用与什么类型应用,不适合什么场景,会有一个相对明确的指导原则。
| 设计目标
存储非常大的文件:这里非常大指的是几百M、G、或者TB级别。实际应用中已有很多集群它存储的数据达到PB级别。根据Hadoop官网,Yahoo的Hadoop集群大约有10万颗CPU,运行在4万个机器节点上。更多世界上的Hadoop集群使用情况,可查Hadoop官网.
采用流式的数据访问方式: HDFS基于这样的一个假设:最有效的数据处理模式是一次写入、多次读取数据集经常从数据源生成或拷贝一次,然后在其上做很多分析工作
业务分析工作常常读取其中的大部分数据,虽然不是全部,但是读取整个数据集它所需时间比读取第一条记录的延时更为重要。运行于商业硬件上: Hadoop不需要特别贵的、reliable(可靠的)机器,可运行于普通商用机器(可从多家供应商采购) ,商用机器并不代表低端机器。在集群中(尤其是大的集群),节点失败率是比较高的。HDFS的目标是确保集群在节点失败的时候不会让用户感受到明显的中断。
| HDFS不适合的应用类型
有些场景不适合使用HDFS来存数据。下面列举:
1) 低延时的数据访问
对延时要求在毫秒级别的应用,不适合采用HDFS。HDFS是为高吞吐数据传输而设计的,因此可能牺牲延时,则HBase更适合低延时的数据访问。
2)大量小文件
文件的元数据(比如目录结构,文件block的节点列表,blocknode mapping)保存在NameNode的ROM中, 整个文件系统的文件数量会受限于NameNode的内存大小。
经验而言,一个文件/目录/文件块一般占有150字节的元数据内存空间。但是若有100万个文件,每个文件占用1个文件块,就需要大约300M的内存。因此十亿级别的文件数量在现有商用机器上很难实现。
3)多方读写,需要任意的文件修改
HDFS采用追加(append-only)方式写入数据。它不支持文件任意offset的修改。也不支持多个写入器(writer)。
| 1.2 HDFS核心概念
2.1 Blocks
物理磁盘中有块的概念,磁盘的物理Block是磁盘操作最小的单元,读写操作均以Block为最小单元,一般为512 Byte。文件系统在物理Block之上抽象了另一层概念,文件系统Block是物理磁盘Block的整数倍。通常是几KB。Hadoop提供的df、fsck这些运维工具都是在文件系统的Block级别上进行操作。
HDFS的Block块肯定比一般单机文件系统大得多,默认为128M。HDFS的文件被拆分成block-sized的chunk,chunk作为独立单元存储。比Block小的文件不会去占用整个Block,只会占据实际大小。例如, 如果一个文件大小为1M,则在HDFS中只会占用1M的空间,而不是128M 就这意思。
HDFS的Block为什么这么大?
目的是为了最小化查找(seek)时间,控制定位文件与传输文件所用的时间比例。假设定位到Block所需的时间是10ms,磁盘传输速度为100M/s。如果要将定位到Block所用时间占传输时间的比例控制1%,则Block大小需要约100M。
但是如果Block设置过大,在MapReduce任务中,Map或者Reduce任务的个数 若小于集群机器数量,使得作业运行效率很低。
Block抽象的好处
block的拆分导致单个文件大小可以大于整个磁盘容量,构成文件的Block可以分布在整个集群, 理论上,单个文件可以占据集群中所有机器的磁盘。
Block的抽象也简化了存储系统,针对于Block,无需关注其权限,所有者等内容(这些内容都在文件级别上进行控制)。
Block作为容错和高可用机制中的副本单元,即以Block为单位进行复制。
| 2.2 Namenode & Datanode
整个HDFS集群由Namenode和Datanode构成master-worker(主从)模式。Namenode负责建命名空间,管理文件的元数据等,而Datanode负责实际存储数据,负责读写工作。
Namenode
Namenode存放的是文件系统树及所有文件、目录的元数据。元数据持久化为2种形式:
namespcae image
edit log
但是持久化数据不包括Block所在的节点列表,及文件的Block分布在集群中哪些节点上,这些信息是只有在系统重启时候重新构建(通过Datanode汇报的Block信息)。
在HDFS,Namenode可能成为集群的单点故障,Namenode不可用时,整个文件系统是不可用的。HDFS针对单点故障提供了2种解决机制:
1)备份持久化元数据
将文件系统的元数据同时写到多个文件系统, 例如同时将元数据写到本地文件系统及NFS。这些备份操作都是同步的、原子性的。
2)Secondary Namenode
Secondary节点定期合并主Namenode的namespace image和edit log, 避免造成edit log过大,通过创建检查点checkpoint来合并。维护一个合并后的namespace image副本, 用于在Namenode完全崩溃时恢复数据。下图是Secondary Namenode的管理界面:
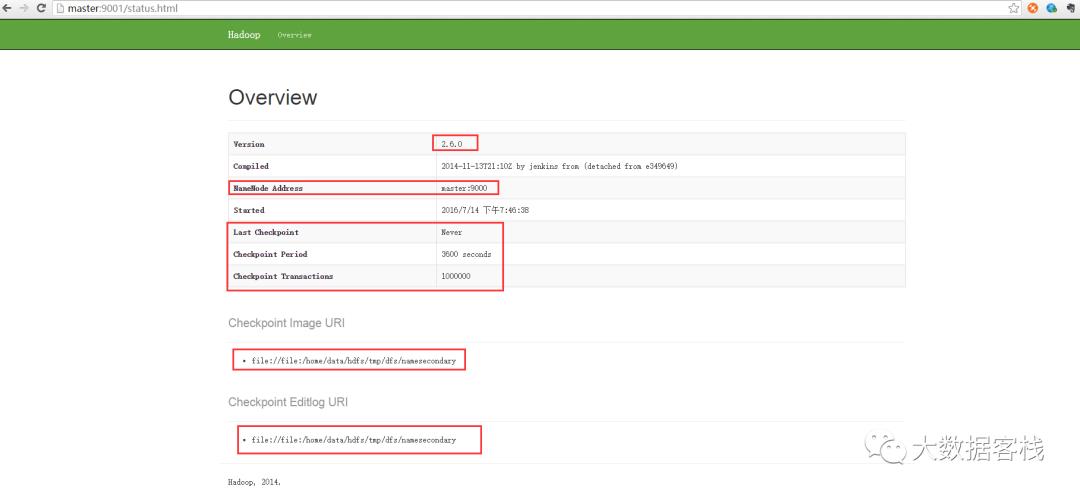
Secondary Namenode通常运行在另一台机器上,因为合并操作需要耗费大量的CPU和内存。其数据落后于Namenode,所以当Namenode完全崩溃时,会出现数据丢失。通常做法是拷贝NFS中的备份元数据到Second,将其作为新的主节点Namenode。
在HA(High Availability高可用性)中可以运行一个Hot Standby,当作热备份,在Active Namenode故障之后,替代原有Namenode成为Active Namenode。
Datanode
数据节点负责存储和提取Block,读写的请求可能来自namenode,也可能来自客户端。数据节点周期性向Namenode汇报自己节点上所存储的Block相关信息。
| 1.3重要特性:
(1)HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来限定,默认大小在hadoop2.x版本中是128M,老版本中是64M;
(2)HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
(3)**目录结构和文件分块信息(元数据)**管理是由namenode节点承担—namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
(4)文件的各个block的存储管理由datanode节点承担
---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
补充:同一个block不会存储多份(大于1)在同一个datanode上,因为这样没有意义。
(5)HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改;
(注:适合用来做数据分析,并不适合用来做网盘应用,因为,不便修改,延迟大,网络开销大,成本太高)
| 1.4 生态圈简介
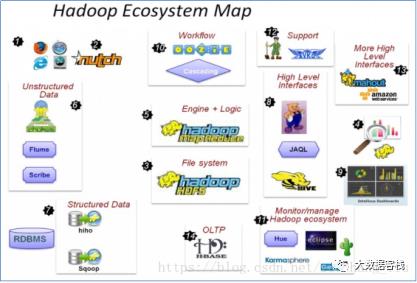
常用组件:
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
二 HADOOP集群搭建
本文使用的是:hadoop-2.6.5版本
2.1 集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包(SDK)
2.2 shell命令
HDFS命令有两种风格:
hadoop fs开头的;
hdfs dfs开头的;
两种命令均可使用,效果相同
2.3命令实操
2.3.1 -help:输出这个命令参数
bin/hdfs dfs -help rm
2.3.2 -ls: 显示目录信息
hadoop fs -ls /
2.3.3 -mkdir: 在hdfs上创建目录
hadoop fs -mkdir -p /aaa/bbb/cc/dd
2.3.4 -moveFromLocal: 从本地剪切粘贴到hdfs
hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
2.3.5 -moveToLocal: 从hdfs剪切粘贴到本地
hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt
2.3.6 --appendToFile: 追加一个文件到已经存在的文件末尾
hadoop fs -appendToFile ./hello.txt /hello.txt
2.3.7 -cat: 显示文件内容
2.3.8 -tail: 显示一个文件的末尾
hadoop fs -tail /weblog/access_log.1
2.3.9 -text:以字符形式打印一个文件的内容
hadoop fs -text /weblog/access_log.1
2.3.10 -chgrp 、-chmod、-chown: linux文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 666 /hello.txt
hadoop fs -chown someuser:somegrp /hello.txt
2.3.11 -copyFromLocal:从本地文件系统中拷贝文件到hdfs路径去
hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
2.3.12 -copyToLocal: 从hdfs拷贝到本地
hadoop fs -copyToLocal /aaa/jdk.tar.gz
2.3.13 -cp: 从hdfs的一个路径拷贝到hdfs的另一个路径
hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
2.3.14 -mv: 在hdfs目录中移动文件
hadoop fs -mv /aaa/jdk.tar.gz /
2.3.15 -get: 等同于copyToLocal,就是从hdfs下载文件到本地
hadoop fs -get /aaa/jdk.tar.gz
2.3.16 -getmerge: 合并下载多个文件,比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,…
hadoop fs -getmerge /aaa/log.* ./log.sum
2.3.17 -put: 等同于copyFromLocal
hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
2.3.18 -rm: 删除文件或文件夹
hadoop fs -rm -r /aaa/bbb/
2.3.19 -rmdir: 删除空目录
hadoop fs -rmdir /aaa/bbb/ccc
2.3.20 -df: 统计文件系统的可用空间信息
hadoop fs -df -h /
2.3.21 -du: 统计文件夹的大小信息
hadoop fs -du -s -h /aaa/*
2.3.22 -count: 统计一个指定目录下的文件节点数量
hadoop fs -count /aaa/
2.3.23 -setrep: 设置hdfs中文件的副本数量
hadoop fs -setrep 3 /aaa/jdk.tar.gz
注:命令无需死记硬记,需结合实操在问题去加强记忆 可记笔记也行;
2.4网络拓扑
在本地网络中,两个节点被称为“彼此近邻”是什么意思?
在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺
这里的想法是将两个节点间的带宽作为距离的衡量标准
节点距离:两个节点到达最近的共同祖先的距离总和
例如,假设有 数据中心d1 机架r1 中的节点 n1,该节点可以表示为/d1/r1/n1,利用这种标记,这里给出四种距离描述:
Distance(/d1/r1/n1, /d1/r1/n1)=0(同一节点上的进程)
Distance(/d1/r1/n1, /d1/r1/n2)=2(同一机架上的不同节点)
Distance(/d1/r1/n1, /d1/r3/n2)=4(同一数据中心不同机架上的节点)
Distance(/d1/r1/n1, /d2/r4/n2)=6(不同数据中心的节点)
2.5机架感知(副本节点选择)
| 低版 本Hadoop 副本节点选择
第一个副本在 Client 所处的节点上,如果客户端在集群外,随机选一个
第二个副本和第一个副本位于不相同机架的随机节点上
第三个副本和第二个副本位于相同机架,节点随机
| Hadoop 2.9.2 副本节点选择
第一个副本在 Client 所处的节点上,如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点
第三个副本位于不同机架,随机节点
| namenode与secondaryName解析
NameNode主要负责集群当中的元数据信息管理,而且元数据信息需要经常随机访问,因为元数据信息必须高效的检索,那么如何保证namenode快速检索呢??元数据信息保存在哪里能够快速检索呢??如何保证元数据的持久安全呢??
目的保证元数据信息的快速检索,那么我们就必须将元数据存放在内存当中,因为在内存当中元数据信息能够最快速的检索,那么随着元数据信息的增多(每个block块大概占用150字节的元数据信息),内存的消耗也会越来越多。
如果所有的元数据信息都存放内存,服务器断电,内存当中所有数据都消失,为了保证元数据的安全持久,元数据信息必须做可靠的持久化,在hadoop当中为了持久化存储元数据信息,将所有的元数据信息保存在了FSImage文件当中,那么FSImage随着时间推移,必然越来越膨胀,FSImage的操作变得越来越难,为了解决元数据信息的增删改,hadoop当中还引入了元数据操作日志edits文件,edits文件记录了客户端操作元数据的信息,随着时间的推移,edits信息也会越来越大,为了解决edits文件膨胀的问题,hadoop当中引入了secondaryNamenode来专门做fsimage与edits文件的合并
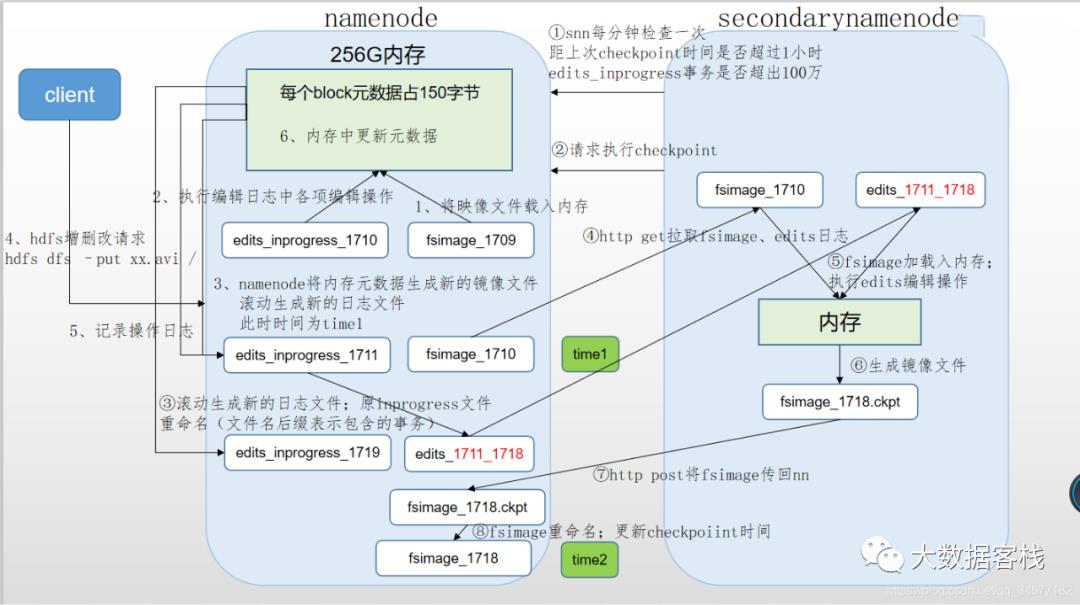
4.1 HDFS写数据流程
剖析文件写入
HDFS写数据流程,如图所示
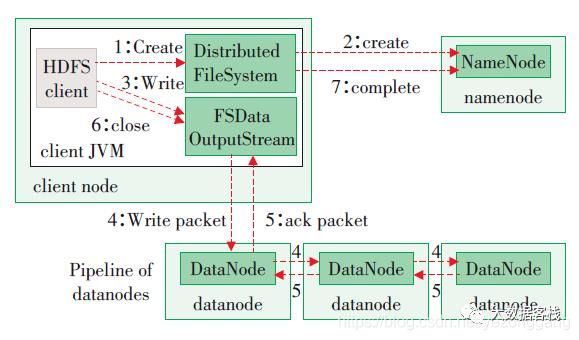
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)NameNode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;
8)当一个block传输完成之后,客户端再次请求NameNode上传第二个block的服务器。(再重复执行3-7步)。
这里的话,追加一下一些问题(分布式系统之间可能故障,而且网络的不可靠性都是设计人员需要考虑的问题):socket(长连接),http(短连接),还有其他的方式,比如管道、FIFO、消息队列(kafka。。。等等)
为什么使用长链接?
最简单分布式系统是一直存在的,很少是短时间的访问,维持心跳机制
什么是心跳机制?
namenode启动的时候,会有一个加载元数据(数据的数据,类似于表的索引)和块报告(datanode会定时(可以再配置文件中设置,所以一定要时间同步)对块信息进行统计)的过程,namenode通过心跳机制维护整个集群的可用性。如果块报告上传失败,namenode不会更新元数据,在块报告的时候就会将其删除掉。
| 安全模式
什么时候进入安全模式?
刚刚启动(namenode加载元数据的时候(先加载元数据镜像到内存中,在将edits日志的操作在内存中执行一遍,namenode进入安全模式,进行块报告,阈值安全的话30秒退出安全模式))
阈值低于0.999f(默认)
datanode存活数量小于0
怎么解除安全模式?
1. 格式化集群(需要删除namenode.dir的配置路径)
基本不会采用这种方式
2. 强制离开安全模式
hdfs dfsadmin -safemode leave
3 .# 检测集群文件、节点、块是否出现问题
hdfs fsck /
#删除损坏块的block
hdfs fsck / -delete
4. 调低阈值(在配置文件 safemode)
| HDFS读数据流程
HDFS的读数据流程,如图所示
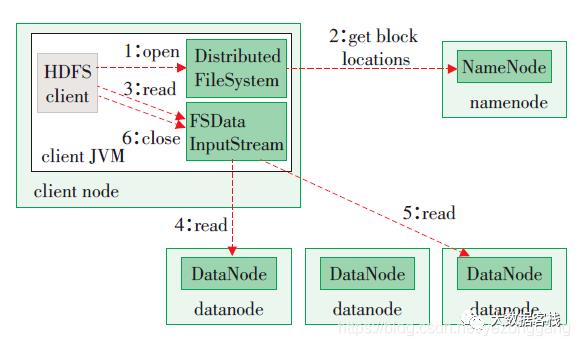
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
| 磁盘故障
多个副本策略
namenode故障宕机
简单方案:secondarynamenode取出fsimage文件copy到namenode的元数据存储目录下
完美解决:在namenode上挂多块磁盘,配置fs.namenode.name.dir(用,分割磁盘 );
三 Hadoop文件系统
前面Hadoop的文件系统概念是抽象的,HDFS只是其中的一种实现。Hadoop提供的实现如下图:

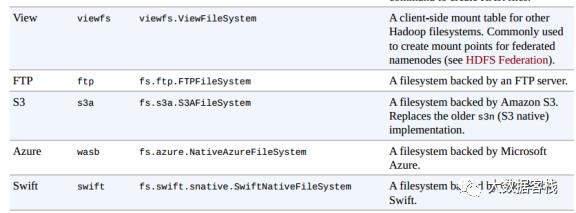
简单介绍一下,Local是对本地文件系统的抽象,hdfs就是我们最常见的,两种web形式(webhdfs,swebhdfs)的实现通过HTTP提供文件操作接口。har是Hadoop体系下的压缩文件,当文件很多的时候可以压缩成一个大文件,可以有效减少元数据的数量。viewfs就是我们前面介绍HDFS Federation张提到的,用来在客户端屏蔽多个Namenode的底层细节。ftp顾名思义,就是使用ftp协议来实现,对文件的操作转化为ftp协议。s3a是对Amazon云服务提供的存储系统的实现,azure则是微软的云服务平台实现。
前面我们提到了使用命令行跟HDFS交互,事实上还有很多方式来操作文件系统。例如Java应用程序可以使用org.apache.hadoop.fs.FileSystem来操作,其他形式的操作也都是基于FileSystem进行封装。我们这里主要介绍一下HTTP的交互方式。
WebHDFS和SWebHDFS协议将文件系统暴露HTTP操作,这种交互方式比原生的Java客户端慢,不适合操作大文件。通过HTTP,有2种访问方式,直接访问和通过代理访问
| 直接访问
直接访问的示意图如下:
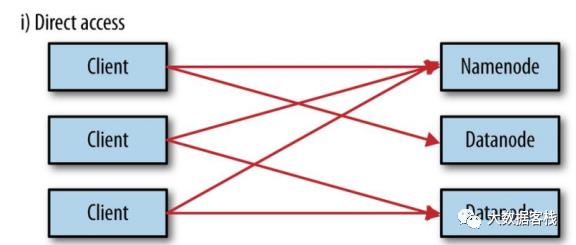
Namenode和Datanode默认打开了嵌入式web server,即dfs.webhdfs.enabled默认为true。webhdfs通过这些服务器来交互。元数据的操作通过namenode完成,文件的读写首先发到namenode,然后重定向到datanode读取(写入)实际的数据流。
| 通过HDFS代理
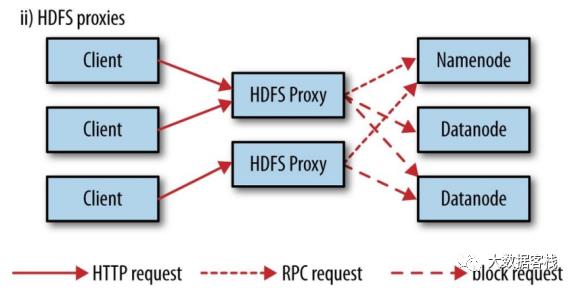
采用代理的示意图如上所示。使用代理的好处是可以通过代理实现负载均衡或者对带宽进行限制,或者防火墙设置。代理通过HTTP或者HTTPS暴露为WebHDFS,对应为webhdfs和swebhdfs URL Schema。
代理作为独立的守护进程,独立于namenode和datanode,使用httpfs.sh脚本,默认运行在14000端口;
除了FileSystem直接操作,命令行,HTTTP外,还有C语言API,NFS,FUSER等方式,这里不做过多介绍(咱也不懂)。
点击下方【大数据客栈】
发送关键词“hadoop” 即可获取;
——END——
下期预告:元数据管理机制
Hi,小伙伴你好,我是晨希,一枚双非二本苦练心法的正经程序员,也希望你,可以进群跟大佬一起交流。
欢迎 [ 关注 ],会亲手带你构建大数据框架体系,[ 领略 ] 不一样的开发,也可以[ 点赞, 收藏,在看],十分感谢你!
以上是关于HDFS其实很简单,分分钟学会前菜篇的主要内容,如果未能解决你的问题,请参考以下文章