Transformer以及attention机制介绍
Posted SSyangguang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Transformer以及attention机制介绍相关的知识,希望对你有一定的参考价值。
由于transformer中使用了attention,我在第一次接触transformer时也是懵逼的,好在通过观看李宏毅的课程和百度飞桨顶会论文复现赛的直播后,大概理解了原理,这里和大家分享。
1 self-attention机制
1.1 self-attention的提出
NLP和图像的输入都可以看作是一个vector,输出可能是类别或者数值,如果是一排vector,并且数量可变(例如句子长度不同),此时应该如何处理呢?
首先来看对于一个句子,每个词的表示方法有两种:one-hot和word embedding。One-hot方法存在问题是每个词之间的联系被忽略了,word embedding会给每个词一个向量,包含了语义信息,最终一个句子就是一个长度不一的向量。其他结构类似图、社交网络、分子也是这样的,每个节点就是一个词,每个节点都有一个向量。
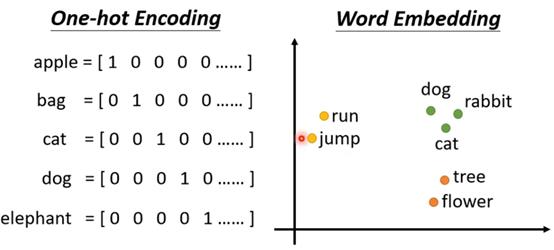
这些的词的输出有三种形式,第一种是每个向量一个输出,例如每个词的属性就是这类输出,称为sequence labeling;第二种是全部向量一个输出,如分类任务只会输出一个类别;第三种是未知数量的输出,需要算法自行决定,也称为seq2seq任务。对于第一种,可以考虑使用FC,但是对于I saw a saw这样一句两个saw含义明显不同的句子,FC对它们所得结果是相同的,这时只有获得上下文信息后将前后几个向量一起送入FC,然后在句子长度很长以及长度不定时,FC处理起来参数会非常大。这种情况就需要self-attention出马了,它的特点就是几个输入vector,就有几个输出,所有的vector一起送入模型中。下图中带黑框的vector矩形表示的是考虑了整个sequence后得到的vector,把这样的vector再送入FC中,vector就不是普通的vector,而是考虑了整个sequence后的vector。
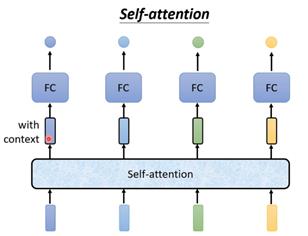
此外可以叠加多个self-attention,比如和FC交替使用,这样self-attention处理整个sequence的信息,而FC专注于处理某个位置的信息。
1.2 self-attention的原理
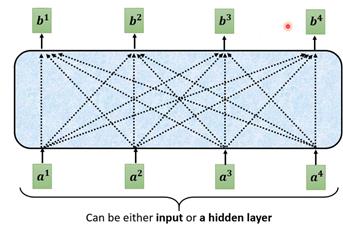
Self-attention的结构图如下。输入可以是原始vector,亦可以是某层输出。
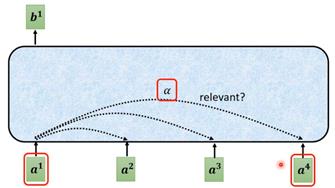
例如输出b1的产生,就是要找出和a1相关的向量,判断哪些对a1是重要的,哪些是不重要的。使用α表示两个向量之间的相关性。
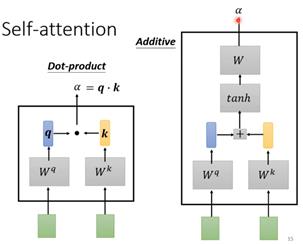
self-attention判断两个向量之间相关性α的过程有两种:1.dot-product将输入的两个向量分别乘上一个矩阵,得到q和k向量,然后q和k做相乘运算就可以得到α(两个向量之间做点积实际是计算它们之间的相似性);2.addictive方法对于获取向量q和k是相同的,然后将这两个向量拼接起来通过tanh和一个矩阵W得到α。Transformer中使用的就是第一种,因此这里也仅介绍第一种方法。
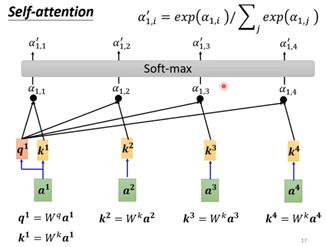
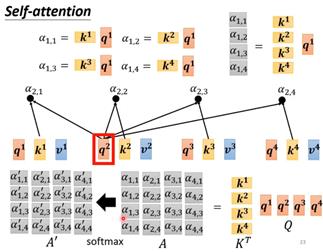
将这种计算方法放入attention时就是让a1、a2、a3、a4都计算各自的query和key向量,,按照下图的方法计算a1和其他几个向量的α。等计算得到所有α后使用softmax计算每个输入向量的输出(不一定非是softmax也可以用relu)。
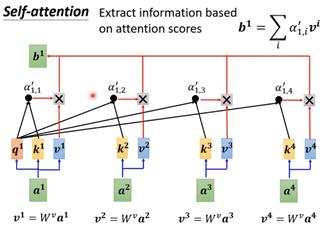
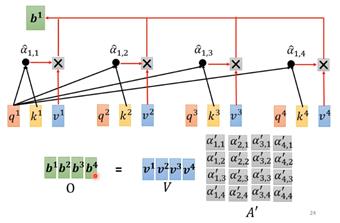
计算得到α后要抽取sequence中重要的信息。根据α就可以知道哪些向量是和a1最有关系,通过这个关系来抽取重要信息,方法是分别计算每个向量的value向量,方法也是乘上W矩阵。然后将这个v值和dot-product得到的α相乘,然后所有向量的该值相加。Q、K、V在语义层面的理解可以是:Q就是query,代表问题,匹配别人;K是key,代表了什么问题,用于被匹配;V是value,代表内容,被提取的信息。本质上可以理解为一个查询(query)到一系列(键key-值value)对的映射。
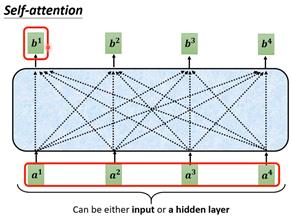
这样就得到了通过整个sequence得到b值的过程。一排vector处理后得到另一排数量相同的输出。需要说的是b1到b4不需要按顺序算,可以同时算出来。
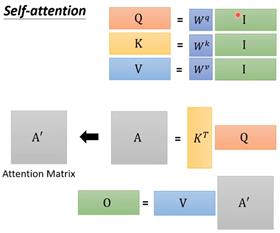
从矩阵乘法角度来讲,计算q向量时,每个输入的vector都乘上矩阵W得到向量q,如果将这些输入的vector都拼成一个大矩阵,那么就是矩阵Q,同理也可以用这种方式得到矩阵K和矩阵V。
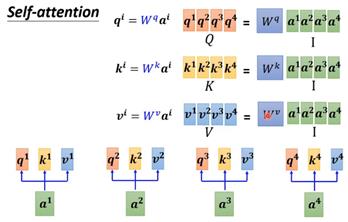
Dot-product也可以用这种矩阵方式来表示。
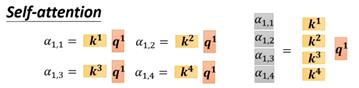
将四个输入vector计算α的过程可以通过下图的整合为一个大的矩阵运算过程。要注意的是k和q相乘后得到的是一个值,所以向量k和q相乘时需要对k做一个转置,所以对于矩阵K也是需要做转置的。转置后的矩阵K和Q相乘得到矩阵A,就是所有α值拼接得到的矩阵。最后对矩阵做一个softmax即可得到最终的α。
最终的输出值b也是用这种矩阵方式得到的。得到的是矩阵O。
整理整个过程,输入是矩阵I,输出是矩阵O,整个过程需要学习的只有矩阵W的参数,其他过程都不需要学习。
1.3 multi-head self-attention
可以使用不同的q来负责不同种类的相关性,所以这类任务可以用到多个q,也就是multi-head self-attention。Q乘上不同的矩阵就可以得到不同的q向量,例如图中得到2个q向量,表示任务中有2种不同的相关性,需要产生2种q向量,并且对应地,k和v向量也是2个。每个输入都按照self-attention的方法进行一次运算,最终得到2个输出b。
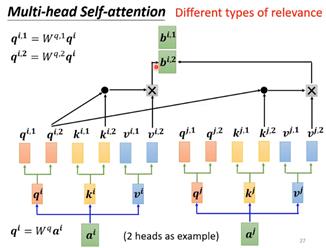
在注意力计算之前,将输入首先分为多段,对每一段分别计算自注意力,每一部分称为一头。计算方式:1.分段后的输入首先经过一次线性变换,将输入映射到不同的特征子空间;2.计算每一个头的attention打分;3.将计算的多个头的输出进行拼接构成多头注意力层的整体输出。
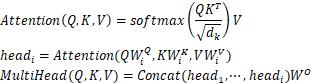
分母上的Dk是缩放点积注意力机制(scaled dot-product attention),作用是1.归一化;2.是计算注意力时内积不至于过大,否则softmax操作进入饱和区。
1.4 positional encoding
Self-attention处理sequence信息时并没有位置信息,每个vector的操作都是相同的,并不会因为位置不同而产生影响。但是有些任务中位置信息会很重要,例如在文本处理中,动词在句首的概率就很低,这时候位置信息就是有用的。如果需要位置信息,那么就可以加入positional encoding来表示位置信息。具体方式就是每个一个位置设置一个位置向量e,每个不同位置就有不同的vector,将这个positional encoding加到vector上即可。下图就是positional encoding真实样子。positional encoding可以直接通过公式生成,也可以通过学习得到。文献研究了各类positional encoding,链接:arxiv.org/abs/2003.09229。

1.5 self-attention和CNN差异
CNN其实看作是简化版的self-attention,也就是只对感受野中的像素进行self-attention处理。也可以说self-attention是复杂的CNN,就是说感受野不是手动设计,而是自动学出来的。Arxiv.org/abs/1911.03584从数学角度证明了CNN是self-attention的特例,self-attention可以获得和CNN一样的效果。
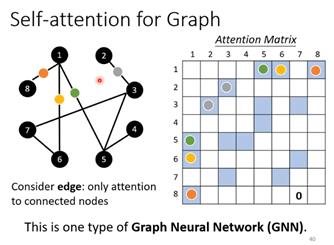
此外还有self-attention用于图的例子,图因为有节点和边,Self-attention中vector之间的关联性是模型自己学习出来的,而将Self-attention用于图时,attention matrix的计算可以只计算有边相连的节点,例如节点1和8相连,可以只计算节点1和8之家attention的分数。两个节点没有相连很可能这两个节点之间就没有关系,因此就不需要计算attention的值。这种思想应用于GNN也就是图神经网络变体的一种类型。
2 Transformer原理
2.1 transformer原理
Transformer亦属于seq2seq模型,即输入一个序列,输出不定长序列,例如语音识别中输入信号和输出文字长度不同,翻译任务中输入句子和输出句子也往往长度不同,multi-label任务中一个目标也可以有多个类别。Seq2seq都会有一个编码器和一个解码器。编码器的作用就是输入一排vector,输出另一排vector。一个编码器含有多个block,都是输入输出多个vector,具体如下图。

transformer的self-attention中不仅要输出一个vector,还要将输入的vector和输出相加得到新的输出,也就是残差连接,加起来后的vector还要经过一个layer norm层,后边的FC层输出也要经过一次残差相加和layer norm层处理后猜得到最终的编码器输出。
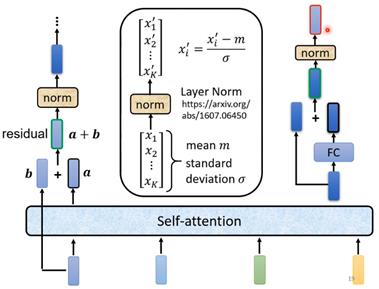
此外transformer的编码器还会在输出部分添加positional encoding,以及使用的self-attention机制是multi-head形式(BERT用的也是这种形式)。
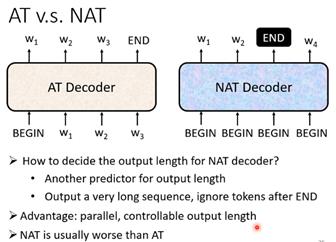
解码器有两种,常用的是autoregressive。这种形式的解码器输入起始是前一个时间点自己的输出,这样带来的问题可能会有错误的输出会影响下一个时间点的输入,从而影响整体的结果。它的输出长度是自己设定,可以无限循环下去,一般需要在输出向量中添加一个END来决定结束。另一种是non-autoregressive,由于输出长度也是问题,所以一个解决办法就是通过一个分类器解决,具体就是让这个分类器输入的是编码器的输入,分类器输出就是non-autoregressive应该输出的长度,训练出一个分类器来预测新的输出长度。另一个解决方法就是给很多begin,等到输出end时候结束。NAT decoder的好处是不用将前一个输出当作下一个输入,所有BEGIN的token可以同时处理,因此可以并行化处理,处理速度更快。但是AT的decoder效果一般好于NAT decoder。
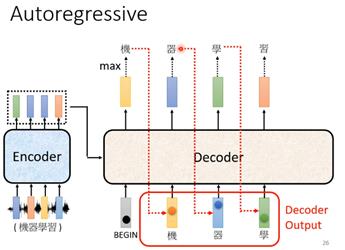
Transformer中的解码器如下图,和编码器有些模块很相似。

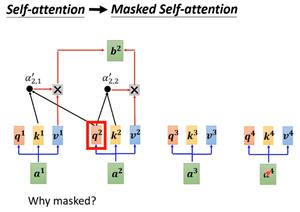
不同之处有解码器中间的masked self-attention,这个结构就是产生输出的每个b的时候,输入只是部分a而不是整个a。解码当前单词时,默认无法看见当前单词后面的词。
而transformer中编码器和解码器的信息传递通过cross-attention来进行,也就是上图transformer结构中的红框部分,在masked multi-head attention处理后的q来自解码器,而k和v来自于编码器。下图就是cross-attention的详细结构。
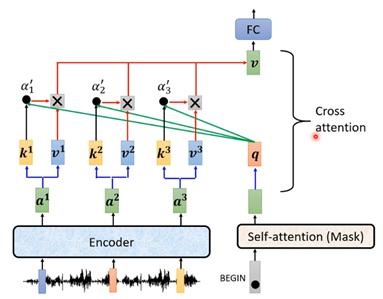
其实cross-attention中解码器来自于编码器那部分的输出并不一定是编码器的输出,arxiv.org/abs/2005.08081介绍了各种花样cross-attention的方法,可以有各种连接的方式。因此,transformer的编码器和解码器就分为:
- 编码器:1.多头注意力机制(+残差连接+层归一化);2.逐位置前馈网络(+残差连接+层归一化)
- 解码器:1.掩码多头注意力层(+残差连接+层归一化);2.交叉多头注意力层(+残差连接+层归一化);3.逐位置前馈网络(+残差连接+层归一化);4.线性映射解码层。
逐位置前馈网络(position-wise feed-forward networks)是两层前馈网络,中间使用ReLU激活函数。逐位置是指每个位置的attention输出均使用相同的前馈网络进行变换。作用是空间变换,增加模型的表现能力。
残差连接用于解决梯度消失和权重矩阵的退化问题。网络层数很深之后效果不好的主要原因是权重矩阵的退化,也就是每个层中只有少量的隐藏单元对不同的输入改变它们的激活值,而大部分隐藏单元对不同的输入都是相同的反应,此时整个权重矩阵的秩(秩指的是矩阵中线性无关的向量个数)不高,并且随着网络层数的增加,连乘后使得整个秩变得更低。
还有层归一化(layer normalization),深度神经网络有很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化。多层叠加后,高层的输入分布变化就会非常剧烈,使得高层需要不断其重新适应底层的参数更新。计算方式如下面公式。
![]()
均值和标准差都通过学习得到,而α和β都是通过学习得到。作用为:1.规范优化空间,保证数据特征分布的稳定性(前向传播的输入分布变得稳定,后向的梯度更加稳定);2.通过对层激活值的归一化,可以加速模型收敛;3.对单个训练样本进行,不依赖于其他数据进行归一化(不同于图像的BN层,文本的长度可能不同,如果不同样本之间进行归一化可能使得训练后部分布不是真实分布)。
位置编码(positional encoding)是attention机制本身不能捕捉位置信息,所以transformer的解决方式是在词嵌入表示+位置编码,每个token的位置信息和它的语义信息(embedding)充分融合,并被传递给后续所有经过复杂变化的序列表达中去。位置编码有两方法,一种是正余弦函数,另一种是可学习的位置编码。正余弦函数位置越小,波长越长,每一个位置对应的位置编码都是唯一的。模型可学习token之前的相对位置关系。计算公式如下图,分偶数位置和奇数位置。使用以下公式表示。
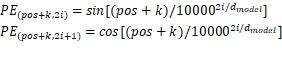
可学习的位置编码是给每一个位置学习一个编码表示。
最后是训练的部分。下面这个例子就是识别语音信号,根据label来看,第一个输出应该是“机”,用one-hot编码得到输出,其实也是一个分类问题。希望的输出和四个字最接近,cross entropy最小。
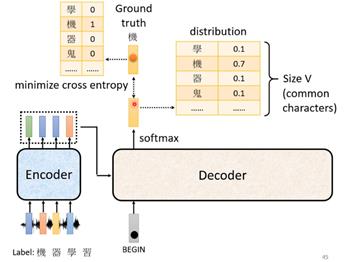
Transformer中的注意力机制有self-attention和cross-attention,其实self-attention也就是Q=K=V=X,attention(Q, K, V)=attention(X, X, X),而cross-attention则是Q!=K=V, Q!=K!=V。
2.2 transformer在视觉上应用
优点包括:1.相比CNN,计算两个位置之间的关联所需的次数不会随着距离增长(任意两个单词的距离变成1);2.突破了RNN不能并行计算的限制,特征抽取能力比RNN系列的模型好(多头注意力每个头的计算是独立的,不同的头可以提取到不同的子空间信息);3.全局信息的有效处理,可编码更长序列(每个词要和其他所有词进行计算);4.可解释性强。
缺点有:1.序列较长时,计算耗时严重;2.需要使用一种方式来表示序列中元素的相对或者绝对位置(有的研究中不加位置信息没有明显差异);3.模型缺乏归纳偏置能力,例如CNN的平移不变性和局部性(也算是一种先验假设),因此在数据不足时不能很好泛化到新任务上;4.模型丧失了捕捉局部特征的能力,RNN+CNN+transformer可能有更好的效果(RNN和CNN具有局部特征能力);5.transformer失去的位置信息其实在NLP中非常重要,论文中在特征向量中加入position embedding也只是一个权宜之计,并没有改变transformer结构上的固有缺陷。
相关论文:
图像表示:Visual Transformer: Token-baesd Image Representation and Preprocessing for Computer Vision
图像分类:1.An Image is Worth 16×16 Words: Transformer for Image Recognition at Scale
2.Transformer in Transformer
图像分割:Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
目标检测:1.End-to-End Object Detection with Transformer
2.End-to-End Human Object Interaction Detection with HOI Transformer
3.Deformable DETR: Deformable Transformer for End-to-End Object Detection
预训练:Pre-Trained Image Processing Transformer
综述:A Survey on Visual Transformer
参考:
百度飞桨顶会论文复现赛直播
李宏毅课程
以上是关于Transformer以及attention机制介绍的主要内容,如果未能解决你的问题,请参考以下文章
NLP-Word Embedding-Attention机制