Transformer系列1Attention is all you need解析Transformer结构总览
Posted 呆呆象呆呆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Transformer系列1Attention is all you need解析Transformer结构总览相关的知识,希望对你有一定的参考价值。
0、Attention Is All You Need
2017NIPS Google
1、背景
Attention机制最早在视觉领域提出,2014年Google Mind发表了《Recurrent Models of Visual Attention》,使Attention机制流行起来,这篇论文采用了RNN模型,并加入了Attention机制来进行图像的分类。
2015年,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,将attention机制首次应用在nlp领域,其采用Seq2Seq+Attention模型来进行机器翻译,并且得到了效果的提升。
2017 年,Google 机器翻译团队发表的《Attention is All You Need》中,完全抛弃了RNN和CNN等网络结构,而仅仅采用Attention机制来进行机器翻译任务,并且取得了很好的效果,注意力机制也成为了大家近期的研究热点。
本文首先介绍常见的Attention机制,然后对论文《Attention is All You Need》进行介绍,该论文发表在NIPS 2017上。
目前主流的处理序列问题像机器翻译,文档摘要,对话系统,QA等都是encoder和decoder框架,
编码器:从单词序列到句子表示
解码器:从句子表示转化为单词序列分布
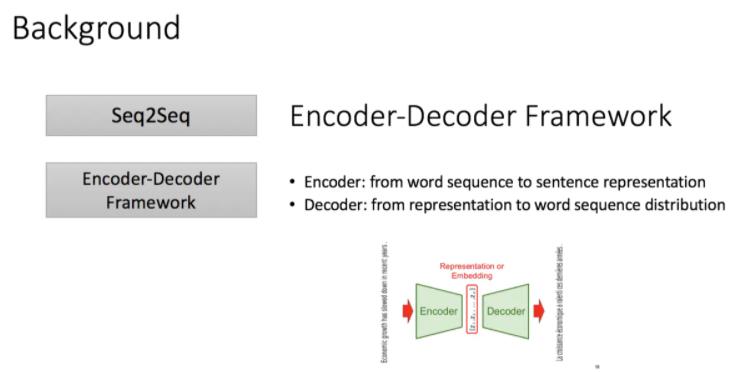
传统的编码器解码器一般使用RNN,这也是在机器翻译中最经典的模型,但正如我们都知道的,RNN难以处理长序列的句子,无法实现并行,并且面临对齐问题。
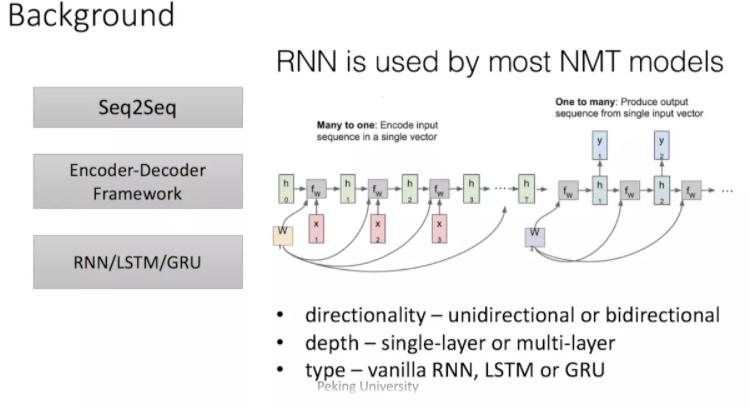
之后这类模型的发展大多从三个方面着手:
- input的方向性 - 单向或双向
- 深度 - 单层或多层
- 类型– RNN,LSTM或GRU

但是依旧收到一些潜在问题的制约,神经网络需要能够将源语句的所有必要信息压缩成固定长度的向量。这可能使得神经网络难以应付长时间的句子,特别是那些比训练语料库中的句子更长的句子;每个时间步的输出需要依赖于前面时间步的输出,这使得模型没有办法并行,效率低;仍然面临对齐问题。
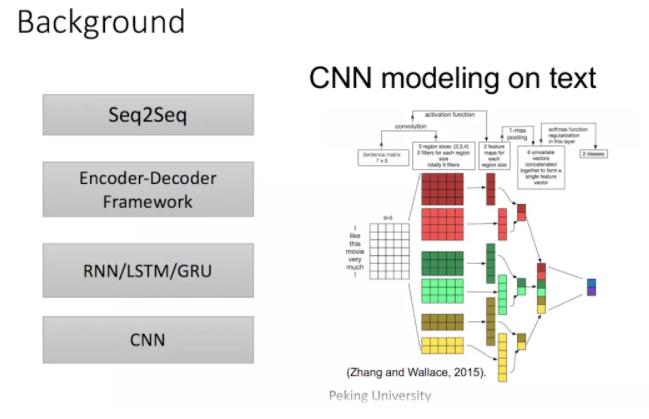
再然后CNN由计算机视觉也被引入到deep NLP中,CNN不能直接用于处理变长的序列样本但可以实现并行计算。完全基于CNN的Seq2Seq模型虽然可以并行实现,但非常占内存,很多的trick,大数据量上参数调整并不容易。
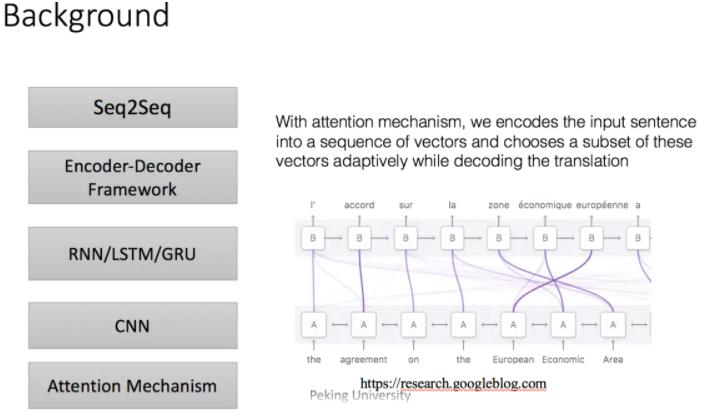
以上这些缺点的话就是由于无论输入如何变化,encoder给出的都是一个固定维数的向量,存在信息损失;在生成文本时,生成每个词所用到的语义向量都是一样的,这显然有些过于简单。为了解决上面提到的问题,一种可行的方案是引入attention mechanism。
深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观察时,其实眼睛聚焦的就只有很小的一块,这个时候人的大脑主要关注在这一小块图案上,也就是说这个时候人脑对整幅图的关注并不是均衡的,是有一定的权重区分的。这就是深度学习里的Attention Model的核心思想。所谓注意力机制,就是说在生成每个词的时候,对不同的输入词给予不同的关注权重。我们可以看一下上面这幅图——通过注意力机制,我们将输入句子编码为一个向量序列,并自适应地选择这些向量的一个子集,同时对译文进行译码,例如where are you——>你在哪?现在我们在翻译“你”的时候给"you"更多的权重,那么就可以有效的解决对齐问题。
2、摘要
主要的序列转换模型基于复杂的循环神经网络或卷积神经网络,其中包括一个编码器和一个解码器。表现最好的模型还通过注意机制连接编码器和解码器。我们提出了一种新的简单网络结构,Transformer,完全基于注意机制,避免了循环和卷积。在两个机器翻译任务上的实验表明,这些模型具有更高的质量,同时具有更强的并行性和更少的训练时间。我们的模型在WMT 2014英德翻译任务中达到28.4 BLEU,比现有的最佳结果(包括集成)提高了2倍以上。在WMT 2014英法翻译任务中,我们的模型在8个gpu上训练3.5天后,建立了一个新的单模型最先进的BLEU分数为41.8,这只是文献中最好模型训练成本的一小部分。我们表明,通过成功地将其应用于具有大量和有限训练数据的英语选区解析,该转换器可以很好地推广到其他任务。
3、评价
抛弃了之前传统的encoder-decoder模型必须结合cnn或者rnn的固有模式,只用attention;
目的是在减少计算量和提高并行效率的同时不损害最终的实验结果;
创新之处在于提出了两个新的Attention机制,分别叫做Scaled Dot-Product Attention和Multi-Head Attention。
4、个人想法与收获总结
1、RNN因为需要沿着输入和输出序列的位置进行因子计算。这种固有的顺序性导致两个问题
- 训练示例中的并行化困难
- 较长的序列长度会出现一些问题,由于内存限制,很长的序列他不能每个位置都被记住,因为内存限制了例子之间的批处理。由于遗忘机制,长时间的序列长度会导致后面的很难收敛。
2、在CNN模型中,从两个任意输入或输出位置关联信号所需的操作数随着位置之间的距离增加所需要的感受野增加,所以操作数量增加
3、多头注意力会抵消因为平均注意力机制导致的降低有效分辨率
4、自我注意,有时也称为内注意,是一种将单个序列的不同位置联系起来的注意机制,目的是为了计算序列的表示法。
5、加性注意力和乘性注意力的讨论
6、多头真的不会影响到实际使用中的计算量吗
5、Transformer结构
绝大部分的序列处理模型都采用encoder-decoder结构,其中encoder将输入序列
(
x
1
,
x
2
,
…
,
x
n
)
(x_{1}, x_{2}, \\ldots, x_{n})
(x1,x2,…,xn)映射到连续表示
z
⃗
=
(
z
1
,
z
2
,
…
,
z
n
)
\\vec{z}=\\left(z_{1}, z_{2}, \\ldots, z_{n}\\right)
z=(z1,z2,…,zn)然后decoder生成一个输出序列
(
y
1
,
y
2
,
…
,
y
n
)
(y_{1}, y_{2}, \\ldots, y_{n})
(y1,y2,…,yn),每个时刻输出一个结果。Transformer模型延续了这个模型,整体架构如下图。
第五部分我们只讲述大致编码器和解码器的结构和堆叠效果
其余在编码器内部的细致结构框架按照如下顺序叙述
- Attention(Mutil-Head Attention) 第六部分
- Feed Forward 第七部分
- Position Encoding 第八部分
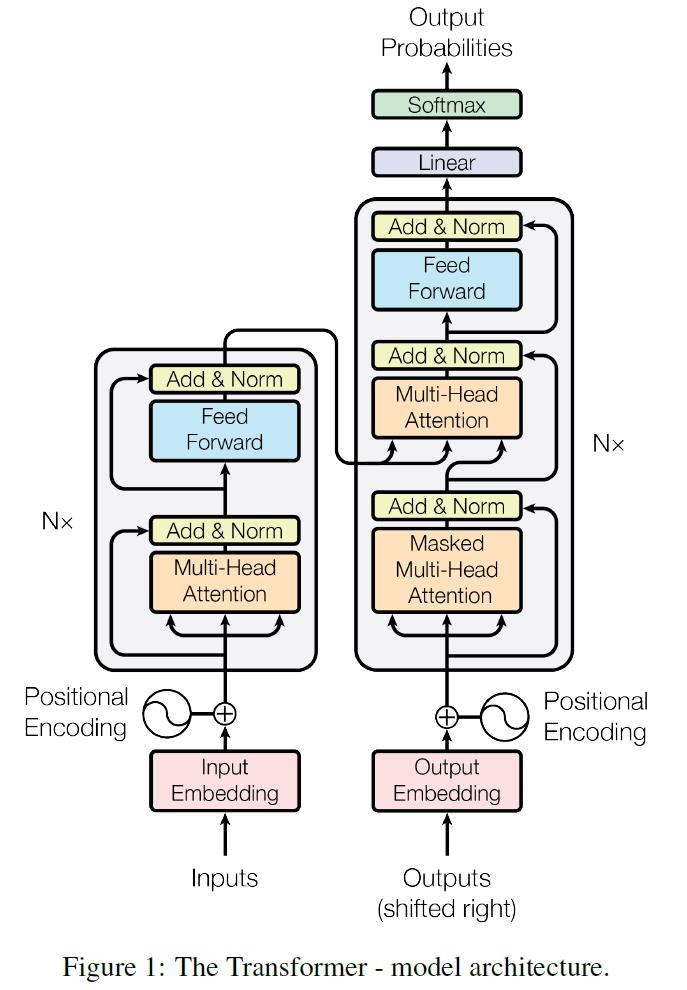
5.1 Encoder
Encoder有
N
=
6
N=6
N=6层,每层包括两个sub-layers:
- 第一个
sub-layer是multi-head self-attention mechanism,用来计算输入的self-attention - 第二个
sub-layer是简单的全连接网络。
在每个sub-layer都模拟了残差网络,每个sub-layer的输出都是
L
a
y
e
r
N
o
r
m
(
x
+
S
u
b
l
a
y
e
r
(
x
)
)
LayerNorm(x + Sublayer(x))
LayerNorm(x+Sublayer(x))
其中
S
u
b
l
a
y
e
r
(
x
)
Sublayer(x)
Sublayer(x) 表示Sub-layer对输入
x
x
x做的映射,为了确保连接,所有的sub-layers和embedding layer输出的维数都相同。
概述:
每个层有两个子层。
第一个子层是多头自我注意力机制(multi-head self-attention mechanism)
第二层是简单的位置的全连接前馈网络(position-wise fully connected feed-forward network)。
在两个子层中会使用一个残差连接,接着进行层标准化(layer normalization)。
网络输入是三个相同的向量 Q Q Q, K K K和 V V V,是
word embedding和position embedding相加得到的结果。为了方便进行残差连接,我们需要子层的输出和输入都是相同的维度。
5.2 Decoder
Decoder也是
N
=
6
N=6
N=6层,每层包括3个sub-layers:
- 第一个是
Masked multi-head self-attention,因为是生成过程,因此在时刻 i i i的时候,大于 i i i的时刻都没有结果,只有小于 i i i的时刻有结果,只能获取到当前时刻之前的输入,也就是一个Mask操作。 - 第二个和第三个
sub-layer与Encoder相同,都是用了残差连接之后接上层标准化
概述:
decoder中的Layer由encoder的Layer中插入一个Multi-Head Attention + Add&Norm组成。输入:
encoder输出的word embedding与输出的position embedding求和做为decoder的输入第一个
Multi-HeadAttention + Add&Norm命名为MA-1层,MA-1层的输出做为下一MA-2层的 Q Q Q输入,MA-2层的 K K K和 V V V输入(从图中看,应该是encoder中第 i ( i = 1 , 2 , 3 , 4 , 5 , 6 ) i(i = 1,2,3,4,5,6) i(i=1,2,3,4,5,6)层的输出对于decoder中第 i ( i = 1 , 2 , 3 , 4 , 5 , 6 ) i(i = 1,2,3,4,5,6) i(i=1,2,3,4,5,6)层的输入)。
MA-2层的输出作为一个前馈层FF的输入,经过AN操作后,经过一个线性+softmax变换得到最后目标输出的概率。对于
decoder中的第一个多头注意力子层,需要添加mask,确保预测位置i的时候仅仅依赖于位置小于 i i i的输出。层与层之间使用的Position-wise feed forward network。
6、Attention机制的实现(Trransformer的一个组成部分)
Attention机制用于计算相关程度,例如在翻译过程中,不同的英文对中文的依赖程度不同,Attention机制通常可以进行如下描述,输入为序列(query)
Q
Q
Q 和 (key-value pairs)
{
K
i
,
V
i
∣
i
=
1
,
2
,
…
,
m
}
\\left\\{K_{i}, V_{i} \\mid i=1,2, \\ldots, m\\right\\}
{Ki,Vi∣i=1,2,…,m},输出为Attention向量,是对key-value pairs中所有values的加权,这个加权的权重是由query和每个key计算出来的(针对不同的输入在不同的键值上反映的相关性不同,计算的权重不同)
其中query、每个key、每个value都是向量,计算如下:
第一步:计算比较 Q Q Q和 K K K的相似度,用 f ( ⋅ ) f(\\cdot) f(⋅)来表示
f ( Q , K i ) , i = 1 , 2 , … , m (1) f\\left(Q, K_{i}\\right), i=1,2, \\ldots, m \\tag{1} f(Q,Ki),i=1,2,…,m(1)
第二步:将得到的相似度进行Softmax操作,进行归一化
α i = e f ( Q , K i ) ∑ j = 1 m f ( Q , K j ) , i = 1 , 2 , … , m (2) \\alpha_{i}=\\frac{e^{f\\left(Q, K_{i}\\right)}}{\\sum_{j=1}^{m} f\\left(Q, K_{j}\\right)}, i=1,2, \\ldots, m \\tag{2} αi=∑j=1mf(Q,Kj)ef(Q,Ki),i=1,2,…,m(2)
第三步:针对计算出来的权重 α i \\alpha_{i} αi,通过权重对 V V V中所有的values进行加权求和计算,得到Attention向量
∑ i = 1 m α i V i (3) \\sum_{i=1}^{m} \\alpha_{i} V_{i} \\tag{3} i=1∑mαiVi(3)
通常第一步中计算方法包括以下四种:
- 点乘
dot productf ( Q , K i ) = Q T K i f\\left(Q, K_{i}\\right)=Q^{T} K_{i} f(Q,Ki)=QTKi
- 权重
Generalf ( Q , K i ) = Q T W K i f\\left(Q, K_{i}\\right)=Q^{T} W K_{i} f(Q,Ki)=QTWK