Flink内核原理学习任务调度流程
Posted oahaijgnahz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink内核原理学习任务调度流程相关的知识,希望对你有一定的参考价值。
Flink内核原理学习之 任务调度流程
文章目录
一、Flink中Gragh的概念
1.1各类Gragh概念
Flink中的执行图分成四层: StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
- StreamGraph: 根据用户通过 StreamAPI 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph: StreamGraph 经过优化后生成了JobGraph,提交给 JobManager 的数据结构。 主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点(算子链),这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph: JobManager 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。
- 物理执行图: JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个 TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
1.2 Gragh细节与转换过程
例如下面实例WordCount代码的Gragh转换:
public static void main(String[] args) throws Exception {
// 检查输入
final ParameterTool params = ParameterTool.fromArgs(args); ...
// 构建执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// get input data DataStream<String> text =
env.socketTextStream(params.get("hostname"), params.getInt("port"), '\\n', 0);
DataStream<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1" .keyBy(0)
.sum(1);
counts.print();
// execute program
env.execute("WordCount from SocketTextStream Example"); }
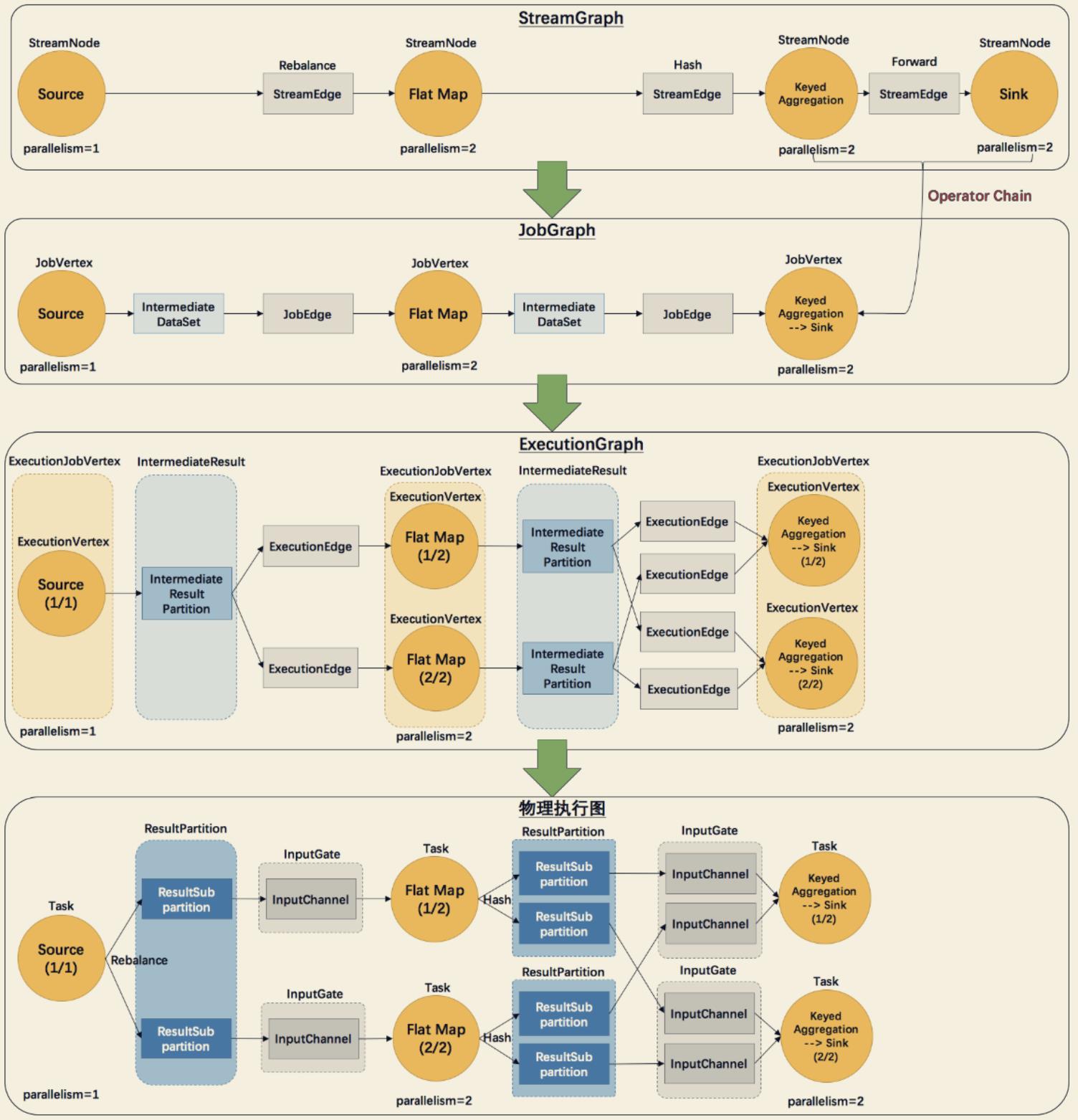
上图中:
- StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
- StreamNode: 用来代表 operator 的类,并具有所有相关的属性,如并发度、入边
和出边等。- StreamEdge: 表示连接两个 StreamNode 的边。
- 此处注意:并不是每一个 StreamTransformation 都会转换成 runtime 层中物理操作。有一些只是逻辑概念,比如 union、split/select、partition 等这些算子并不会改变数据本身而只是改变数据位置的算子只会形成虚节点,在下游StreamNode添加Edge时将此信息写到Edge中
- 看一个例子:
DataStream<String> text = env.socketTextStream(hostname,port); text.flatMap(new LineSplitter()).shuffle().filter(new MyFilter()).print();
上面这个算子链的StreamGragh生成,首先会在 env 中生成一棵 transformation 树,用 List<Transformation<?>>保存。其结构图如下:
其中符号 * 为 input 指针,指向上游的 transformation,从而形成了一棵 transformation 树。然后,通过调用 StreamGraphGenerator.generate(env, transformations)来生成 StreamGraph。自底向上递归调用每一个 transformation,也就是说处理顺序是 Source->FlatMap->Shuffle->Filter->Sink。具体步骤为:
- 首先处理的 Source,生成了 Source 的 StreamNode。
- 然后处理的 FlatMap,生成了 FlatMap 的 StreamNode,并生成 StreamEdge 连接上游 Source 和 FlatMap。由于上下游的并发度不一样(1:4),所以此处是 Rebalance 分区。
- 然后处理的 Shuffle,由于是逻辑转换,并不会生成实际的节点。将 partitioner 信息暂存 在 virtuaPartitionNodes 中。
- 在处理 Filter 时,生成了 Filter 的 StreamNode。发现上游是 shuffle,找到 shuffle 的上游 FlatMap,创建 StreamEdge 与 Filter 相连。并把 ShufflePartitioner 的信息写到 StreamEdge 中。
- 最后处理 Sink,创建 Sink 的 StreamNode,并生成 StreamEdge 与上游 Filter 相连。由于上下游并发度一样(4:4),所以此处选择 Forward 分区。
最后可以通过 UI 可视化 来观察得到的 StreamGraph。



- JobGraph:StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据
结构(主要做了顶点和边的转化、加入中间数据集、算子链优化)。在源码中重点做了对StreamGragh做BFS遍历,生成JobVertex、JobEdge并尽可能将多的节点形成Chain,由于JobGragh涉及传输存储,所以也做了很多配置上的序列化工作。
- JobVertex: 经过优化后符合条件的多个 StreamNode 可能会 chain 在一起生成一个
JobVertex,即一个 JobVertex 包含一个或多个 operator,JobVertex 的输入是 JobEdge,输出是 IntermediateDataSet。- IntermediateDataSet: 表示 JobVertex 的输出,即经过 operator 处理产生的数据集。 producer 是 JobVertex,consumer 是 JobEdge。
- JobEdge: 代表了 Job Graph 中的一条数据传输通道。source 是 IntermediateDataSet, target 是 JobVertex。即数据通过 JobEdge 由 IntermediateDataSet 传递给目标 JobVertex。
- StreamGragh到JobGragh的算子链形成分析:
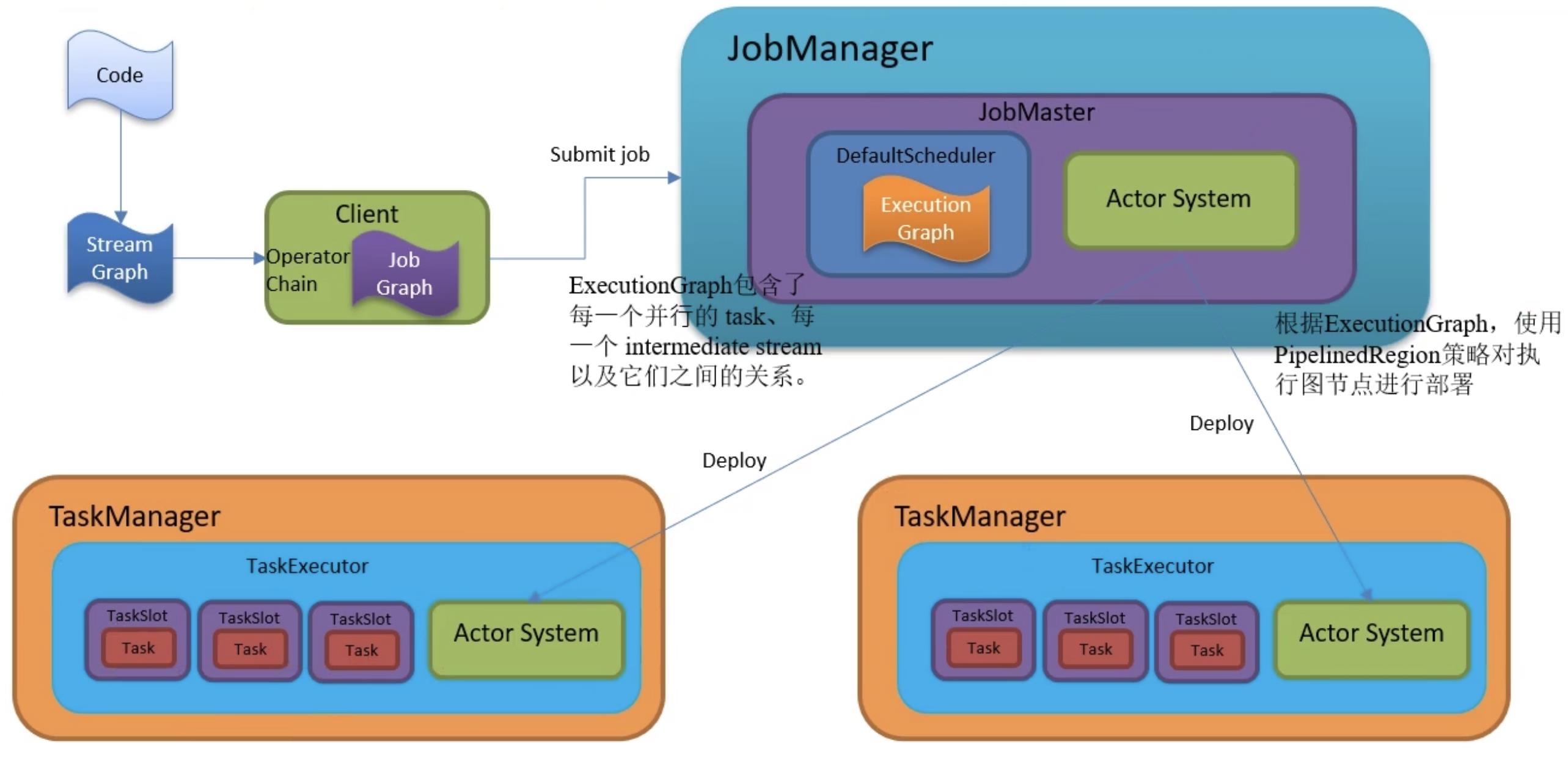
setChaining() 会对 Source 调用 createChain(),该方法会递归调用下游节点,从而构建出 node chains。createChain() 会分析当前节点的出边,根据 Operator Chains 中的是否可成算子链的条件,将出边分成 chainalbe 和 noChainable 两类(个人理解是forword的是可以chain的),并分别递归调用自身方法。之后会将 StreamNode 中的配置信息序列化到 StreamConfig 中。如果当前不是 chain 中的子节点(noChainable),则会构建 JobVertex 和 JobEdge 相连。如果是 chain 中的子节点(chainable),则会将 StreamConfig 添加到该 chain 的 config 集合中。一个 node chains,除了 headOfChain node 会生成对应的 JobVertex, 其余的 nodes 都是以序列化的形式写入到 StreamConfig 中,并保存到 headOfChain 的 CHAINED_TASK_CONFIG 配置项中。直到部署时,才会取出并生成对应的ChainOperators。
每个 JobVertex 都会对应一个可序列化的 StreamConfig, 用来发送给 JobManager 和 TaskManager。最后在 TaskManager 中起 Task 时,需要从这里面反序列化出所需要的配置信 息, 其中就包括了含有用户代码的 StreamOperator。

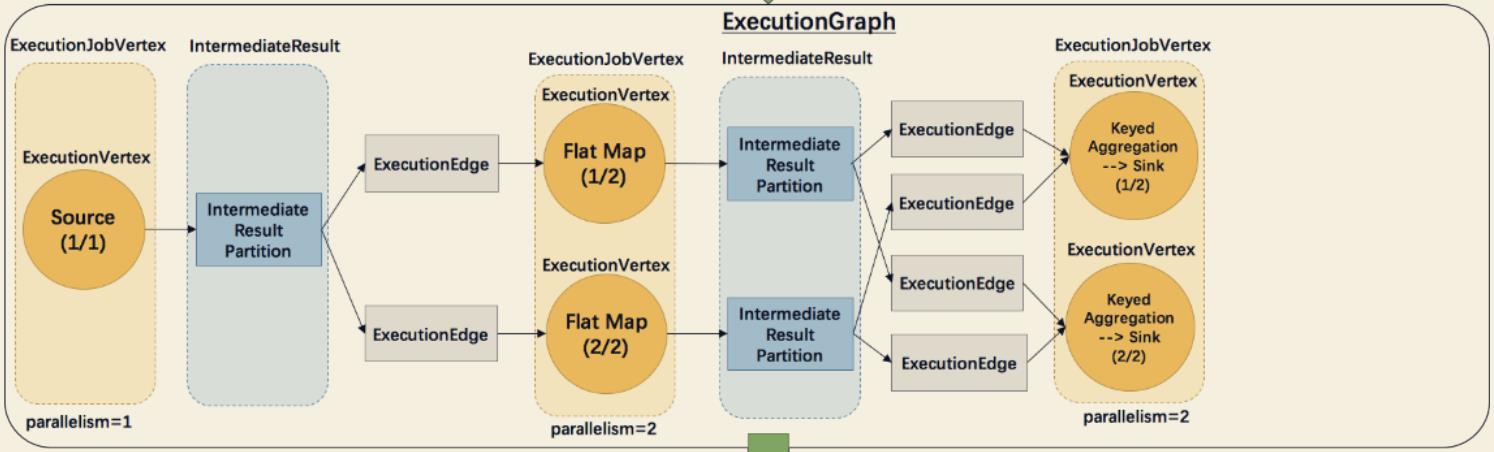
- ExecutionGraph: JobManager(JobMaster在创建时创建的调度器中) 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构(主要做了顶点、中间数据集、边的并行化)。注意创建时的顺序,在ExecutionJobVertex根据并行度并行化并根据其JobEdge获取其前置中间数据集;前置中间数据集并行化后,ExecutionEdge根据两边的数量生成对应的连接关系(看图理解)。
- ExecutionJobVertex: 与 JobGraph 中的 JobVertex 一一对应。每一个 ExecutionJobVertex 都有和并发度一样多的 ExecutionVertex。
- ExecutionVertex: 表示 ExecutionJobVertex 的其中一个并发子任务,输入是 ExecutionEdge,输出是 IntermediateResultPartition。
- IntermediateResult: 和 JobGraph 中的 IntermediateDataSet 一一对应。一个 IntermediateResult 包含多个 IntermediateResultPartition,其个数等于该 operator 的并发度。
- IntermediateResultPartition: 表示 ExecutionVertex 的一个输出分区,producer 是 ExecutionVertex,consumer 是若干个 ExecutionEdge。
- ExecutionEdge: 表示一种连接关系,source 是 IntermediateResultPartition, target 是 ExecutionVertex。source 和 target 都只能是一个。
- Execution: 是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM 和 TM 之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。
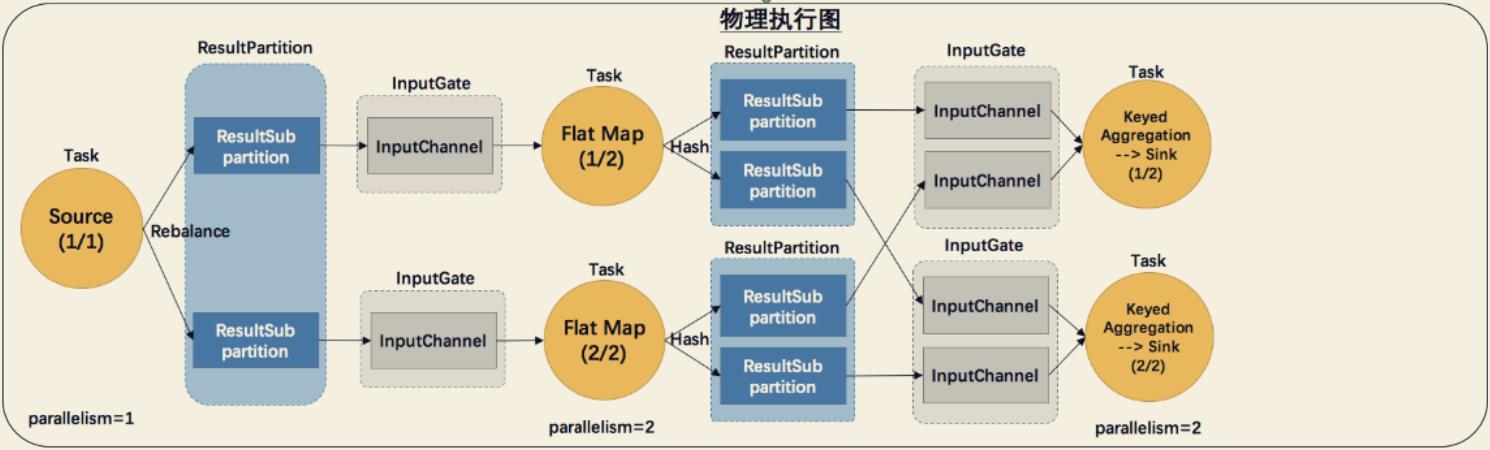
- 物理执行图(Task的调度和执行): JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。 JobMaster在调度器中调度并开始部署,对ExecutionGragh中的图数据结构进行描述,最后将ExecutionGragh中的ExecutionVertex转为Task进行部署
taskmanagerGateway.submitTask()。JobMaster通过RPC调用 TaskManager 的网关(最后转发到TaskExecutor的网关进行处理)。
TaskExecutor中收到部署消息后新建Task并启动新线程进行处理,处理逻辑中底层会调用ProcessElement(很熟悉吧)来处理用户自定义函数类的重写方法对数据处理,并通过采集器收集数据。
- Task: Execution 被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹
了具有用户执行逻辑的 operator。- ResultPartition: 代表由一个 Task 的生成的数据,与 ExecutionGraph 中的
IntermediateResultPartition 一一对应。- ResultSubpartition: 是 ResultPartition 的一个子分区。每个 ResultPartition 包含多个
ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定。- InputGate: 代表 Task 的输入封装,与 JobGraph 中 JobEdge 一一对应。每个 InputGate消费了一个或多个的 ResultPartition。
- InputChannel: 每个 InputGate 会包含一个以上的 InputChannel,与 ExecutionGraph
中的 ExecutionEdge 一一对应,也和 ResultSubpartition 一对一地相连,即一个 InputChannel 接收一个 ResultSubpartition 的输出。
二、调度
调度有几个重要的组件:
- 调度器: SchedulerNG及其子类、实现类
- 调度策略: SchedulingStrategy及其实现类
- 调度模式: ScheduleMode包含流和批的调度,有各自不同的调度模式
2.1 调度器
调度器作用:
- 作业的生命周期管理,如作业的发布、挂起、取消
- 作业执行资源的申请、分配、释放
- 作业的状态管理,作业发布过程中的状态变化和作业异常时的 FailOver 等
- 作业的信息提供,对外提供作业的详细信息
2.2 调度模式
ScheduleMode 决定如何启动 ExecutionGraph 中的 Task。Flink 提供 3 中调度模式:
- Eager 调度
适用于流计算。一次性申请需要的所有资源,如果资源不足,则作业启动失败。 - 分阶段调度
LAZY_FROM_SOURCES 适用于批处理。从 SourceTask 开始分阶段调度,申请资源的时候,一次性申请本阶段所需要的所有资源。上游 Task 执行完毕后开始调度执行下游的 Task, 读取上游的数据,执行本阶段的计算任务,执行完毕之后,调度后一个阶段的 Task,依次进行调度,直到作业完成。 - 分阶段 Slot 重用调度
LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST 适用于批处理。与分阶段调度基本一样,区别在于该模式下使用批处理资源申请模式,可以在资源不足的情况下执行作 业,但是需要确保在本阶段的作业执行中没有 Shuffle 行为。
2.3 调度策略
调度策略有三种实现:
- EagerSchedulingStrategy: 适用于流计算,同时调度所有的task
- LazyFromSourcesSchedulingStrategy: 适用于批处理,当输入数据准备好时(上游处
理完)进行 vertices 调度。 - PipelinedRegionSchedulingStrategy: 以流水线的局部为粒度进行调度 PipelinedRegionSchedulingStrategy 是 1.11 加入的,从 1.12 开始,将以 pipelined region
为单位进行调度。pipelined region 是一组流水线连接的任务。这意味着,对于包含多个 region 的流作业,在开始部署任务之前,它不再等待所有任务获取 slot。取而代之的是,一旦任何 region 获得了足够的任务 slot 就可以部署它。对于批处理作业,将不会为任务分配 slot,也不会单独部署任务。取而代之的是,一旦某个 region 获得了足够的 slot,则该任务将与所有其他任务一起部署在同一区域中。
2.4 调度过程总结
以上是关于Flink内核原理学习任务调度流程的主要内容,如果未能解决你的问题,请参考以下文章
(2021-03-26)大数据学习之Flink安装部署以及任务提交/调度详解
5.Flink原理初探角色分工执行流程图生成DataFlow,Operator,Partition,Parallelism,SubTaskOperatorChain和Task任务槽槽共享