(2021-03-26)大数据学习之Flink安装部署以及任务提交/调度详解
Posted Mr. Dreamer Z
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(2021-03-26)大数据学习之Flink安装部署以及任务提交/调度详解相关的知识,希望对你有一定的参考价值。
Flink学习之安装部署以及API方法
1.Flink快速安装
Flink下载地址
选择对应的版本,然后进入之后选择带有scala的tagz包。之所以选择是因为Flink的runtime层使用到了akka是由scala写的。
下载成功之后上传到服务器上。
解压
tar -zxvf flink-1.12.0-bin-scala_2.12.tgz
如果出现权限问题,那么修改权限
chown -R root:root /root/flink-1.12.0-bin
修改文件夹名称
mv flink-1.12.0-bin flink
ok,操作完这些部署之后。我们启动Flink!
进入bin目录下
/start-cluster.sh
使用jps查看是否启动成功
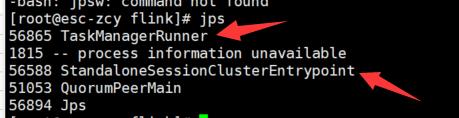
如果看到上图指向的进程,那么说明启动成功。
之后,关闭你的防火墙,开放8081端口。即可在本地上看到对应的管理页面。此时就代表操作成功!
到这里,flink的安装启动就全部完成了。
2. Flink运行时组件
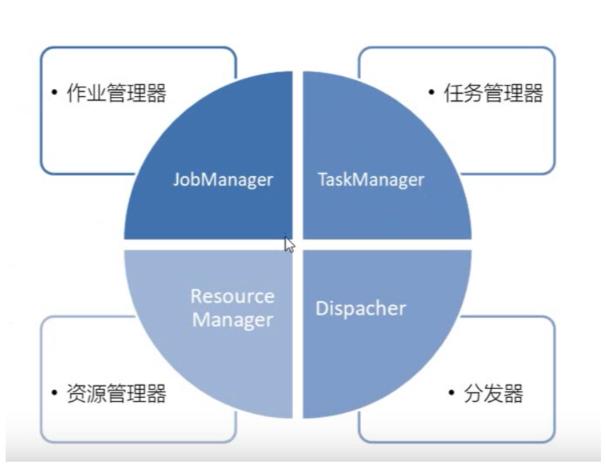
运行时组件描述(如果我自己来写这段描述,就说我抄袭别人的博客。。。无语)
说了那么多,来简单整理一下这个四个组件的功能:
作业管理器(JobManager):负责任务的调度以及资源分配。
任务管理器(TaskManager):负责执行任务。
资源管理器(ResourceManager):负责管理任务管理器中的插槽slots。
分发器(Dispatcher):不是必须品,取决于应用提交运行的方式。提供了REST接口。相当于一个桥梁。
3. Flink任务提交流程以及任务调度

1.App提交应用之后
2.Dispatcher再将应用启动JobManager并且将改应用提交给它,所以说它相当于一个桥梁的原因。
3.JobManager拿到的需要执行的任务,去向ResourceManager申请Slots(Slots执行一个独立任务/线程所需要的计算资源的最小单元)。
4.ResourceManager只是负责管理TaskManager中的插槽。所以ResourceManager启动TaskManager。
5.TaskManager启动之后将自己的插槽数量告诉ResourceManager。
6.ResourceManager根据JobManager需要的插槽数量,让TaskManager提供相应的功能(也就是提供插槽)给JobManager。
7.TaskManager收到命令之后,告诉JobManager:我已经准备好了插槽,你把需要在slots中执行的任务提交给我吧。提供插槽给JobManager调用。
8.JobManager向对应的插槽分配任务。
9.TaskManger之间的数据交换(最后会补充为什么会数据交换)
standAlone模式中ResourceManger是没有作用的。
3.1 任务提交流程(YARN)
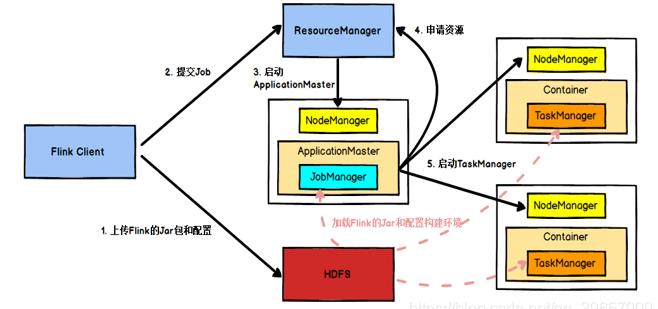
在Flink任务提交后:
- Client向HDFS上传Flink的Jar包和配置。
- 向Yarn ResourceManager提交任务。
- ResourceManager分配Container资源并通知对应的NodeManager启动ApplicationMaster。
- ApplicationMaster启动后加载Flink的Jar包和配置构建环境。
- 启动JobManager,之后ApplicationMaster向ResourceManager申请资源启动TaskManager。
- ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点的NodeManager启动TaskManager,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager。
- TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
抛开这一长串的任务分解不看,其实yarn模式就是相当于在集群模式下的一个管理者。在分布式的场景下,yarn任务模式是非常常见的。在yarn模式下,ApplicationMaster/Worker的ResourceManager都没有资格在进行slots的管理和调度,统统由yarn的ResourceManager进行管理。
3.2 任务调度原理
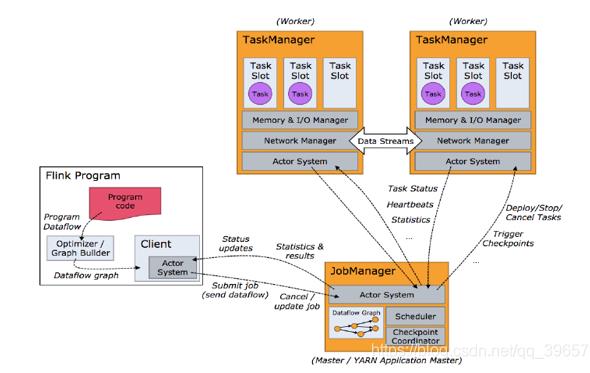
其实逻辑很简单:
Flink Program:我们写一串代码,运行之后。它会生成一个数据流图(DataFlow graph),然后通过客户端client(可能是yarn,可能是singlealone、dispatcher)推送给JobManager。客户端只负责提交任务(Submit job)或者取消任务(Cancel job)。
JobManager:JobManager收到这个数据流图之后,就会对这个数据流图进行分析处理,最后生成一个可执行的执行图。等待所以任务分配出去并且执行完毕之后,JobManager会返回给Client一些结果或者状态。
TaskManager:JobManager分配任务给TaskManger或者停止任务,都需要发送指令。TaskManager之间会有数据交互。
3.3 TaskManager 与Slots
3.3.1 作用与关系

group运行在独立的JVM中。而当一个TaskManager多个slot时,多个subtask可以共同享有一个JVM,而在同一个JVM进程中的task将共享TCP连接和心跳消息,也可能共享数据集和数据结构,从而减少每个task的负载。
其实有一个并行度的概念。大家可以看到上图,Source[1]Map[1]和Source[2]Map[2]。它们实际上是一个任务(其实是因为进行了任务合并,下面的任务链概念会讲到),但是由于设置了并行度为2,所以拆分成了两个子任务。并行度实际上就是多线程执行,为的就是尽量的高效率执行。
刚刚Flink的调度图上,第9步,有一个数据交换。比如:如上图所示:JobManager获得了两个TaskManager的执行权力(也就是说这个两个TaskManager有对应的可用的slot)。然而由于两个TaskManagerManager的插槽都是可用的·,而分配任务到对应的slot中可能并不是一个TaskManager的。这就能说明为什么会有数据交互的现象了。举个最直观的例子:4+4=8.设置并行度之后,变为2+2=4和2+2=4。但是实际上最终的到的会是8.所以这两个子任务会合并数据(交互)。

子任务可以共享slot的条件是必须是前后发生的不同的任务的子任务。同一任务是不能的,因为设置并行度的原因就是为了把任务拆开,使它并行执行。
可以共享好处:比如其他slot挂了,其他任务的子任务依然可以进入这个slot。是一个充分利用的问题。
也可以设置slot共享组,一个组中的任务可以共享一个slot。
3.3.2 任务执行资源合理占用
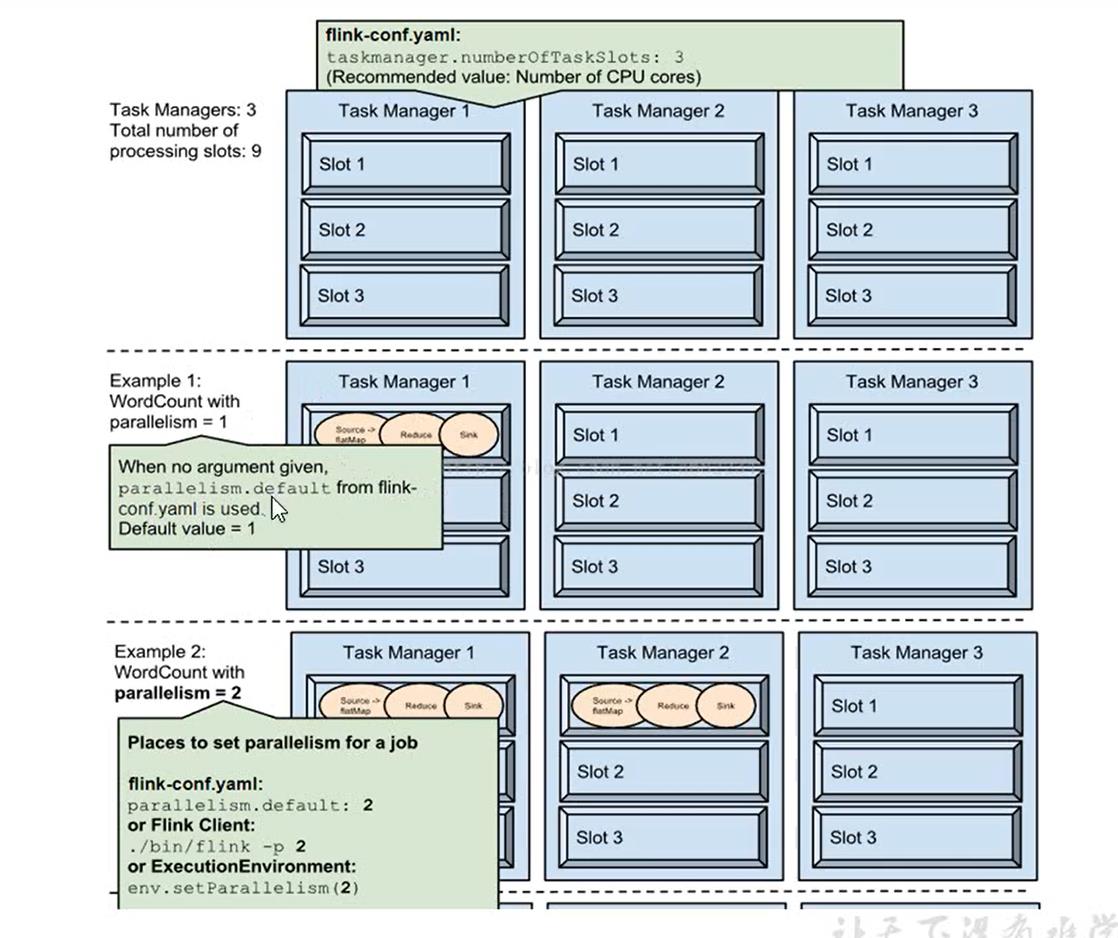
如上图所示:
1.有三个TaskManager,我们在配置文件中配置了每个TaskManager有3个slot。
taskmanager.numberOfTaskSlots=3
所以总共有9个slot
2.我们执行一个操作,设置并行度为1.那么该任务不会进行拆分,所以只占用一个slot
3.同理2,由于资源太过于浪费。我们将并行度设置为2,由此占用2两个slot,但是由于我们总共有9个slot,依然没办法资源运用最大化。

4.由于总共有9个slot,我们将整个任务的并行度设置为9。所以的slot都被使用了。
5.这里将sink的并行度也设置为9的话,会出现问题。例如:我们最终的目的是写入文件,但是由于有9个线程,写入的顺序肯定会出现偏差。所以单独设置sink的并行度为1.(最好不要设置slink的并行度,让它默认为1。避免出现数据有误的问题)
4.程序与数据流

- 所有的Flink程序都是由三部分组成的:Source,Transformation和Sink。
- Source负责读取数据源,Transformation利用各种算子进行处理加工,Sink负责输出。

4.1 数据传输形式
算子之间传输数据的形式可以是one-to-one模式,也可以是redistributing的模式。
One-to-One:
类似于map,filter,flatMap等算子。它们会一直在一个分区执行任务,不会被打乱顺序且不会进行重分区的调整。比如:map执行完了之后,接着有一个filter算子,这个算子将会继续在本区进行操作。不需要做任何重分区的操作。
redisresdtributing:
stream的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如:keyBy基于hashCode重分区,而broadcast和rebalance会随机重新分区,这些算子都会引起redistribute过程,而redistribute过程就类似于Spark中的shuffle过程。
4.2 任务链(Operator Chains)
- Flink采用一种称为任务链的优化技术 ,可以在特定条件下减少本地通信的开销。为了满足任务链的要求,必须将两个或多个算子设为相同的并行度,并通过本地转发(local forward)的方式进行连接。
- 相同并行度的one-to-one操作,Flink这样相连的算子链接在一起形成一个task,原来的算子成为里面的subtask。
- 并行度相同,并且是一个one-to-one操作,两个条件缺一不可。
总的来说:合并任务必须是满足三个条件
1.并行度相同
2.是one-to-one操作(你可以把one-to-one操作认为是map,filter,flatMap等算子)
3.不能是不同的slot组
如下图:
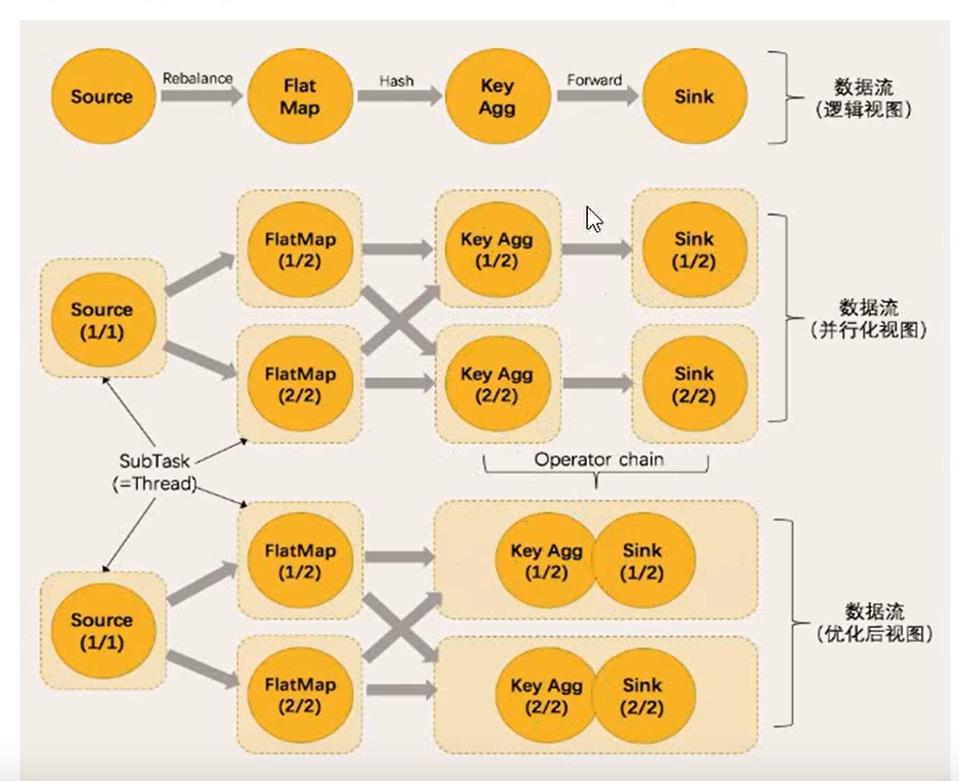
Source、FlatMap,KeyAgg和Slink
Source的并行度为1,FlatMap为2。不能合并任务
FlatMap和KeyAgg的并行度都是2,但是KeyAgg会进行重分区。不能合并任务
KeyAgg和Sink并行度都是2,且他们是one-to-one操作,所以可以合并。
大致的总结一下slots:
Slots执行一个独立任务/线程所需要的计算资源的最小单元。(是一个资源的概念)
一个TaskManager中有几个slots代表可以有几个线程同时执行,一个TaskManager至少有一个slots。Slots默认允许多个子任务共享的。一个slots可以是多个任务共享的。一个组内的任务都可以共享一个slots.
以上是关于(2021-03-26)大数据学习之Flink安装部署以及任务提交/调度详解的主要内容,如果未能解决你的问题,请参考以下文章