Flink内核原理学习任务提交流程
Posted oahaijgnahz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink内核原理学习任务提交流程相关的知识,希望对你有一定的参考价值。
Flink内核原理学习之任务提交流程
文章目录
首先要知道的是,Flink作业提交是由PipelineExecutor(流水线执行器)在Flink Client生成JobGraph后将作业提交给集群的重要环节。PipelineExecutor按照集群作业执行模式主要分为Session、Per-Job、Local模式,其中Local是本地调试时使用的所以不参与后续讨论。
一、Flink任务提交流程(yarn-per-job模式)
Per-Job模式中每个任务都会在YARN上重新启动集群。根据官方文档说法,也就是JobManager创建后,然后将作业提交给在这个进程中运行的 Dispatcher,然后根据作业的资源请求惰性的分配 TaskManager。一旦作业完成,Flink Job 集群将被拆除。
由于 ResourceManager 必须应用并等待外部资源管理组件来启动 TaskManager 进程和分配资源,因此 Flink Job 集群更适合长期运行、具有高稳定性要求且对较长的启动时间不敏感的大型作业。
1.1 总体流程解析
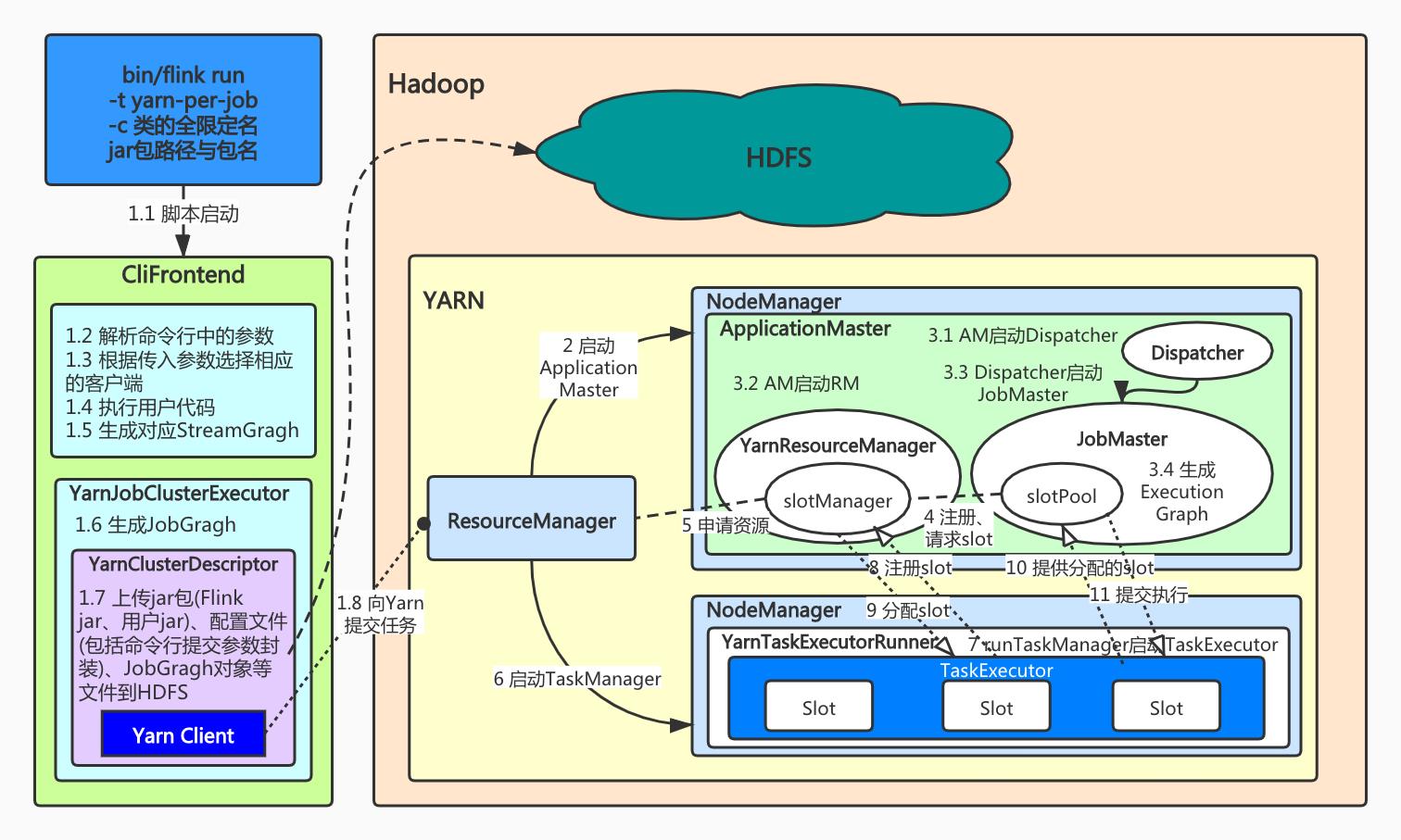
具体流程如下(未对应图中的序号,有扩充或精炼):
- 客户端阶段:
- 首先使用命令行
flink run -t yarn-per-job(1.10版本前是flink run -m yarn-cluster)来提交Per-Job任务,后面可以带其他参数,但必须指定自己作业的类全限定名和jar包。- 命令行执行后是通过CliFrontend(客户端前端)中的main方法进入后续的作业提交流程。
- 客户端中主要做了命令行参数解析并根据命令类型封装相应的客户端对象。
- 执行用户作业类中main方法中的代码,生成对应的StreamGragh。
- 在
YarnJobClusterExecutor(PipelineExecutor)中生成JobGragh。- 生成YarnClusterDescriptor,主要是上传资源到HDFS中,包括jar包(Flink的jar包和用户jar包)、应用配置(flink-conf.yaml、log4j.properties)、其他相关文件(配置类文件、JobGragh对象等)。
- 创建Yarn客户端准备向Yarn申请创建ApplicationMaster(JobManager)。
- Yarn集群阶段:
- Yarn的ResourceManager为ApplicationMaster申请到容器后,以
YarnJobClusterEntryPoint作为集群启动入口开启JobManager进程。- AM中首先创建和启动Dispatcher和YarnResourceManager(这是Flink内部的RM,后简称YRM)。
- 在Dispatcher读取到JobGragh后,为此作业构建一个JobMaster,将作业交给JobMaster,在其中将JobGragh构建为ExecutionGragh。
- JobMaster中的SlotPool向YRM中的SlotManager申请资源。而SlotManager需要向Yarn的RM请求资源(requestNewWorker),YRM先将资源请求加入等待队列,通过心跳向YARN的RM申请新的容器来启动TaskManager进程。
- 容器就绪后,YRM在容器中启动TaskManager进程(入口为
YarnTaskExecutorRunner),调用runTaskManager启动TaskExecutor(真正的实例)。- TaskExecutor向SlotManager反向注册,汇报当前可用slot数量。SlotManager返回分配slot的信息。
- TaskExecutor根据分配信息,向对应的JobMaster提供slot。JobMaster得到消息后,向对应的slot提交任务开始执行(
submitTask)
1.2 具体组件解释
JobManager
- Dispatcher:是一个Rest接口(对于Session模式来说),不负责实际的调度执行方面的工作,而是接收JobGragh后为作业创建一个JobMaster,将工作交给JobMaster。
- JobMaster:负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster(内含soltPool)。
- ResourceManager :负责 Flink 集群中的资源提供、回收、分配 。其中的slotManager管理 task slots,这是 Flink 集群中资源调度的单位(请参考TaskManagers)。Flink 为不同的环境和资源提供者(例如 YARN、Mesos、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
TaskManager
- TaskManager(也称为 worker)执行作业流的 task,并且缓存和交换数据流。
必须始终至少有一个 TaskManager。在 TaskManager 中资源调度的最小单位是 task slot。TaskManager 中 task slot 的数量表示并发处理 task 的数量。请注意一个 task slot 中可以执行多个算子(算子链优化)
关于Gragh相关的知识将在Flink任务调度中介绍。
二、Flink任务提交流程(yarn-session模式)
Session模式顾名思义,Flink集群在Yarn上长期存在,适用于执行一些比较小而快的任务。优缺点很明显,优点在于集群长期存在省去了Dispatcher、ResourceManager、TaskManager的重复创建;缺点如官方文档中介绍的如果TaskManager 崩溃,则在此 TaskManager 上运行 task 的所有作业都将失败;类似的,如果 JobManager上发生一些致命错误,它将影响集群中正在运行的所有作业。
而这种模式的首次提交作业,流程除了客户端方面的不同外其他流程与Per-Job几乎相同。当新的任务到来时,Dispatcher根据不同作业提交的JobGragh创建对应JobMaster并将工作交给它;在作业调度期间,TaskManager资源不足则由ResourceManager向Yarn请求新的容器来构建新的TaskManager。
以上是关于Flink内核原理学习任务提交流程的主要内容,如果未能解决你的问题,请参考以下文章