如何做一个国产数据库
Posted qianbo_insist
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何做一个国产数据库相关的知识,希望对你有一定的参考价值。
承接上文,继续
1、重新定义数据结构
typedef struct sdata
{
uint32_t index;
char vardata[128];
}sdata;
typedef struct sdata_index
{
uint32_t index;
uint32_t offset;
}sdata_index;
sdata_index 是我们要读到一个内存里面去的,同时,我们会使用内存查找的方式,拿到数据的索引值,在内存里面使用二分查找算法
int binSearch(uint32_t x, sdata_index *a, int n)
{
int low, high, mid;
low = 0;
high = n - 1;
while (low <= high)
{
mid = (low + high) / 2;
if (x < a[mid].index)
high = mid - 1;
else if (x > a[mid].index)
low = mid + 1;
else
return mid;
}
return -1;
}
2、写入数据
修改上一文章中的写函数,数据结构,偏移量计算正确,写入文件,写入的数据在进入函数之间一定要排序
//sdata 必须是排序后数据
//2M 的索引,一半的空间为索引号码,一半的空间为数据偏移地址
// 1024*1024/sizeof(int)
int bfile_write(const char * file,/*uint32_t index_num,*/ sdata data[],int n)
{
#define INDEX_BYTES 2 * 1024 * 1024
int index_num = INDEX_BYTES / sizeof(int)*2; //max index number is 162144
if (n > index_num)
return -1;
FILE * fp = fopen(file, "wb");
if (fp == NULL)
return -1;
fpos_t pos_start = 0;
fpos_t pos_index = 8;
fpos_t pos_data = pos_index + INDEX_BYTES;
fpos_t position = 4 + 4 + INDEX_BYTES + sizeof(data[0].vardata) * n;
fsetpos(fp, &position);
fsetpos(fp, &pos_start);
//写入总索引量
fwrite(&index_num, sizeof(int), 1, fp);
//写入目前索引量
fwrite(&n, sizeof(int), 1, fp);
//排序写入文件,已经排好了序号
//std::sort(&data[0], &data[n], Rule());
int offsetsum = 4+4+INDEX_BYTES;
int len = sizeof(data[0].vardata);
for (int i = 0; i < index_num; i++)
{
//wnum++;
if (i < n)
{
fwrite(&data[i].index, sizeof(int), 1, fp);
fwrite(&offsetsum, sizeof(int), 1, fp);
offsetsum += len;
}
else
{
uint64_t flag = 0;
fwrite(&flag, sizeof(uint64_t), 1, fp);
}
}
offsetsum = 4 + 4 + INDEX_BYTES;
fpos_t pos = offsetsum;
for (int i = 0; i < n; i++)
{
fsetpos(fp,&pos);
fwrite(&data[i].vardata, strlen(data[i].vardata), 1, fp);
pos += sizeof(data[0].vardata);
}
fclose(fp);
return 0;
}
读取数据
定义读的函数,流程为
1 、读出数据最大索引量
2 、读出数据当前记录索引量
3 、读出索引放入内存
这里并不读数据集,后面第三篇再修正读数据,放一部分数据到内存里面。
//2M的空间做索引
sdata_index* bfile_read_index(const char * file,uint32_t &num)
{
size_t nr;
num = 0;
uint32_t indext;//索引总长度
uint32_t indexn;//索引长度,内容为x个索引 indexn <= indext
FILE * fp = fopen(file, "rb");
if (fp == NULL)
return NULL;
//读取最大的index值容量
nr = fread(&indext, sizeof(uint32_t), 1, fp);
if (nr == 0)
{
fclose(fp);
return NULL;
}
//读取存储的索引值
nr = fread(&indexn, sizeof(uint32_t), 1, fp);
if (nr == 0)
{
fclose(fp);
return NULL;
}
num = indexn;
//4字节索引号 4字节偏移地址
uint8_t * index = (uint8_t*)malloc(indexn * sizeof(uint32_t)*2);
nr = fread(index, indexn * sizeof(uint32_t) * 2, 1, fp);
if (nr == 0)
{
fclose(fp);
free(index);
return NULL;
}
return (sdata_index*)index;
}
定义从数据库中读取某一个索引值到内存中
int bfile_read(const char * file,uint32_t offset, char *buffer,size_t len)
{
FILE * fp = fopen(file, "rb");
fpos_t pos_start = offset;
fsetpos(fp, &pos_start);
size_t n =fread(buffer, sizeof(char)*len, 1, fp);
fclose(fp);
if (n != len)
return -1;
return 0;
}
4、定义主函数执行
int main()
{
sdata data[100];
//srand(1000);
for (int i = 0; i < 100; i++)
{
//模拟收集到的数据
data[i].index = i;
sprintf(data[i].vardata, "the data is %ld", data[i].index);
}
//std::sort(&data[0], &data[100], Rule());
for (int i = 0; i < 100; i++)
{
cout<<data[i].index<<"-->"<<data[i].vardata << endl;
}
bfile_write("./test.db", data, 100);
uint32_t num;
sdata_index *rdata =bfile_read_index("./test.db",num);
cout << "the index number is " << num << endl;
cout << "now read the value of index x" << endl;
string s;
cin>>s;
int v = atoi(s.c_str());
int ret = binSearch(v, rdata, num);
sdata_index *p = rdata;
p += ret;
uint32_t offset = p->offset;
char buffer[128];
bfile_read("./test.db", offset, buffer, 128);
cout << buffer << endl;
return 0;
}
5、执行插入数据函数结果打印
查看文件已经写入
6、数据查询
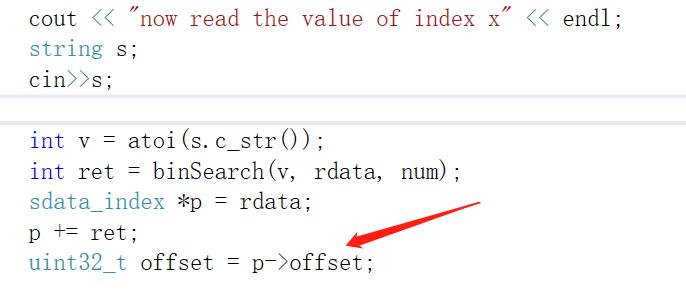
输入数据查询值,如89,意思是查询第89索引的值,
首先获取内存索引中偏移量的值offset,查询的时候使用binSearch 二分查找
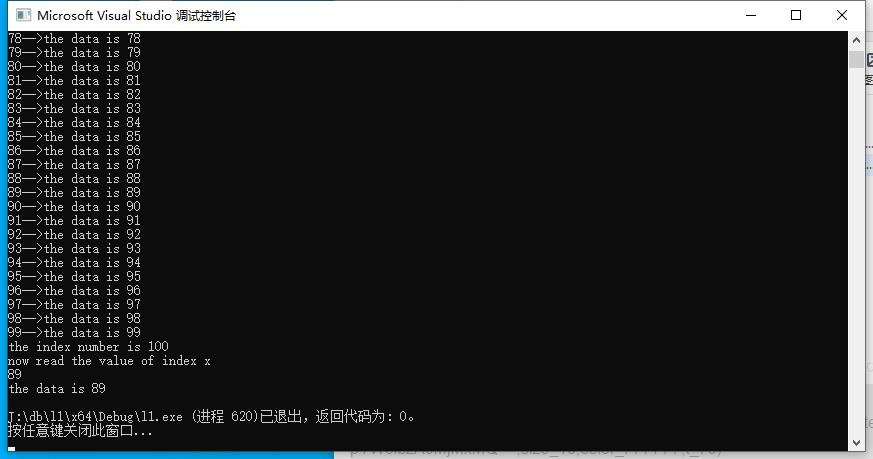
最后打开文件,偏移到offset处,取出拷贝里面的值,打印出 the data is 89
一个小型的数据库就这样出来了,简陋,暂时是示例,会慢慢补充起来。等待我的第三篇吧
以上是关于如何做一个国产数据库的主要内容,如果未能解决你的问题,请参考以下文章