颜水成团队开源VOLO:无需额外数据,首次在ImageNet上达到87.1%的精度
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了颜水成团队开源VOLO:无需额外数据,首次在ImageNet上达到87.1%的精度相关的知识,希望对你有一定的参考价值。
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
自打Transformer横空出世以来,它在CV领域就取得了很多不俗的效果。
比如采用纯Transformer架构的ViT在很多图像分类任务中表现都不输最先进的CNN。
但在没有额外数据的情况下,Transformer的性能仍然比不过它们。
不过,Transformer并不服气。

这不,最近一个叫做VOLO的Transformer变体,自称打破了这个僵局:
无需任何额外训练数据,就在ImageNet数据集上达到了87.1%的top-1精度,打破了基于CNN的SOTA模型(NFnet )此前保持的86.5%的最好记录!
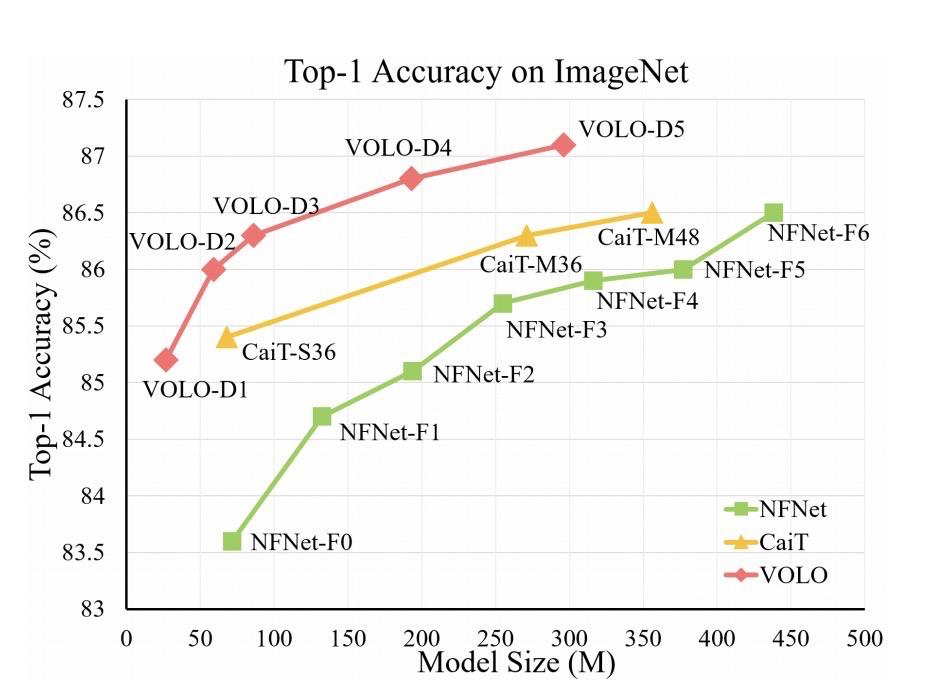
Transformer因此又扬眉吐气了:我们真的不比CNN差。
那它是如何做到的呢?
引入outlook注意力
这个基于自注意力的图像分类模型VOLO,出自颜水成领导的Sea AI Lab团队与新加坡国立大学。

他们在研究中发现,ViT在ImageNet图像分类上的性能受到限制的主要因素是:在将精细级(fine-level )的特征编码为token的表示过程中比较低效。
为了解决这个问题,他们引入了一种新的outlook注意力,并提出了一个简单而通用的架构,称为Vision outlooker ,也就是VOLO。
与专注于全局依赖粗略建模的自注意力不同,outlook注意力可以有效地将更精细级别的特征和上下文编码为token。
因此,VOLO采用两阶段架构设计,同时考虑了更具细粒度的token表示编码和全局信息聚合。
第一阶段由一堆Outlookers组成,用于生成精细级别的token表示。
第二阶段部署一系列transformer blocks来聚合全局信息。
在每个阶段的开始,使用一个图像块嵌入模块(patch embedding module)将图像输入映射到期望形状的token表示。
下面就着重说一下这里面的核心:Outlooker。
其组成包括:用于空间信息编码的outlook注意力层,以及用于通道间信息交互的多层感知器(MLP)。
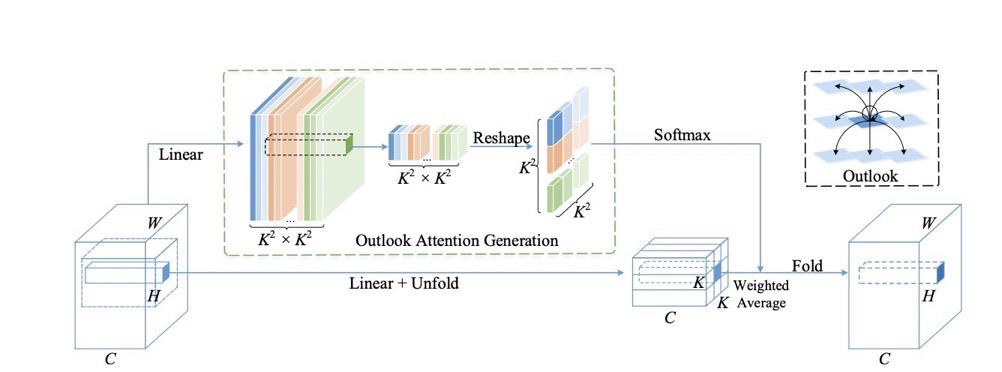
其中,通过reshape操作(绿框),可以从具有线性层的中心token简单生成大小为K×K的局部窗口的Outlook注意力矩阵。
由于注意力权值是从中心token生成并作用于邻居token及其本身(如黑框),因此研究人员将这些操作命名为outlook注意力。

具体来说,假如给定一个大小为224×224的输入图像。
在使用自注意力构建粗略级(如14×14)的全局依赖之前,VOLO将图像标记成较小尺寸(如8× 8)的patches。并使用多个Outlooker在精细级别上(如28×28)对token表示进行编码。
这样,最后获得的token表示更具有代表性,从而可显著提高图像分类模型的性能。
这个模型兼具卷积和自注意力的优点,总的来说:
1、outlook注意力通过度量每对token表示之间的相似性来对空间信息进行编码,因此其特征学习效果比卷积更具有参数效率;
2、outlook注意力采用滑动窗口方式,在精细级上实现了对token表示进行局部编码,并在一定程度上保留了视觉任务的关键位置信息;
3、生成注意力权值的方法简单有效。与依赖于query-key矩阵乘法的自注意力不同,outlook的权值仅靠一个简单的reshape操作产生,节省了计算量。
实验结果
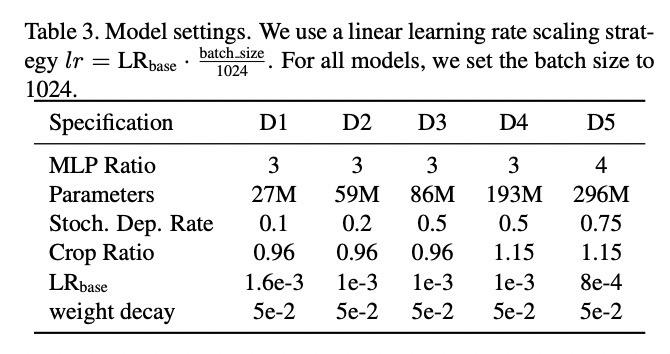
研究人员配置了五个不同大小的VOLO变体,各参数如下:
如下表所示,在不同的模型尺寸水平上,他们提出的VOLO都取得了比当前SOTA模型更佳的性能。
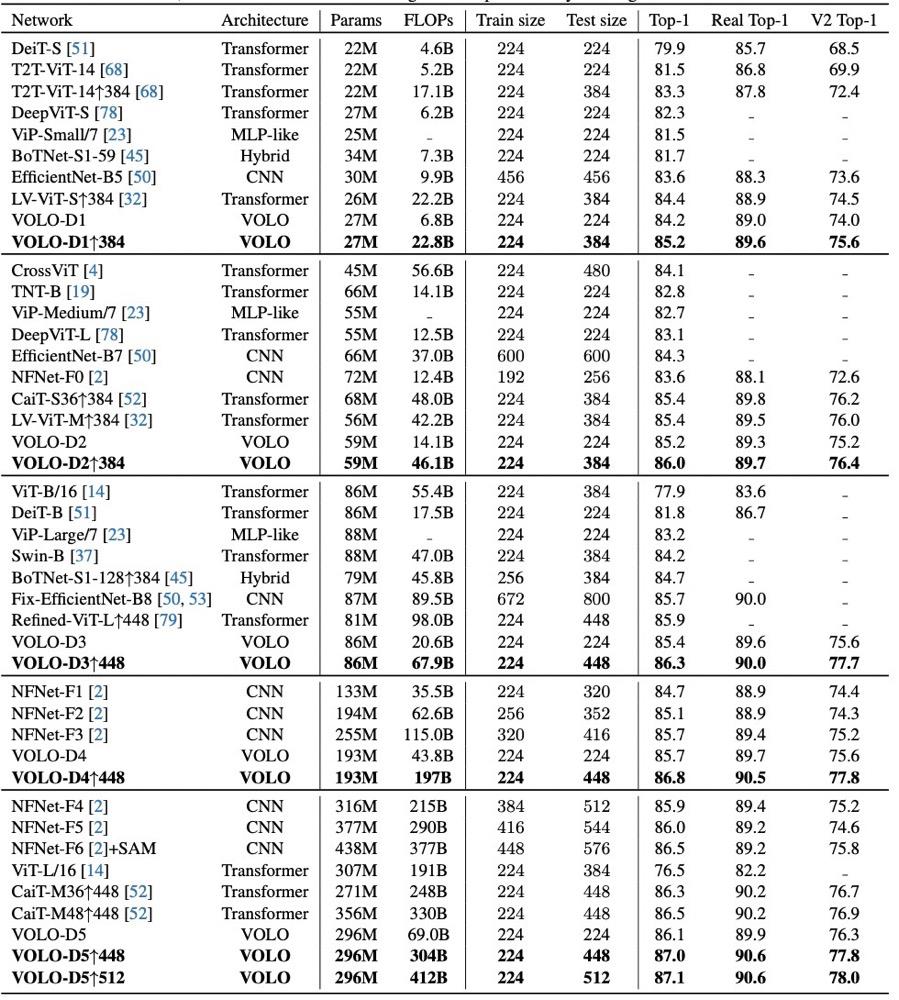
例如,只有26.6万参数量的VOLO-D1,在输入图片分辨率为224时,它在ImageNet上已经可以达到84.2%的top-1精度。将分辨率微调到384后,性能进一步提高到85.2%,一举pk掉所有具有相同训练参数的模型。
而当模型规模增加到296万时,VOLO就在ImageNet上达到了87.1%的top-1精度,这在没有额外训练数据的情况下创造了新的记录!
研究人员还将Outlooker与局部自注意力(local self-attention)和空间卷积进行了比较。
结果表明,在训练方法和架构相同的情况下,Outlooker都优于局部自注意力和空间卷积。

研究人员还观察到,在以LV-ViT-S为基准模型时,局部自注意力和空间卷积也可以提高性能,这表明对精细级的token表示进行编码对图像识别模型的性能提升是有帮助的。
不仅如此,预训练好的VOLO模型还可以很好地迁移到下游任务,如语义分割:它在Cityscapes数据集上获得了84.3%的mIoU。
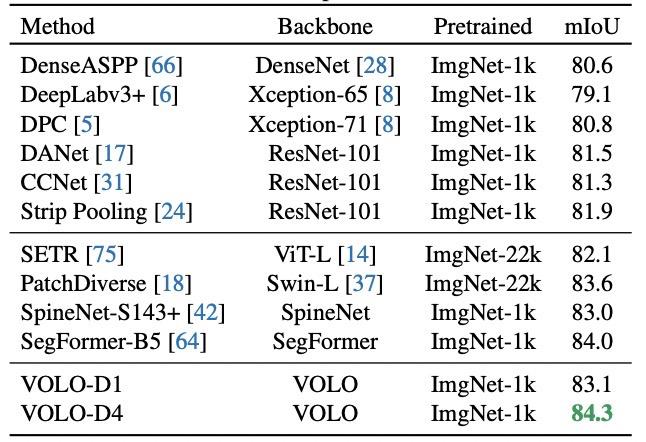
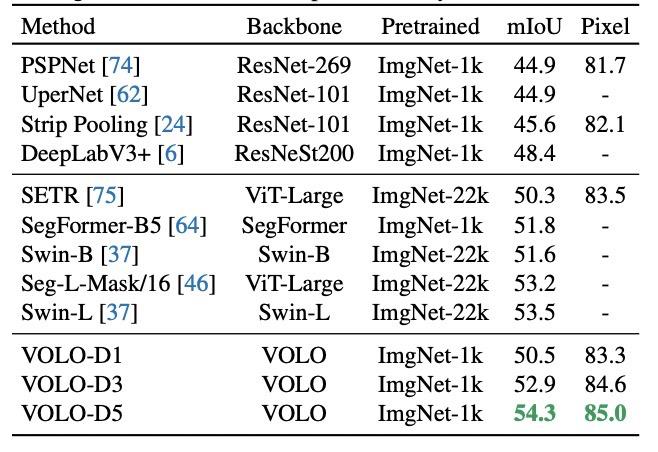
在ADE20K数据集上获得了54.3%的mIoU。
最后,消融实验发现:
增加模型尺寸有助于提升模型性能,例如VOLO-D1到VOLO-D2可以带来1%的性能提升;
更高分辨率的微调同样也可以带来约1%的性能提升。
作者介绍

本文的第一作者是袁粒,目前在新加坡国立大学(NUS)博士就读,本科毕业于中科大,曾提出改进ViT的模型:T2T-ViT。

二作为侯淇彬,南开大学博士毕业,在计算机领域顶级期刊及会议上发表论文9篇,其中一作5篇。现在是NUS的研究员。
其余作者信息如下:

蒋子航,NUS博士在读,师从冯佳时教授,来自中国浙江。

冯佳时,著名华人AI学者,现为NUS的ECE系助理教授。本科毕业于中国科学技术大学,硕士毕业于中国科学院自动化研究所,博士毕业于NUS。他的论文h指数为68。

颜水成,人称“水哥”,IEEE Fellow、IAPR Fellow。毕业于北京大学数学系,曾任360集团副总裁、依图科技CTO等职。
现在NUS领导机器学习与计算机视觉实验室,拥有该校终身教职,论文h指数为96。
更多研究细节请戳论文全文:https://arxiv.org/abs/2106.13112
GitHub链接:https://github.com/sail-sg/volo
以上是关于颜水成团队开源VOLO:无需额外数据,首次在ImageNet上达到87.1%的精度的主要内容,如果未能解决你的问题,请参考以下文章
颜水成发了个「简单到令人尴尬」的视觉模型,证明Transformer威力源自其整体架构...
重大里程碑!VOLO屠榜CV任务,无需额外数据,首个超越87%的模型