颜水成冯佳时团队发布首篇《深度长尾学习》综述!
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了颜水成冯佳时团队发布首篇《深度长尾学习》综述!相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :机器之心
长尾学习是推动神经网络模型落地的重要范式。在这篇综述中,来自新加坡国立大学和 SEA AI Lab 的学者们首次系统地阐述了深度长尾学习及其方法和应用,并提出了一个新的评价指标以验证现存长尾学习方法对类别不平衡问题的解决能力。
深度长尾学习是视觉识别任务中最具挑战性的问题之一,旨在从大量遵循长尾类别分布的图像中训练出性能良好的深度神经网络模型。近年来,学者们对该问题开展了大量研究,并取得了可喜进展。鉴于该领域的飞速发展,在这篇综述中,来自新加坡国立大学和 SEA AI Lab 的颜水成、冯佳时团队对深度长尾学习的最新进展进行了系统性的梳理和分类讨论,并设计了一个新的评价指标对现存方法进行实验分析,同时也对未来的重要研究方向进行了展望。

论文链接:https://arxiv.org/pdf/2110.04596.pdf
为什么要重视深度长尾学习?
近年来,深度学习已经成为人工智能领域中最重要的技术之一。因强大的数据特征表达能力,深度神经网络已经被成功应用到众多视觉识别任务中并取得了显著的突破,如图像分类,物体检测和语义分割等。深度神经网络的成功源于其大量的模型参数对任务模式的学习,而这一过程需要大量的标注数据进行模型训练。在传统视觉识别任务中,标注数据的类别分布往往受到人为调整而变得均衡,即不同类别的样本数量无明显差别。
而在实际应用中,自然采集的数据类别通常表现为长尾分布(如下图),即一小部分类别拥有大量的样本,而其余大部分类别只有较少的样本量。然而,这一类别不平衡问题往往使得深度神经网络的训练变得非常困难。如下图所示,在长尾数据下训练的模型容易偏向训练数据中的多数类,即多数类的特征空间往往大于少数类的特征空间,且分类决策边界会向少数类方向偏移以确保更好地分类多数类,这一现象往往导致深度模型在数据量有限的少数类上表现不佳。因此,直接使用经验风险最小化方法来训练深度模型无法处理具有长尾类别不平衡问题的实际应用,如人脸识别,物种分类,医学图像诊断,无人机检测等等。

为了解决这一长尾类别不平衡问题,深度长尾学习旨在从大量遵循长尾类分布的图像中训练出性能良好的深度模型。鉴于类别不平衡问题在现实任务中十分广泛,并且训练数据和测试数据的类别分布差异会极大限制神经网络的实际应用,这一研究课题具有重要的现实意义,是推动深度神经网络实现模型落地的重要范式。
尽管深度长尾学习领域发展迅速,应运而生的大量论文却容易导致学者和算法工程师们迷失在知识的海洋中。为了解决这一问题,该论文首次对深度长尾学习进行了系统性的综述,梳理出了一条深度长尾学习的清晰脉络,从而帮助业界学者和专家更好地理解深度长尾学习,并推动该领域的蓬勃发展。
该综述首先详细地介绍了深度长尾学习的任务设定、数据集、衡量指标、主流网络结构、知名竞赛、以及与其他任务间的关系。随后,该文将现存方法进行分类梳理。如下图所示,现存方法被分为三个主要的类别(即类别重平衡、信息增强和网络模块改进),同时能够被进一步细分为九个子类别。基于该分类法,该论文对现存方法进行了详细的综述和讨论。

其中经典的方法如下表所示。同时作者还整理了一个深度长尾学习论文列表:https://github.com/Vanint/Awesome-LongTailed-Learning

此外,该综述还提出了一个新的经验衡量指标(相对精度),并以此对现存最优的长尾学习算法进行了实验,旨在更好地对比现存方法对类别不平衡问题的处理能力。最后,该文探讨了深度长尾学习的主要应用场景和重要的未来研究方向。
深度长尾学习的主要方法类别
类别重平衡:类别重平衡是长尾学习的主流方法之一,旨在对不同类别的数据量差异进行再平衡。该类方法可细分为类别重采样,类别代价敏感学习和对数几率调整。相较于其他的长尾学习范式,类别重平衡方法相对简单,却能获得相似甚至更好的性能。同时,部分的类别重平衡方法(尤其是代价敏感学习)对于解决长尾类别不平衡问题具有理论分析保证。这些优点使得该类方法成为解决实际长尾问题的重要工具。然而,该类方法的缺点在于,少数类的性能提升往往是以多数类的性能牺牲作为代价。尽管总体性能得到了提升,但该类方法无法本质地解决长尾问题中缺少数据信息的问题,尤其是在少数类上。
信息增强:基于信息增强的方法旨在引入额外信息来增强模型训练,从而提升模型在长尾数据上的学习性能。该类方法可细分为迁移学习和数据增强。因为引入了额外的信息,基于信息增强的方法能够在不损失多数类性能的情况下提升少数类性能。考虑到缺乏足够的少数类样本是长尾学习的一个关键问题,该类方法值得进一步探索。例如,数据增强是一项相对基础的技术,可以同时被应用到多种长尾学习任务中,这使得它非常具有实用性。但是,简单地应用现存经典的、不考虑类别差异的数据增强技术到长尾学习任务中是有局限的:即使长尾学习的整体性能获得提升,但因为多数类的数据量更多,导致多数类的数据增强也更多,从而进一步加剧了类别不平衡问题。因此,如何设计更好的针对深度长尾学习的数据增强方法是一个值得探索的问题。
网络模块提升:除了类别重平衡和信息增强方法以外,学者们也探索了如何在长尾学习中有针对性地提升网络模块,包括:(1)表示学习提升特征特征提取器,(2)分类器设计改进模型分类器,(3)解耦训练促进特征提取器和分类器的训练,(4)集成学习提升整体的网络结构。其中,表征学习和分类器设计是深度长尾学习的基本问题,值得进一步探索。解耦训练在最近的研究中越发受到关注;在该方案中,第二阶段的类平衡分类器微调能带来显着的性能提升,并不会引入太多额外的计算成本。对该类方法的一种批评是,累积的训练阶段会使解耦训练不太实用,难以直接与其他长尾问题中(如目标检测和实例分割)的经典方法相结合。尽管如此,解耦训练的想法在概念上很简单,因此可以很容易地在这些问题中用来设计新方法。最后,与其他类型的长尾学习方法相比,基于集成学习的方法通常在头类和尾类上都能获得更好的性能。这类方法的一个问题是,多个专家的使用会导致模型的计算成本增加。但是,该问题可以通过使用共享特征提取器来缓解,并且以效率为导向的专家分配策略和知识蒸馏策略也可以有效降低计算代价。
深度长尾学习的新评价指标
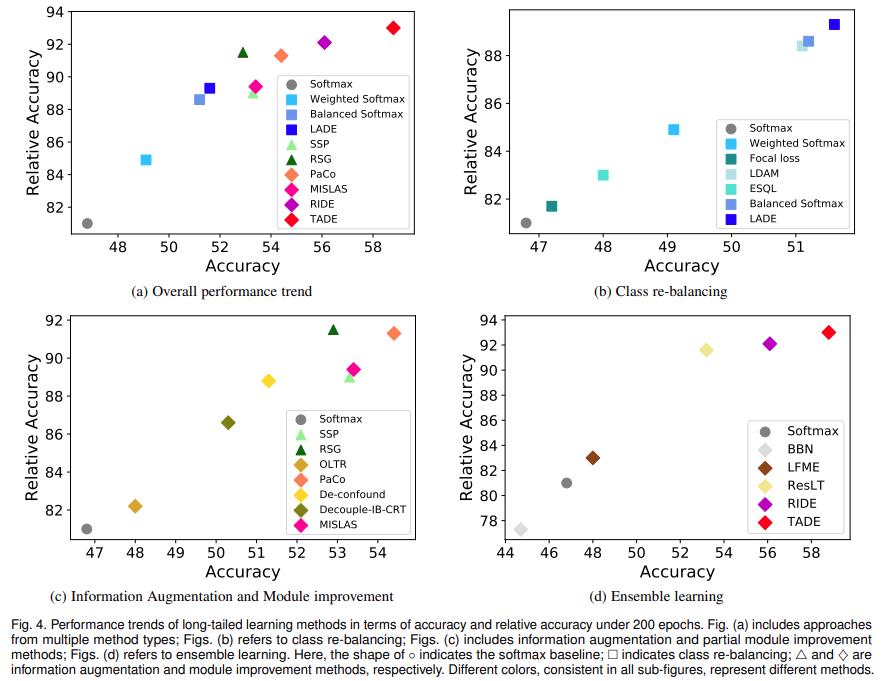
深度长尾学习旨在处理长尾类别不平衡问题以获得更好的模型性能,通常以测试集精度为衡量指标来评价长尾学习方法的性能及其处理类别不平衡问题的能力。然而,因为模型精度同时也受除类别不平衡问题之外的其他因素影响,所以测试集精度指标并不能准确反映不同方法在处理类别不平衡问题时的相对优势。例如,基于数据增强的长尾学习方法也会提升在类别平衡数据集上所训得到模型的测试精度;在这种情况下很难判断测试精度的提升是来自于类别不平衡问题的缓解还是来自更多数据信息的引入。这也启发大家重新思考:到底怎样才算真正解决长尾学习?为此,该综述提出了一个新的相对精度指标,用于消除非类别不平衡因素的影响,从而更好地衡量长尾学习算法对于类别不平衡问题的实际解决能力。基于这一指标,该综述开展实验对现存长尾学习算法进行了深入分析。
深度长尾学习的未来方向
尽管深度长尾学习已经取得长足的进展,但依然存在许多开放性的问题以待进一步研究。
新方法探索:不依赖于标签统计频率的类别重平衡;基于无标签数据的迁移学习和半监督学习;适用于多个长尾学习任务的数据增强;提升全部类别性能的集成学习。
新任务设定探索:测试集类别分布未知的长尾学习;存在开放类别的长尾学习;联邦长尾学习;类增量长尾学习;多域长尾学习;鲁棒长尾学习;长尾回归;长尾视频学习。
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于颜水成冯佳时团队发布首篇《深度长尾学习》综述!的主要内容,如果未能解决你的问题,请参考以下文章
颜水成团队开源VOLO:首次在ImageNet上达到87.1%的精度
颜水成团队开源VOLO:无需额外数据,首次在ImageNet上达到87.1%的精度