重大里程碑!VOLO屠榜CV任务,无需额外数据,首个超越87%的模型
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重大里程碑!VOLO屠榜CV任务,无需额外数据,首个超越87%的模型相关的知识,希望对你有一定的参考价值。
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
大家好,我是Charmve,每晚七点不见不散! >>公众号内回复“加群”,加入迈微CV技术交流群,走在计算机视觉的最前沿
近来,Transformer在CV领域遍地开花,取得了非常好的性能,指标屡创新高。但Transformer的性能距离最佳的CNN仍存在差距,不由产生出一种Transformer不过如此的感觉。
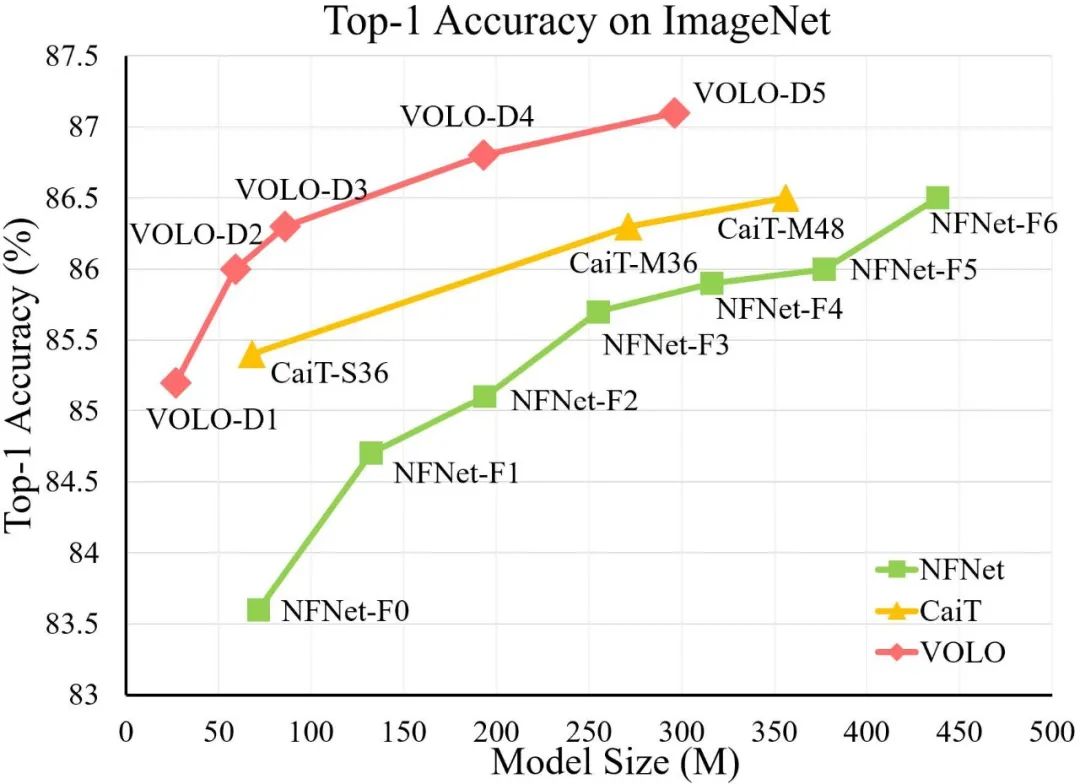
可是,就在今天,Transformer领域的新秀VOLO打破了Transformer无法打败最优CNN的宿命,成为了ImageNet数据上首个无需额外数据达到87.1%的模型;与此同时,VOLO在下游语义分割任上也创新了新记录,比如Cityscapes数据上的84.3%,ADE20K数据上的54.3%。

论文 https://arxiv.org/abs/2106.13112
源码 https://github.com/sail-sg/volo
1摘要
视觉识别任务已被CNN主宰多年。基于自注意力的ViT在ImageNet分类方面表现出了极大的潜力,在没有额外数据前提下,Transformer的性能与最先进的CNN模型仍具有差距。
在这项工作中,我们的目标是缩小这两者之间的性能差距,并且证明了基于注意力的模型确实能够比CNN表现更好。与此同时,我们发现限制ViTs在ImageNet分类中的性能的主要因素是其在将细粒度级别的特征编码乘Token表示过程中比较低效,为了解决这个问题,我们引入了一种新的outlook注意力,并提出了一个简单而通用的架构,称为Vision outlooker (VOLO)。outlook注意力主要将fine-level级别的特征和上下文信息更高效地编码到token表示中,这些token对识别性能至关重要,但往往被自注意力所忽视。
实验表明,在不使用任何额外训练数据的情况下,VOLO在ImageNet-1K分类任务上达到了87.1%的top-1准确率,这是第一个超过87%的模型。此外,预训练好的VOLO模型还可以很好地迁移到下游任务,如语义分割。我们在Cityscapes验证集上获得了84.3% mIoU,在ADE20K验证集上获得了54.3%的mIoU,均创下了最新记录。
2方法
VOLO可以看作是一个具有两个独立阶段的结构。第一阶段多个用于生成细粒度token表示的Outlookers。第二阶段我们部署一系列Transformer block来聚合全局信息。在每个阶段的最开始,使用一个patch embedding模块将输入映射到期望形状大小的的token表示中。
2.1 Outlooker
outlook包括用于空间信息编码的outlook注意力层和用于通道间信息交互的多层感知器(MLP)。给定输入 token表示序列 , outlooker可以写成如下:
2.2 Outlook attention

如上图所示,Outlook attention简单,高效,易于实现。它的主要创新点就是:
每个空间位置上的特征足够全面,可以聚集其邻近特征然后生成局部注意力权值;
稠密的局部空间聚合可以高效的编码细粒度信息。
对于每个空间位置 , outlook注意力计算以 为中心的大小为 的局部窗口内所有邻近结点的相似度。不同于自我注意力需要一个Query-Key矩阵乘法来计算注意力,outlook直接通过一个简单的reshape操作来简化这个过程。具体来说,输入 每个 token使用两个线性层
进行映射得到outlook权重 , value表示 ,然后我们用 来表示在以