都2021年了,不会还有人连深度学习还不了解吧-- Padding篇
Posted 奋斗丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了都2021年了,不会还有人连深度学习还不了解吧-- Padding篇相关的知识,希望对你有一定的参考价值。
导读
本篇文章主要介绍CNN中常见的填充方式Padding,Padding在CNN中用的很多,是CNN必不可少的组成部分,使用Padding的目的主要是为了调整输出的大小,是必须搞清楚的知识点。如果你想继续了解深度学习,那么请看下去吧!
目前深度学习系列已经更新了6篇文章,分别是激活函数篇、卷积篇、损失函数篇、下采样篇、评估指标篇,另有1篇保姆级入门教程,1篇总结性文章CNN中十大令人拍案叫绝的操作,想要入门深度学习的同学不容错过!

一、Padding介绍
1.1 什么是Padding
在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0、1等),这称为填充(padding),是卷积运算中经常会用到的处理。例如,向下列tensor中使用幅度为1像素为0的填充。
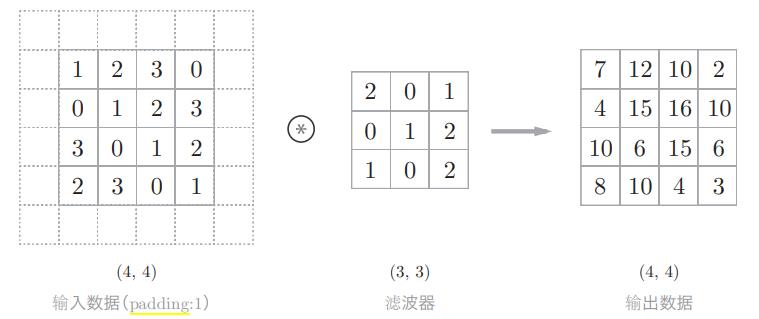
虚线部分表示是填充的数据,这里省略了填充的内容0。
1.2 为什么要使用Padding
- 1.使用填充主要是为了调整输出的大小。比如,对大小为(4, 4)的输入数据应用(3, 3)的滤波器时,输出大小变为(2, 2),相当于输出大小比输入大小缩小了 2个元素。这在反复进行多次卷积运算的深度网络中会成为问题。为什么呢?因为如果每次进行卷积运算都会缩小空间,那么在某个时刻输出大小就有可能变为 1,导致无法再应用卷积运算。为了避免出现这样的情况,就要使用填充。在刚才的例子中,将填充的幅度设为 1,那么相对于输入大小(4, 4),输出大小也保持为原来的(4, 4)。因此,卷积运算就可以在保持空间大小不变的情况下将数据传给下一层。
- 2.越是边缘的像素点,对于输出的影响越小,因为卷积运算在移动的时候到边缘就结束了。中间的像素点有可能会参与多次计算,但是边缘像素点可能只参与一次。所以结果可能会丢失边缘信息。使用Padding可以在一定程度上保留边界信息。
二、常见的Padding方式
这里我会以图示的方式尽量将每种填充方式都阐述清楚,CNN中用到的填充方式无非就是下面的四种,最常用的是填0的Padding,另镜面Padding在Unet论文中使用过,感兴趣的同学可以自行下载去阅读!
Unet:Unet论文链接

2.1 填0Padding
原tensor:
[[-0.1678, -0.4418, 1.9466],
[ 0.9604, -0.4219, -0.5241],
[-0.9162, -0.5436, -0.6446]]
经过Padding(幅度为2,填充为0)后:
[[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, -0.1678, -0.4418, 1.9466, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.9604, -0.4219, -0.5241, 0.0000, 0.0000],
[ 0.0000, 0.0000, -0.9162, -0.5436, -0.6446, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]
2.2 镜面Padding
原始tensor:
[[0., 1., 2.],
[3., 4., 5.],
[6., 7., 8.]]
经过镜面Padding之后:
[[8., 7., 6., 7., 8., 7., 6.],
[5., 4., 3., 4., 5., 4., 3.],
[2., 1., 0., 1., 2., 1., 0.],
[5., 4., 3., 4., 5., 4., 3.],
[8., 7., 6., 7., 8., 7., 6.],
[5., 4., 3., 4., 5., 4., 3.],
[2., 1., 0., 1., 2., 1., 0.]]
通俗解释一下镜面Padding是如何实现的,其实原理也很简单,跟初中物理学过的镜面反射原理是一样的,分别以原始tensor的四条边为镜面,然后进行反射,即可得到镜面Padding之后的tensor了。
2.3 填连续值Padding
原始tensor:
[[ 1.6585, 0.4320],
[-0.8701, -0.4649]]
经过Padding(幅度为2,填充为3.5)之后,变为下列所示的tensor:
[[ 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000],
[ 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000],
[ 3.5000, 3.5000, 1.6585, 0.4320, 3.5000, 3.5000],
[ 3.5000, 3.5000, -0.8701, -0.4649, 3.5000, 3.5000],
[ 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000],
[ 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000]]
2.4 使用输入tensor的边缘Padding
原始tensor:
[[0., 1., 2.],
[3., 4., 5.],
[6., 7., 8.]]
经过Padding(幅度为2)后的tensor:
[[0., 0., 0., 1., 2., 2., 2.],
[0., 0., 0., 1., 2., 2., 2.],
[0., 0., 0., 1., 2., 2., 2.],
[3., 3., 3., 4., 5., 5., 5.],
[6., 6., 6., 7., 8., 8., 8.],
[6., 6., 6., 7., 8., 8., 8.],
[6., 6., 6., 7., 8., 8., 8.]]
文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个专注于医学图像处理领域前沿科技的公众号。坚持以实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。更有上百部深度学习入门资料免费等你来拿,只有实践才能成长的更快,关注我们,一起学习进步~
计划
深度学习保姆级入门教程 – 论文+代码+常用工具
1个字,绝! – CNN中十大令人拍案叫绝的操作
都2021年了,不会还有人连深度学习还不了解吧?(一)-- 激活函数篇
都2021年了,不会还有人连深度学习还不了解吧?(二)-- 卷积篇
都2021年了,不会还有人连深度学习还不了解吧?(三)-- 损失函数篇
都2021年了,不会还有人连深度学习还不了解吧?(四)-- 上采样篇
都2021年了,不会还有人连深度学习还不了解吧?(五)-- 下采样篇
都2021年了,不会还有人连深度学习还不了解吧?(六)-- Padding篇
都2021年了,不会还有人连深度学习还不了解吧?(七)-- 评估指标篇
都2021年了,不会还有人连深度学习还不了解吧?(八)-- 优化算法篇
都2021年了,不会还有人连深度学习还不了解吧?(九)-- 注意力机制篇
都2021年了,不会还有人连深度学习还不了解吧?(十)-- 数据归一化篇
觉得写的不错的话,欢迎点赞+评论+收藏,欢迎关注我的微信公众号,这对我帮助真的很大很大很大!

以上是关于都2021年了,不会还有人连深度学习还不了解吧-- Padding篇的主要内容,如果未能解决你的问题,请参考以下文章
都2021年了,不会还有人连深度学习还不了解吧-- Padding篇
都2021年了,不会还有人连深度学习还不了解吧?-- 损失函数篇
都2021年了,不会还有人连深度学习还不了解吧-- 优化算法篇
都2021年了,不会还有人连深度学习还不了解吧-- 优化算法篇