开源大数据:JindoFS 大数据计算存储分离
Posted ejinxian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源大数据:JindoFS 大数据计算存储分离相关的知识,希望对你有一定的参考价值。
EMR Jindo 是阿里云基于 Apache Spark / Apache Hadoop 在云上定制的分布式计算和存储引擎
EMR Jindo 有计算和存储两大部分,存储的部分叫 JindoFS。JindoFS 是阿里云针对云上存储定制的自研大数据存储服务,完全兼容 Hadoop 文件系统接口,给客户带来更加灵活、高效的计算存储方案,目前已验证支持阿里云 EMR 中所有的计算服务和引擎:Spark、Flink、Hive、MapReduce、Presto、Impala 等。Jindo FS 有两种使用模式,块存储模式和缓存模式。下面我们来分析下,JindoFS 是如何来解决大数据上的存储问题的
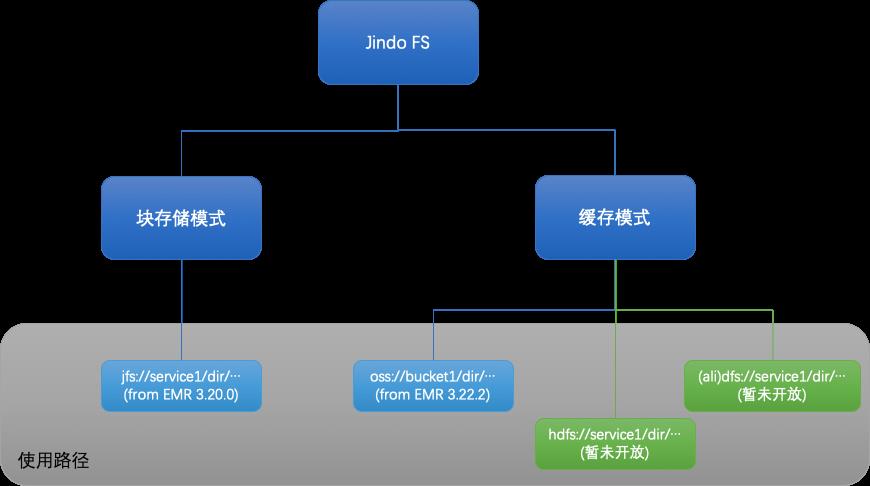
JindoFS是基于阿里云对象存储OSS,为开源大数据生态构建的Hadoop文件系统(HCFS)。
JindoFS提供兼容对象存储的纯客户端模式(SDK)和缓存模式(Cache),以支持与优化Hadoop和Spark生态大数据计算对OSS的访问;提供块存储模式(Block),以充分利用OSS的海量存储能力和优化文件系统元数据的操作。
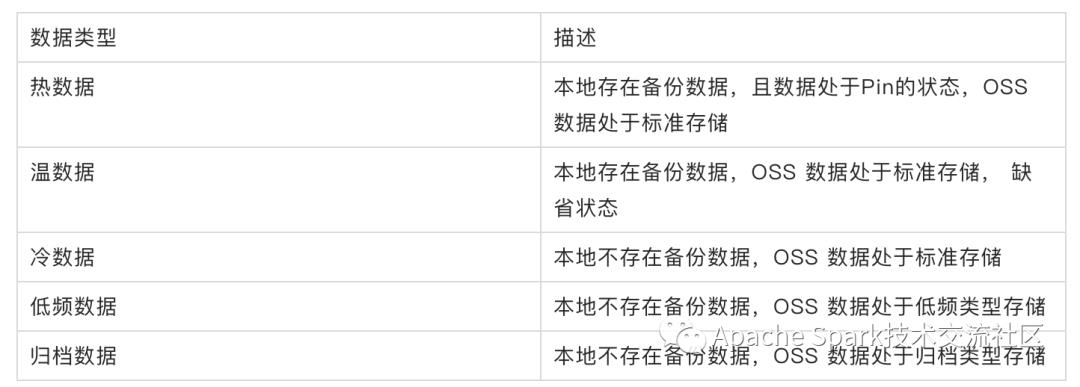
JindoFS 内部可以将数据分为以下集中,热数据,温数据,冷数据,低频数据,归档数据
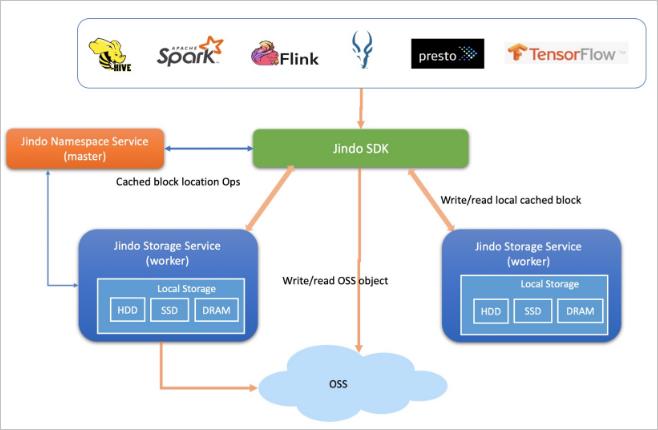
JindoFS纯客户端模式(SDK)
JindoFS纯客户端模式为Hive和Spark等计算框架提供了访问阿里云OSS及其各种操作的优化,类似Hadoop社区的OSS FileSystem或S3A FileSystem。此模式不改变文件或对象在OSS上的组织方式,文件还是保存在OSS上,JindoFS只是提供面向Hadoop生态的客户端连接、扩展、适配和优化访问。您可以使用此模式,上传JindoFS SDK的JAR包至组件的classpath目录,简单易用,无需部署分布式服务

参考
JindoFS介绍和使用
以上是关于开源大数据:JindoFS 大数据计算存储分离的主要内容,如果未能解决你的问题,请参考以下文章