在大数量级的数据存储上,比较靠谱的分布式文件存储都有哪些?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在大数量级的数据存储上,比较靠谱的分布式文件存储都有哪些?相关的知识,希望对你有一定的参考价值。
在大数量级的数据存储上,比较靠谱的分布式文件存储有哪些?
Ceph,GFS,HDFS。一、 Ceph
Ceph最早起源于Sage就读博士期间的工作、成果于2004年发表,并随后贡献给开源社区。经过多年的发展之后,已得到众多云计算和存储厂商的支持,成为应用最广泛的开源分布式存储平台。
二、 GFS
GFS是google的分布式文件存储系统,是专为存储海量搜索数据而设计的,2003年提出,是闭源的分布式文件系统。适用于大量的顺序读取和顺序追加,如大文件的读写。注重大文件的持续稳定带宽,而不是单次读写的延迟。
三、 HDFS
HDFS(Hadoop Distributed File System),是一个适合运行在通用硬件(commodity hardware)上的分布式文件系统,是Hadoop的核心子项目,是基于流数据模式访问和处理超大文件的需求而开发的。该系统仿效了谷歌文件系统(GFS),是GFS的一个简化和开源版本。【感兴趣的话点击此处,了解一下】
小编建议可以到亿万克官网了解一下,亿万克将持续走在创新第一线,不断为客户提供更加优质服务,为国家信息安全和新型数据中心建设保驾护航,助力国家碳中和碳达峰步入新篇章。 参考技术A 一、 Ceph
Ceph最早起源于Sage就读博士期间的工作、成果于2004年发表,并随后贡献给开源社区。经过多年的发展之后,已得到众多云计算和存储厂商的支持,成为应用最广泛的开源分布式存储平台。
二、 GFS
GFS是google的分布式文件存储系统,是专为存储海量搜索数据而设计的,2003年提出,是闭源的分布式文件系统。适用于大量的顺序读取和顺序追加,如大文件的读写。注重大文件的持续稳定带宽,而不是单次读写的延迟。
三、 HDFS
HDFS(Hadoop Distributed File System),是一个适合运行在通用硬件(commodity hardware)上的分布式文件系统,是Hadoop的核心子项目,是基于流数据模式访问和处理超大文件的需求而开发的。该系统仿效了谷歌文件系统(GFS),是GFS的一个简化和开源版本。
有礼
现在入学礼包等你来领
- 官方电话在线客服官方服务
- 官方网站就业保障热门专业入学指南在线课堂领取礼包
大数据实战项目必备技术技能:分布式文件系统HDFS
导读: HDFS 是Hadoop Distibuted File System 的缩写,是一个高度容错的分布式文件系统,属于Apache的一个子项目,也算是google GFS的开源实现。现Hadoop作用于国内外各个领域大小不同公司的具体线上业务,适合存储海量的数据(TB及PB),底层使用的就是HDFS作为其存储。HDFS可以利用廉价的普通服务器作为其存储,组件一个大规模存储集群,为各类计算提供数据访问的基础。
1、HDFS产生背景
随着数据量越来越大,在一个操作系统管辖的范围内存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
2 、HDFS概念
HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的设计适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
3、HDFS 特点
1、基于“一次写入,多次读取“模型,支持高吞吐量的访问,不适合文件反复修改场景;
2、开源;
3、自动将处理逻辑与存储数据位置就近分配原则,提高数据处理的效率;
4、 HDFS的专业术语概念
1、数据块
HDFS默认最基本的存储单位是64MB的数据块,大小通过配置可调;对于存储空间未达到数据块大小的文件,这个文件也不会占用整个数据块的存储空间;
2、元数据节点(namenode)
元数据节点算是HDFS中非常重要的一个概念,管理文件系统的命令空间,将所有文件和文件夹的元数据保存在文件系统树种,通过在硬盘保存避免丢失,采用文件命名空间镜像(fs image)及修改日志(edit log)方式保存;
3、数据节点(DataNode)
数据节点即是真正数据存储的地方。加
4、从元数据节点(secondary namenode)
字面看起来像是元数据节点的备用节点,但实际不然,它和元数据节点是负责不同的事情,主要负责周期性将命名空间镜像与修改日志文件合并,避免文件过大,合并过后文件会同步至元数据节点,同时本地保存一份,以在故障时恢复;
5、HDFS优缺点
1 优点
1)高容错性
(1)数据自动保存多个副本。它通过增加副本的形式,提高容错性;
(2)某一个副本丢失以后,它可以自动恢复。
2)适合大数据处理
(1)数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据;
(2)文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3)流式数据访问,它能保证数据的一致性。
4)可构建在廉价机器上,通过多副本机制,提高可靠性。
2 缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储。
(1)存储大量小文件的话,它会占用NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
(2)小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3)并发写入、文件随机修改。
(1)一个文件只能有一个写,不允许多个线程同时写;
(2)仅支持数据append(追加),不支持文件的随机修改。
6、HDFS组成架构
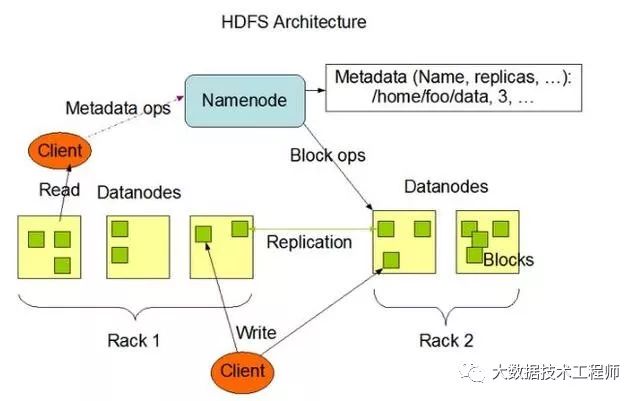
HDFS的架构图
这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。下面我们分别介绍这四个组成部分。
1)Client:就是客户端。
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行存储;
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,比如启动或者关闭HDFS;
(5)Client可以通过一些命令来访问HDFS;
2)NameNode:就是Master,它是一个主管、管理者。
(1)管理HDFS的名称空间;
(2)管理数据块(Block)映射信息;
(3)配置副本策略;
(4)处理客户端读写请求。
3) DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作。
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
4) Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量;
(2)定期合并Fsimage和Edits,并推送给NameNode;
(3)在紧急情况下,可辅助恢复NameNode。
5 、HDFS文件块大小
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M。
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率。
如果寻址时间约为10ms,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。默认的块大小128MB。
块的大小:10ms*100*100M/s = 100M
7、书籍推荐:
图书简介:
《高可用性的hdfs—hadoop分布式文件系统深度实践》专注于hadoop分布式文件系统(hdfs)的主流ha解决方案,内容包括:hdfs元数据解析、hadoop元数据备份方案、hadoopbackup node方案、avatarnode解决方案以及最新的ha解决方案cloudrea ha namenode等。其中有关backupnode方案及avatarnode方案的内容是本书重点,尤其是对avatarnode方案从运行机制到异常处理方案的步骤进行了详尽介绍,同时还总结了各种异常情况下avatarnode的各种处理方案。
《高可用性的hdfs—hadoop分布式文件系统深度实践》从代码入手并结合情景分析、案例解说对hdfs的元数据以及主流的hdfsha解决方案的运行机制进行了深入剖析,力求使读者在解决问题时做到心中有数,不仅知其然还知其所以然。
图书简介:
《Hadoop技术内幕:深入解析Hadoop Common和HDFS架构设计与实现原理》内容简介:“Hadoop技术内幕”共两册,分别从源代码的角度对“Common+HDFS”和MapReduce的架构设计与实现原理进行了极为详细的分析。《Hadoop技术内幕:深入解析Hadoop Common和HDFS架构设计与实现原理》由腾讯数据平台的资深Hadoop专家、X-RIME的作者亲自执笔,对Common和HDFS的源代码进行了分析,旨在为Hadoop的优化、定制和扩展提供原理性的指导。除此之外,《Hadoop技术内幕:深入解析Hadoop Common和HDFS架构设计与实现原理》还从源代码实现中对分布式技术的精髓、分布式系统设计的优秀思想和方法,以及Java语言的编码技巧、编程规范和对设计模式的精妙运用进行了总结和分析,对提高读者的分布式技术能力和Java编程能力都非常有帮助。《Hadoop技术内幕:深入解析Hadoop Common和HDFS架构设计与实现原理》适合Hadoop的二次开发人员、应用开发工程师、运维工程师阅读。, 全书共9章,分三部分,第一部分第 1章)主要介绍了Hadoop源代码的获取和源代码阅读环境的搭建;第二部分(第2~5章)对Hadoop公共工具Common的架构设计和实现原理进行了深入分析,包含Hadoop的配置信息处理、面向海量数据处理的序列化和压缩机制、Hadoop的远程过程调用,以及满足Hadoop上各类应用访问数据的Hadoop抽象文件系统和部分具体文件系统等内容;第三部分(第6~9章)对Hadoop的分布式文件系统HDFS的架构设计和实现原理进行了详细的分析,这部分内容采用了总分总的结构,第6章对HDFS的各个实体和实体间接口进行了分析;第7章和第8章分别详细地研究了数据节点和名字节点的实现原理,并通过第9章对客户端的解析,回顾了HDFS各节点间的配合,完整地介绍了一个大规模数据存储系统的实现。
今天就分享到这里,希望对大家有所帮助,希望大家多多关注,有什么不对的地方希望大家留言指正,最后祝大家工作之余有一个好的心情,健康的身体。
以上是关于在大数量级的数据存储上,比较靠谱的分布式文件存储都有哪些?的主要内容,如果未能解决你的问题,请参考以下文章