论文泛读141使用上下文标记表示的临床命名实体识别
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读141使用上下文标记表示的临床命名实体识别相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Clinical Named Entity Recognition using Contextualized Token Representations》
一、摘要
临床命名实体识别 (CNER) 任务旨在将临床术语定位并分类为预定义的类别,例如诊断程序、疾病障碍、严重程度、药物、药物剂量和症状。CNER 促进了药物副作用的研究,包括新现象的识别和以人为中心的信息提取。现有的提取感兴趣实体的方法侧重于使用静态词嵌入来表示每个词。然而,一个词可以有不同的解释,这取决于句子的上下文。显然,静态词嵌入不足以整合一个词的不同解释。为了克服这一挑战,引入了上下文化词嵌入技术,以根据上下文更好地捕获每个词的语义。其中两个语言模型 ELMo 和 Flair 已广泛用于自然语言处理领域,以在领域通用文档上生成上下文词嵌入。然而,这些嵌入通常过于笼统,无法捕捉特定领域的词汇之间的接近程度。为了促进使用临床病例报告 (CCR) 的各种下游应用程序,我们使用来自以下方面的临床相关语料库预训练了两个深度语境化语言模型,即语言模型中的临床嵌入 (C-ELMo) 和临床语境字符串嵌入 (C-Flair)。医学中心。
二、结论
在我们的研究中,我们表明,对于临床NER而言,背景嵌入相对于非背景嵌入显示出相当大的优势。此外,与现成的语料库相比,使用特定领域的语料库对语言模型进行预训练会在下游CNER任务中产生更好的性能。我们还对C-ELMo和C-Flair进行了相对公平的比较。
- 据我们所知,我们是第一个使用深度语境化表征构建解决临床自然语言处理任务的框架的人。我们预先培训了两种语境化的语言模型,CELMo和C-Flair供公众使用。
- 我们在三个CNER基准数据集(MACCROBAT2018、i2b2-2010和NCBI病)上评估了我们的模型,分别取得了10.31%、7.50%和6.94%的显著改善。
- 我们表明,与领域通用嵌入相比,使用轻领域特定语料库预训练语言模型可以在下游CNER应用中获得更好的性能。
三、model
- ELMo
- CNER Model
- BiLSTM-CRF
字符和单词语言模型:
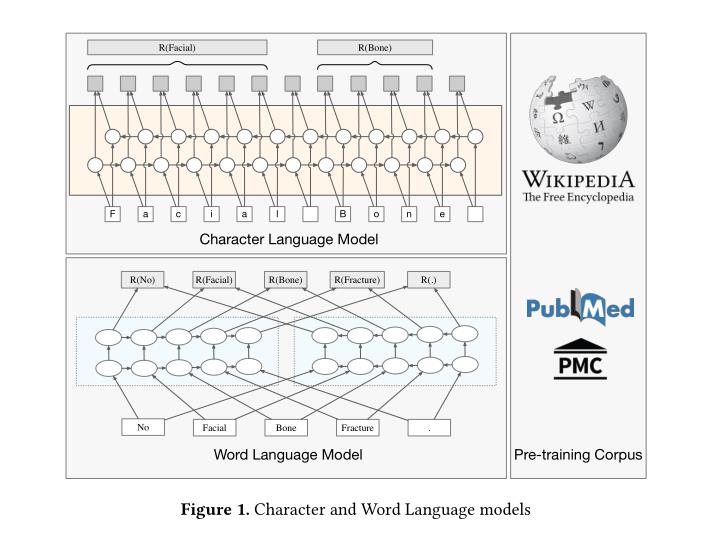
以上是关于论文泛读141使用上下文标记表示的临床命名实体识别的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读164MECT:基于多元数据嵌入的中文命名实体识别交叉变换器
论文泛读193LICHEE:使用多粒度标记化改进语言模型预训练
论文泛读193LICHEE:使用多粒度标记化改进语言模型预训练