论文泛读164MECT:基于多元数据嵌入的中文命名实体识别交叉变换器
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读164MECT:基于多元数据嵌入的中文命名实体识别交叉变换器相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《MECT: Multi-Metadata Embedding based Cross-Transformer for Chinese Named Entity Recognition》
一、摘要
最近,词增强在中文命名实体识别(NER)中变得非常流行,减少了分割错误并增加了中文词的语义和边界信息。然而,这些方法在整合词汇信息后往往会忽略汉字结构的信息。汉字自古由象形文字演变而来,其结构往往反映了更多的文字信息。本文提出了一种新的基于多元数据嵌入的交叉变换器(MECT),通过融合汉字的结构信息来提高中文 NER 的性能。具体来说,我们在双流 Transformer 中使用多元数据嵌入将汉字特征与部首级嵌入相结合。借助汉字的结构特征,MECT可以更好地为NER捕捉汉字的语义信息。在几个著名的基准数据集上获得的实验结果证明了所提出的 MECT 方法的优点和优越性。代码:github。
二、结论
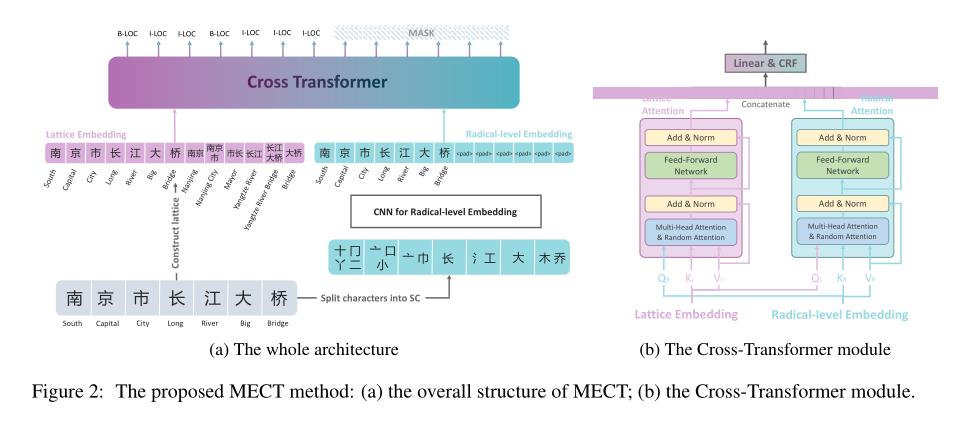
本文提出了一种适用于Chinese NER的新型双流网络,即MECT。该方法使用多元数据嵌入,通过交叉变换网络融合部首、字符和单词的信息。此外,随机注意力被用于进一步提高性能。在四个基准上的实验结果表明,汉字部首信息可以有效提高Chinese NER的性能。
所提出的带有基流的MECT方法增加了模型的复杂性。未来,我们将考虑如何在双流或多流网络中以更高效的方式集成汉字的字符、单词和部首信息,以提高Chinese NER的性能,并将其扩展到其他自然语言处理任务中。
三、model
该方法的关键是利用汉字的部首信息来增强中文NER模型。所以我们重点研究了文献中主流的信息增强方法。汉语NER增强方法主要有两种,包括词汇信息融合和字形结构信息融合。
最大似然方法:
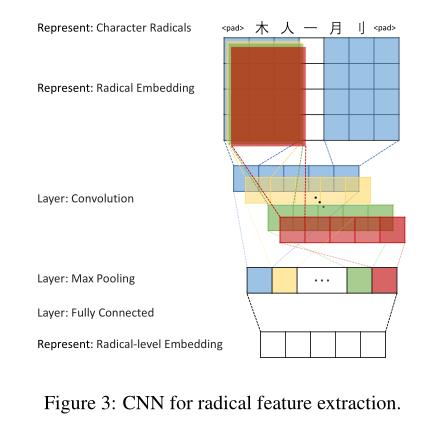
用于部首特征提取的CNN:
以上是关于论文泛读164MECT:基于多元数据嵌入的中文命名实体识别交叉变换器的主要内容,如果未能解决你的问题,请参考以下文章