论文泛读131DocNLI:用于文档级自然语言推理的大规模数据集
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读131DocNLI:用于文档级自然语言推理的大规模数据集相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《DocNLI: A Large-scale Dataset for Document-level Natural Language Inference》
一、摘要
自然语言推理 (NLI) 被制定为解决各种 NLP 问题(例如关系提取、问答、摘要等)的统一框架。 由于大规模标记数据集的可用性,它在过去几年中得到了深入研究。然而,大多数现有研究仅关注句子级推理,这限制了 NLI 在下游 NLP 问题中的应用范围。这项工作展示了 DocNLI——一个新构建的用于文档级 NLI 的大规模数据集。DocNLI 从广泛的 NLP 问题转化而来,涵盖多种类型的文本。前提始终保持在文档粒度上,而假设的长度从单个句子到包含数百个单词的段落不等。此外,DocNLI 的工件非常有限,不幸的是,这些工件广泛存在于一些流行的句子级 NLI 数据集中。我们的实验表明,即使没有微调,在 DocNLI 上预训练的模型在流行的句子级基准测试中也表现出良好的性能,并且可以很好地推广到依赖文档粒度推理的域外 NLP 任务。针对特定任务的微调可以带来进一步的改进。可以在以下位置找到数据、代码和预训练模型:github。
二、结论
在这项工作中,我们收集并发布了一个大规模的文档级NLI数据集DOCNLI。它涵盖了多种体裁和多种长度范围的前提和假设。我们希望这个数据集可以帮助解决一些需要文档级推理的NLP问题,如QA、摘要、事实检查等。实验表明,DOCNLI模型可以很好地概括下游的NLP任务和一些常用的句子级NLI任务。
三、数据集介绍
- DOCNLI与最终的NLP任务高度相关。对DOCNLI来说,一个性能良好的系统有望为解决其他NLP挑战带来启示。
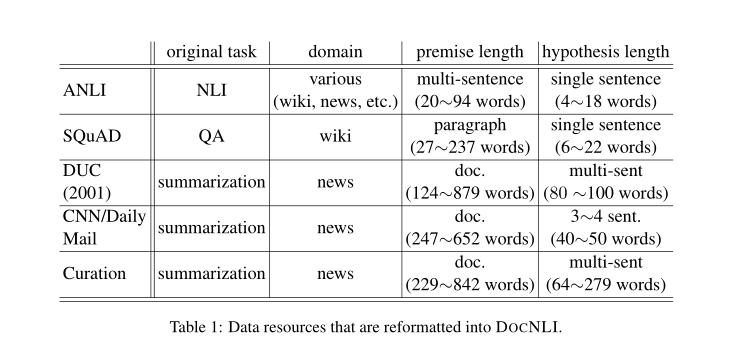
- 前提总是有多个句子;其中大多数是自然文档,如新闻文章。假设的长度有很多种,从一个句子到上百个单词的文档。通过这种设置,我们希望系统能够学会处理未来需要推断一段文本的真值而不管其长度的应用程序。
- 与一些现有的句子级NLI数据集相比,DOCNLI的人工制品非常有限。我们提出了一种新的方法来断开潜在的工件与NLI任务本身;“仅基于假设”的基线很难发现一些虚假的相关性。
重新格式化为DOCNLI的数据资源:
以上是关于论文泛读131DocNLI:用于文档级自然语言推理的大规模数据集的主要内容,如果未能解决你的问题,请参考以下文章
论文速递NAACL2022- 文档级事件论元抽取的双流AMR增强模型