论文速递NAACL2022- 文档级事件论元抽取的双流AMR增强模型
Posted Trouble..
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文速递NAACL2022- 文档级事件论元抽取的双流AMR增强模型相关的知识,希望对你有一定的参考价值。
【论文速递】NAACL2022- 文档级事件论元抽取的双流AMR增强模型

论文:[2205.00241] A Two-Stream AMR-enhanced Model for Document-level Event Argument Extraction (arxiv.org)
期刊/会议:NAACL 2022
摘要
以往的研究大多致力于从单个句子中抽取事件,而文档级别的事件抽取仍未得到充分的研究。在本文中,我们专注于从整个文档中抽取事件论元,主要面临两个关键问题:1)触发词与语句论元之间的长距离依赖关系;B)文件中一个事件的分散在上下文中。为了解决这些问题,我们提出了一个Two-Stream Abstract meaning Representation enhance extraction model(TSAR)。TSAR通过双流编码模块(two-stream encoding module)从不同角度对文档进行编码,以利用本地和全局信息,并降低分散在上下文的影响。此外,TSAR还引入了基于局部和全局构建的AMR语义图的AMR引导交互模块(AMR-guided interaction module),以捕获句内和句间特征。引入一种辅助边界损失来显式增强文本跨度的边界信息。大量实验表明,TSAR在公共RAMS和WikiEvents数据集上的性能分别提高了2.54 F1和5.13 F1,在跨句论元抽取方面表现出了优势。
1、简介
事件论元抽取(Event Argument Extraction, EAE)旨在识别作为事件论元的实体,并预测它们在事件中扮演的角色,这是事件抽取(Event Extraction, EE)的关键步骤。它有助于将非结构化文本转换为结构化事件知识,可以进一步用于推荐系统、对话系统等。大多数先前的研究假设事件仅仅出现在单个句子中,因此聚焦在句子级别的研究上。然而,在现实场景中,事件通常是通过由多句话组成的整个文档来描述的(例如,一篇新闻文章或一份财务报告),这仍然有待研究。

图1演示了文档级EAE的一个示例,其中Transport事件由shipment触发。与句子级的EAE不同,从整个文档中抽取论点面临两个关键挑战。(1)触发词与论元之间的远距离依赖(long-distance dependency)。这些论元通常位于与触发词不同的句子中,而且它们的距离可能相当远。在图1中,虽然触发词shipment在第2句中,但vehicle(车辆)、origin(原产地)、artifact(工件)和importer(进口商)等论元位于第1句或第3句中,这极大地增加了抽取的难度。为了适应长范围抽取,不仅要对句内语义进行建模,而且要对句间语义进行建模。(2)语境分散(distracting context)。虽然一份文档自然包含了比一句话更多的上下文,但有些内容会让人分心。上下文可以误导论元抽取。如图1所示,不需要第4句,就可以更容易地确定origin论元 U.S. ,第4句没有提供事件的有用信息,但包含了许多可能分散注意力的place(位置)实体,如Saudi Arabia(沙特阿拉伯)、Russia(俄罗斯)或Iran(伊朗)。在剔除那些分散注意力的信息的同时,找出有用的上下文仍然具有挑战性。
最近,Du和Cardie使用了一种基于标记的方法,该方法无法处理嵌套论元。相反,基于跨度的方法预测候选跨度的论元角色。一些研究直接生成基于序列到序列模型的论元。然而,如何在触发词和论元之间建模长距离依赖关系,以及如何显式地处理分散注意力的上下文,在很大程度上仍有待探索。
在本文中,为了解决上述两个问题,我们提出了一个双流增强抽取模型(two - stream AMR-enenhanced extraction model, TSAR)。为了利用文档中的基本上下文,并避免被干扰所误导,我们引入了一个双流编码模块。它由一个全局编码器和一个局部编码器组成,前者使用尽可能多的上下文对全局语义进行编码,以收集足够的上下文信息;后者专注于最基本的信息,并谨慎地考虑额外的上下文。这样,TSAR可以利用不同编码视角的互补优势,从而更好地利用可行上下文来受益于抽取。此外,为了模拟远程依赖关系,我们引入了AMR引导的交互模块。抽象语义表示(AMR)图包含了不同概念之间丰富的层次语义关系,有利于复杂事件的抽取。从这种语言驱动的角度出发,我们将文档的线性结构转换为全局和局部的图结构,然后使用图神经网络来增强交互,特别是那些非局部元素。最后,由于TSAR在span级别抽取论元,其中span边界可能是模糊的,我们引入了一个辅助边界损失来增强具有校准边界的span表示。
总之,我们的贡献有三方面。1)提出了文档级EAE的双流编码模块,该模块通过两个不同的视角对文档进行编码,从而更好地利用上下文。2)引入了AMR引导的交互模块,以促进文档内部的语义交互,从而更好地捕获长距离依赖关系。3)我们的实验表明,TSAR在公共RAMS和WikiEvents数据集上分别提高了2.54 F1和5.13 F1,特别是在跨句事件参数抽取方面。
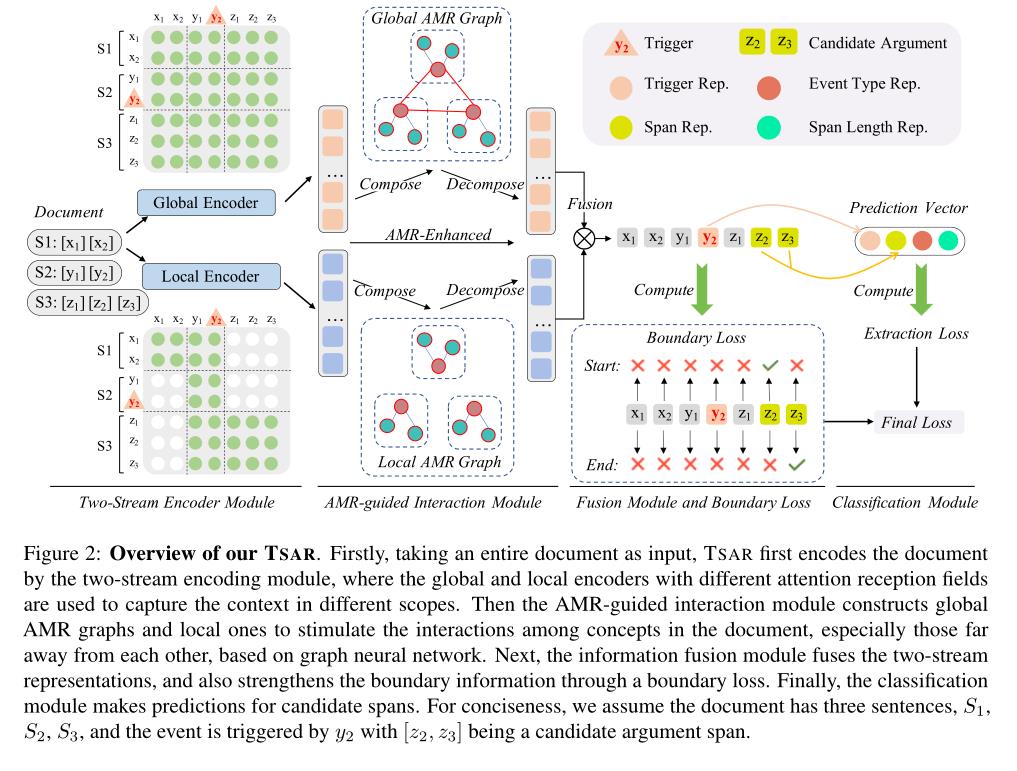
模型架构
图2显示了我们的模型TSAR的整体架构。文档被送入双流编码模块,然后由AMR引导的交互模块导出全局和局部上下文化表示。信息融合模块融合这两个流表示,分类模块最终预测候选跨度的论元角色。
实验结果
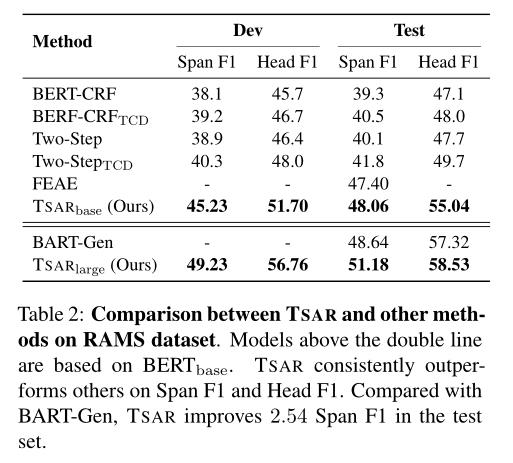
表2说明了RAMS数据集上的开发集和测试集的结果。由图可知,在基于 B E R T b a s e BERT_base BERTbase的模型中,TSAR的性能优于以往的其他方法。例如,在开发集中,与之前的方法相比,TSAR产生了4.93 ~ 7.13 Span F1和3.70 ~ 6.00 Head F1的改进,在测试集中达到8.76 Span F1。此外,在基于大型预训练语言模型的模型中,TSAR优于BART-Gen 2.54 Span F1和1.21 Head F1。这些结果表明,以双流方式编码文档,并引入AMR图来促进交互,有利于捕获句内和句间特征,从而提高性能。

此外,我们跟随Li等人(2021)评估了论元识别和论元分类,并报告了Head F1和Coref F1。识别需要模型正确检测论元跨度边界,而分类则需要进一步正确预测其论元作用。如表3所示,在这两项任务中,TSAR的表现始终优于其他人。与BART-Gen相比,TSAR在论元识别方面提高了4.87/3.23 Head/Coref F1,在论元分类方面提高了5.13/3.68 Head/Coref F1。在基于 B E R T b a s e BERT_base BERTbase的模型中也出现了类似的结果,Head F1在鉴别和分类上分别提高了5.69 ~ 36.37和11.95 ~ 33.34。这些结果表明,TSAR不仅在论元跨度边界的检测上,而且在预测它们的作用方面优于其他方法。
【论文速递 | 精选】

如有兴趣可以查看全文理解
以上是关于论文速递NAACL2022- 文档级事件论元抽取的双流AMR增强模型的主要内容,如果未能解决你的问题,请参考以下文章