论文泛读70检索,阅读,重新排序,然后进行迭代:从文本中回答各种推理步骤的开放域问题
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读70检索,阅读,重新排序,然后进行迭代:从文本中回答各种推理步骤的开放域问题相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
一、摘要
我们开发了一个统一的系统,可以直接从文本开放域问题中回答,这些问题可能需要不同数量的检索步骤。我们采用单一的多任务转换器模型以迭代方式执行所有必要的子任务-检索支持事实,对其进行排名并从所有检索到的文档中预测答案。由于先前的工作无法很好地适应现实环境,因此我们避免做出关键的假设,包括利用对回答每个问题所需的固定数目的检索步骤的了解,或者使用结构化的元数据(例如知识库或网络链接)来获取有限的可用性。取而代之的是,我们设计了一种无需事先知道推理复杂性就能回答任何文本集合中的开放域问题的系统。要模拟此设置,我们通过将现有的一步和两步数据集与203个问题的新集合相结合来构建新的基准,这些问题需要三个Wikipedia页面来回答,并在此过程中统一Wikipedia语料库版本。我们证明了我们的模型在现有基准和新基准上都展示了竞争性能。
二、结论
在这篇论文中,我们介绍了迭代检索器、阅读器和IRRR,这是一个使用单一模型执行子任务来回答任意推理步骤的开放领域问题的系统。IRRR在标准的开放域质量保证基准测试中取得了有竞争力的结果,并在新的统一基准测试中建立了一个强有力的基准,我们提出了复杂程度不同的问题。
三、model
IRRR问题回答(分五步):
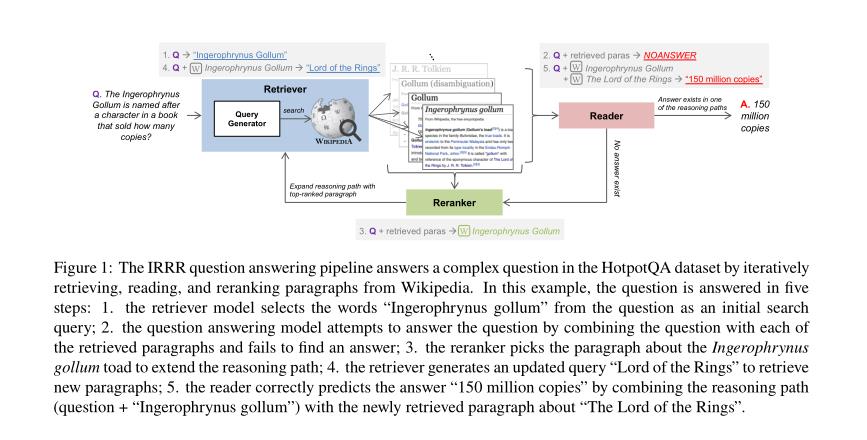
以上是关于论文泛读70检索,阅读,重新排序,然后进行迭代:从文本中回答各种推理步骤的开放域问题的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读63弱监督的开放域问答中的潜在检索(ORQA-开放检索问答)