HDFS读写流程YARN_MR提交运行流程
Posted 保护胖丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS读写流程YARN_MR提交运行流程相关的知识,希望对你有一定的参考价值。
HDFS 写入流程:
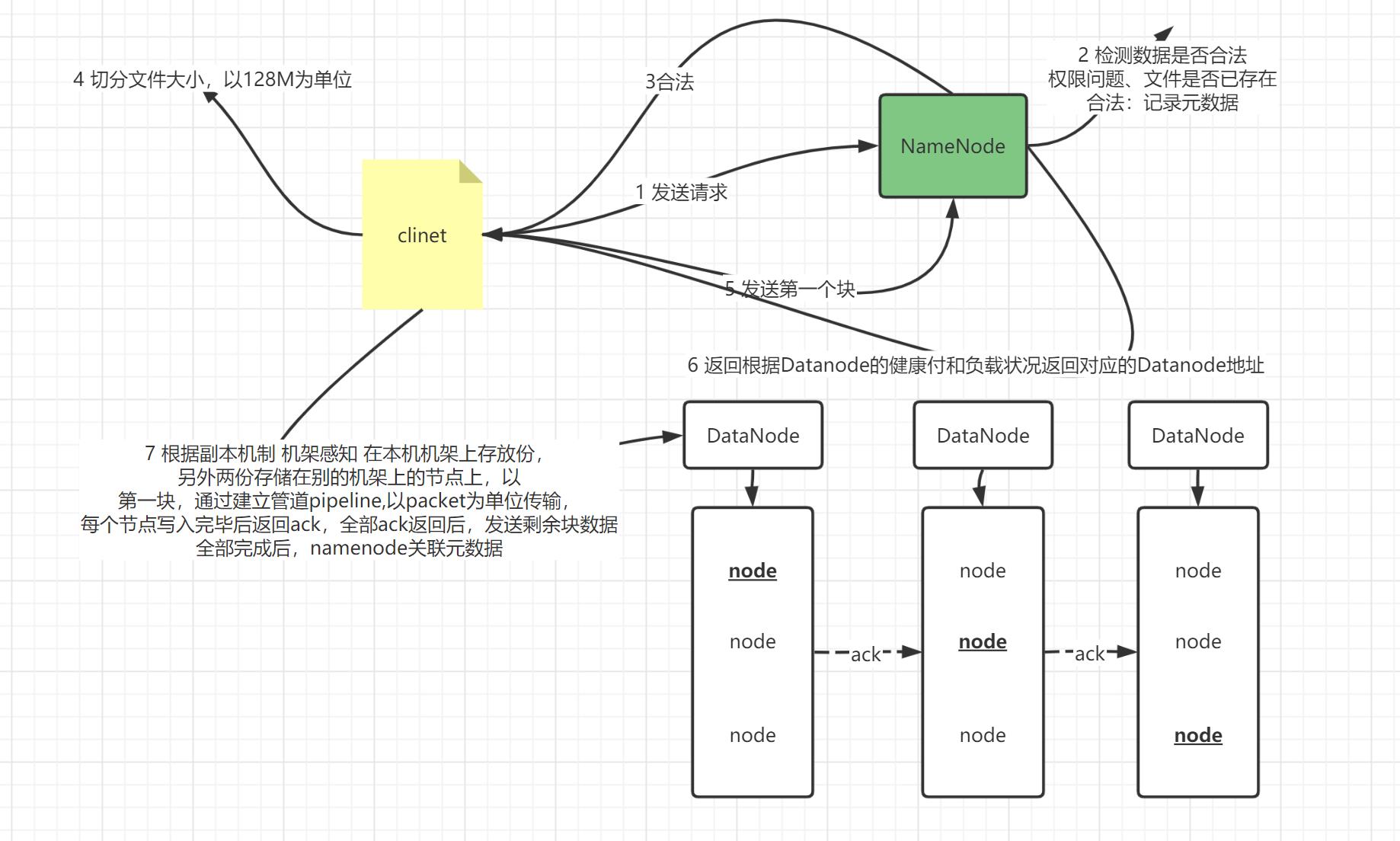
- step1:客户端会请求NameNode写入HDFS,NameNode会验证请求是否合法,返回结果
- NameNode验证写入的文件是否存在、有没有权限写入等等
- 如果不合法,直接拒绝请求
- step2:NameNode返回对应的结果,构建这个文件的元数据:并没有跟块关联
- step3:客户端提交第一个块的写入请求给NameNode
- step4:NameNode根据每个DN的健康状态以及负载情况返回三台DataNode 地址
- blk1-0:node1
- blk1-1:node2
- blk1-2:node3
- 机架感知的分配规则
- 客户端所在的机架放一份
- 另外两份在另外一个机架中
- step5:客户端得到要写入数据块的三台DN地址,客户端会连接第一台【离它最近的那台】,提交写入
- 由机架感知决定谁最近
- step6:三台DN构建一个数据传输的管道
- step7:客户端将这个块拆分成多个packet【64k】,挨个发送个最近的这台DN1
- step8:逐级返回写入成功的ack确认码,表示这个包写入完成
- step9:不断发送下一个包,直到整个块写入完成,返回给NameNode,关联元数据
- step10:重复3提交下一个块写入
HDFS 读取流程: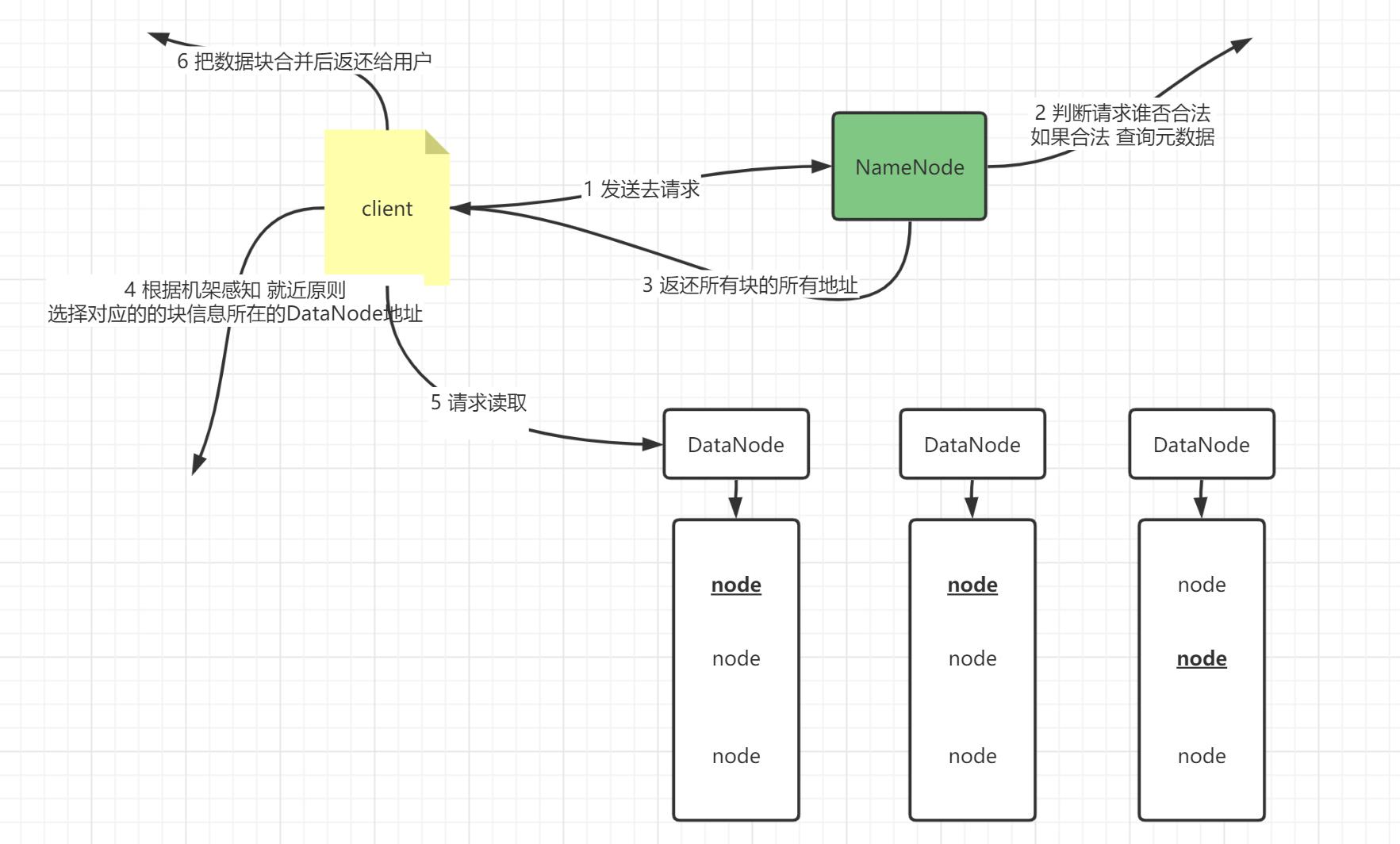
- step1:客户端提交读取请求给NameNode
- step2:NameNode会验证这个请求是否合法,如果合法,会查询元数据
- step3:NameNode会返回所有块的所有地址
- blk1:node1,node2,node3
- blk2:node4,node5,node6
- blk3:node7,node8,node9
- step4:客户端拿到列表,会根据机架感知从每个块的列表中,选择离自己最近的节点去请求读取
- blk1:node1
- blk2:node5
- blk3:node9
- step5:客户端会将所有块进行合并返回给用户
YARN_MR提交运行流程:
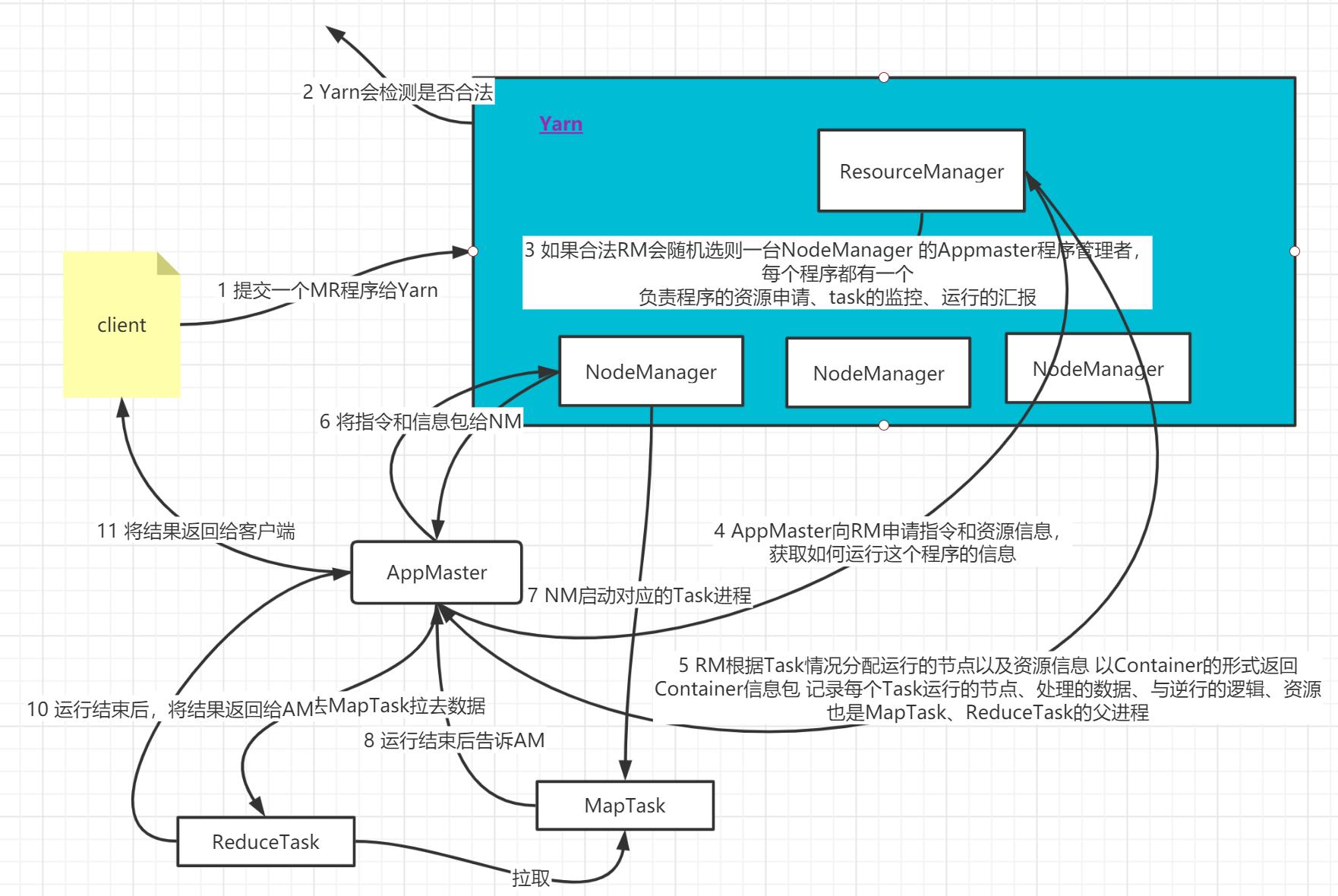
- step1:客户端提交运行一个MapReduce的程序给YARN,YARN会检查请求是否合法
- step2:如果合法,RM会随机选择一台NodeManager启动这个程序的管理者:AppMaster
- AppMaster每一个程序都有一个
- 负责这个程序的资源申请、Task的运行、Task的监控,运行的汇报
- step3:APPMaster会向ResourceManager申请指令和资源信息,获取如何运行这个程序的信息
- step4:ResourceManager根据Task的情况分配运行的节点以及资源的信息,以Container的形式返回
- Contiainer:信息包,记录每个Task运行的节点、处理的数据、运行的逻辑、资源
- 也是MapTask和ReduceTask的父进程
- Contiainer:信息包,记录每个Task运行的节点、处理的数据、运行的逻辑、资源
- step5:APPMaster将指令和container信息分发给对应的NodeManager,每个NodeManger根据指令和资源来启动对应的Task进程
- step6:MapTask运行结束后,会通知AppMaster,APPMaster会通知ReduceTask到MapTask中拉取数据
- step7:ReduceTask到每个MapTask中拉取数据,并执行处理,最后运行结束,将结果返回给APPMaster
- step8:最终结果返回给客户端
以上是关于HDFS读写流程YARN_MR提交运行流程的主要内容,如果未能解决你的问题,请参考以下文章