大数据系列文章-Hadoop的HDFS读写流程
Posted zhangyongli2011
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据系列文章-Hadoop的HDFS读写流程相关的知识,希望对你有一定的参考价值。
在介绍HDFS读写流程时,先介绍下Block副本放置策略。
Block副本放置策略
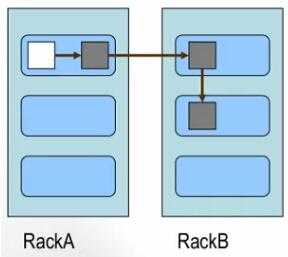
- 第一个副本:放置在上传文件的DataNode;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
- 第二个副本:放置在与第一个副本不同的机架的节点上。
- 第三个副本:与第二个副本相同机架的节点。
- 更多副本:随机节点。
HDFS写流程
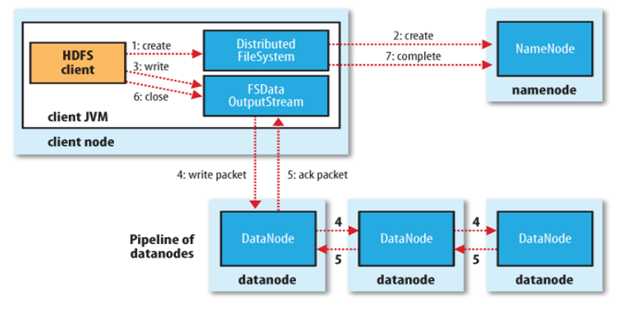
- 客户端发请求给NameNode,我想保存一个文件A,这时候在NameNode会有一个标识,标识为A_copy(文件不可用)。
- 根据副本放置策略,返回三个副本的可放置位置列表,且默认为sort排好顺序的。
- 客户端主动去和离自己最近的DataNode连接(暂且叫DN1),然后DN1后续的DN2进行连接,DN2在和DN3进行连接。(串联方式Pipeline)
- 客户端读取源文件,对该Block进行更小的切割,
- 第一次:传递第一个Block中的第一个小包给DN1。
- 第二次:传递第一个Block中的第二个小包给DN1,与此同时,DN1中的第一个小包传递给DN2。
- 第三次:传递第一个Block中的第三个小包给DN1,与此同时,DN1中的第二个小包传递给DN2,DN2传递第一个小包给DN3.
- 依次类推
(Block切割更小的小包,这里这么设计的好处是时间不重叠。如果不切,一次性传递例如64M,当传递DN1时,等待,传递DN2时,继续等待,传递DN3时,还在等,造成时间浪费。另外的一个好处时,如果增加节点,时间影响不大)
- 最后通过DataNode与NameNode心跳,通知是否文件彻底传递完毕,补全NameNode中元数据的位置信息。
HDFS读流程
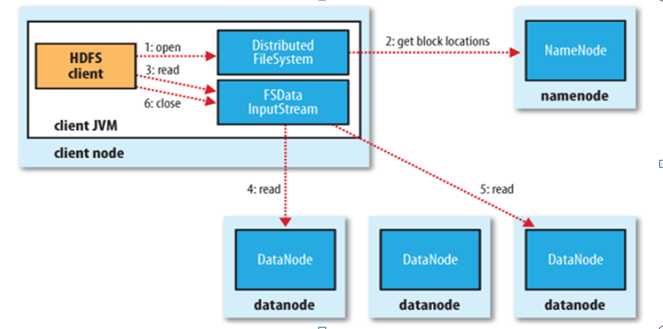
- 客户端发请求给NameNode,NameNode将这个文件的元数据找到,告知给客户端(例如文件A,被切割为5个Block,元文件会纪录Block1:DN1,DN2,DN3,Block2:DN1,DN4,DN5等等依次类推)
- 客户端直接向DataNode请求Block数据(遵循距离优先)
- 当把所有的Block下载回本地后,进行验证每个Block元信息的MD5。如果每个Block都是正确的,没有被破坏,开始进行拼接,最终文件就被还原回来了。
HDFS文件权限
- 与Linux文件权限类似
- r:read;w:write;x:execute
- 权限x对应文件忽略,对于文件夹表示是否允许访问其内容
- 如果Linux系统用户zhangyongli使用Hadoop命名创建一个文件,那么这个文件在HDFS中owner就是zhangyongli
- HDFS的权限目的,阻止好人做错事,而不是阻止坏人做坏事。HDFS相信,你告诉我你是谁,我就认为你是谁。
解释:
- 阻止好人做错事:例如AB两个用户,A用户创建了一个X文件,B用户创建了一个Y文件,B用户删除不了A用户的文件X。
- 阻止坏人做坏事:如果AB两个用户中的某个坏人,装了一台全新的linux系统,也创建AB用户,补全Hadoop部署文件内容,客户端程序,然后用新系统的A向NameNode去删除X文件,由于NameNode是被动受信,所以未来需要集成kerberos来防止这种操作。
(转发请注明出处:http://www.cnblogs.com/zhangyongli2011/ 如发现有错,请留言,谢谢)
以上是关于大数据系列文章-Hadoop的HDFS读写流程的主要内容,如果未能解决你的问题,请参考以下文章