分布式事务从入门到放弃--数据一致性引擎概览
Posted 程序员大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务从入门到放弃--数据一致性引擎概览相关的知识,希望对你有一定的参考价值。
????????关注后回复 “进群” ,拉你进程序员交流群????????
作者丨成小灰
来源丨Coder的技术之路
一、 项目背景简介
一般,广告检索系统都承载着公司很大比重的营收占比。
计费系统是广告系统的偏底层一环,承担着反作弊、计算费用、优惠扣减、费用实际扣除等职责。整个扣费流程涉及到了计费单、营销系统、支付账务系统、预算系统等的上下游数据一致性问题。
并且,由于存在CPT、CPA、CPC等不同类型的计费方式,而广告点击有流量不可回溯等特点(普通支付场景可以让用户重试),计费的数据一致性引擎的合理设计就变得尤为重要了。
二、一致性保障方案选择
支付业务一般的可以分为两种,一种是有支付牌照的公司,直接和账户和银行打交道;另一种是调用第三方支付服务,实现支付业务。
对于第一种场景,一般需要非常强硬的保障手段来实现分布式下数据的强一致性。比如TCC的类二阶段提交方式,我们知道,TCC之所有被大家熟知,也是因为蚂蚁不遗余力布道的结果。
对于第二种场景,相对来说,诉求可能就没有那么的变态了,有不少的解决方案可供选择,比如本地消息表、事务型消息等等。。。
当前项目的场景显然属于第二种。那么,应该怎么合理选择实现方式呢:
事务型消息
「实现方案轻量,改造成本小,适合为对实时性不是特别高的场景。」
咦~ 好像正合适,可惜,公司自研的消息中间件不支持!!!
当然,事务型消息的处理方式,也存在弊端,就是每个系统只能负责自己这一块,流程变得冗长,不利于问题排查。万一要改点东西,可能还得上下游一块来,业务耦合程度可能要高一些。
TCC模式
感觉如果阐述TCC的原理,可能需要单开一个系列来说了,这里简单说下.
因为之前的工作中用的就是TCC的分布式事务,说实话,系统实现真的是非常的重。
需要流程中的所有系统,都按照既定的规范来实现一套包含了try/commit/cancel三个处理逻辑的调用模板。 需要各系统按规范创建主事务表和分支事务表,来记录事务状态和调用参数及路由。 需要参与者创建事务幂等表,实现拒绝空回滚或拒绝后到达的资源扣减等的防悬挂逻辑。
光是让各系统配合实现几个接口,我觉得,如果没有非常大的资金风险压迫,没几个人会配合。
而且,TCC可能更适用于有用户直接参与的资源扣减场景,因为引擎的基本思路是失败时操作回滚,保证上下游一致。
但是,上面也说过了,广告点击流的特点是流量不可回放,这个点击,过去了也就过去了,用户不可能因为这次计费没成功,就帮我们再点一次。所以,我们的一致性引擎的恢复逻辑,不仅要支持回滚,还要支持重试。不可漏掉每一次点击计费。
saga模式
最终,我们参考saga模式,选择的是类saga的状态机引擎的补偿模式。
这种方式的优点是,对老系统改造成本友好,即使实现接口也比较方便,通过状态机编排执行节点链,并配置重试回滚方式、实时异步策略。
事务信息存储方式相对灵活,主要看自己公司的各种存储的可靠性和一致性的承诺。
详见下面实现。
三、数据一致性引擎效果一览
引擎架构图
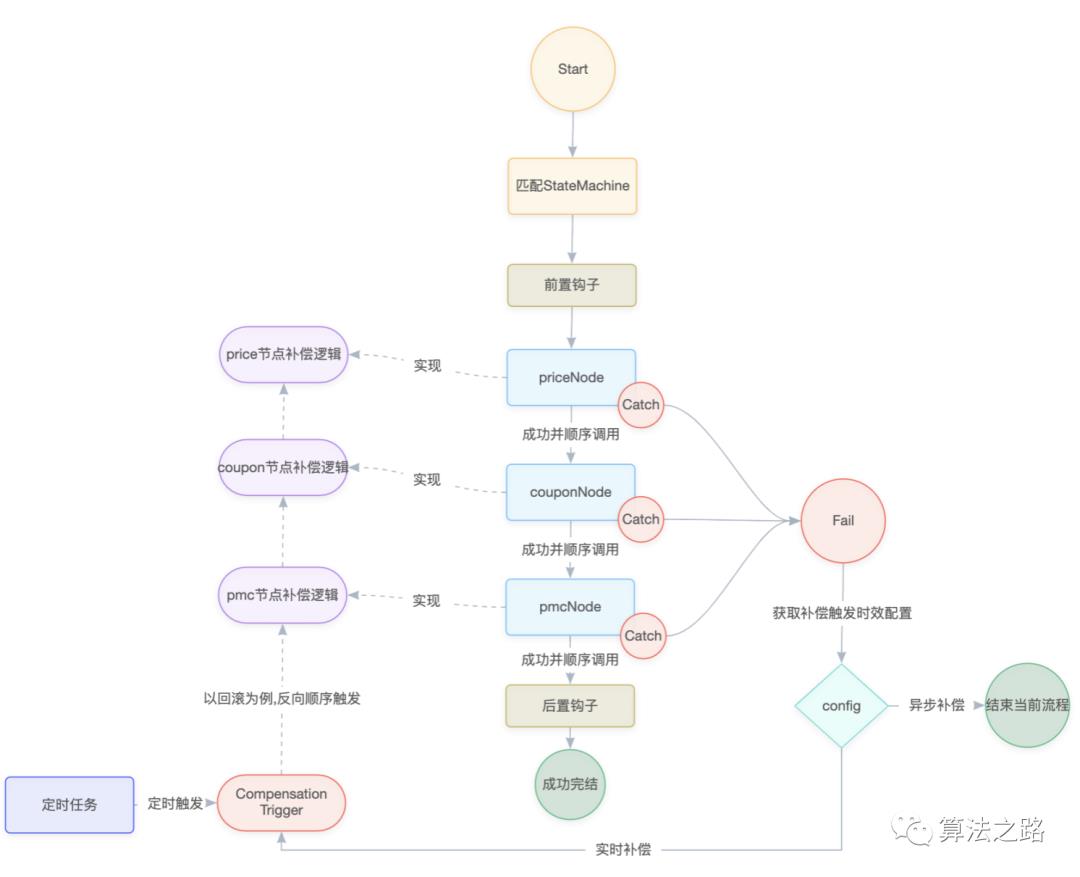
结构组成
状态机 实现节点执行顺序编排及其他执行特性
节点 业务需要实现的逻辑节点,比如计费的cpc扣费逻辑,需要有前置check、price调价、coupon优惠券、pmc扣费等执行节点
补偿逻辑 属于节点的一部分实现,每个执行节点需要实现当前节点的补偿逻辑,以供执行异常时进行恢复操作
钩子函数 在引擎执行前和执行后,允许业务系统执行自有的特殊操作
定时任务 异常数据恢复的触发入口
其他特性
补偿方式 可配置,有重试/回滚 两种补偿方式可选;重试补偿时,执行顺便和正常顺序一致,回滚补偿时,从最后一个执行节点往前回滚
补偿触发时效 可配置,有实时/异步延时 两种触发策略可选,如果有资源悬挂的风险,建议选异步延时触发
重试次数及时间衰减 可配置,按业务实际情况定制衰减序列
状态机配置实例
{
"name": "xxxx_xxxx_xxxx",
"comment": "cpc计费状态机",
"firstNodeName": "check",
"nodes": {
"check": {
"nextNodeName": "land",
"preNodeName": "",
"skipRecover": true
},
"land": {
"nextNodeName": "antiFraud",
"preNodeName": "check",
"skipRecover": false
},
"antiFraud": {
"nextNodeName": "realPrice",
"preNodeName": "land",
"skipRecover": false
},"...":{"..."}
},
#重试次数
"retryCount": "4",
#重试时间衰减
"timeDecaySeries": ["1","3","5","10"],
#补偿策略,重试/回滚
"recoverType": "Retry",
#触发时效,实时触发/异步触发
"compensateTimeliness": "ASYNC"
}引擎初始化
DTConfig.builder()
.setAppName("billing")//配置appName
.setLogStoreStrategy(StoreStrategyEnum.DEFAULT_STORE)//存储策略
.setRedisConfig(redisConfigPath) //设置redis配置
.setDBTableConfig(mysqlConfigPath) //mysql配置
.setZKConfig(configPath) // wConfig 配置 ,切流灰度使用
.setStateMachinePath(stateMachinePath)//状态机配置项地址
.setNegligibleErrorCode(BillingDTConstants.serious_error_code_str) //当前系统关键异常code集合(不可忽略的致命异常,供恢复逻辑使用)
.build();
引擎调用
//本次调用所使用的状态机名称
String stateMachineName="ecpm_state_machine"; //当前请求使用到的状态机名称(和状态机配置中的name一致)
//获取引擎实例
DTBizEngine dtBizEngine=new SagaDTBizEngine();
//组装入参执行调用
DTResponse response= dtBizEngine.start(new DTEngineRequest(bizType,bizId,stateMachineName,originContext));
//打印结果
System.out.println(response.getData());
异步化(参考dubbo的异步化实现的)
主线程
try {
//创建 DTFurure ,传入 (DTEngineRequest request , int timeout)
DTFuture mFuture=new DTFuture(request, 1000);
//将该future传递下去,也可以用其他方式传递,这里直接放到了request扩展字段做示例
request.getExtendField().put("MY_KEY",mFuture);
//异步线程调用
EcpmEventBus.getInstance().post(new EcpmBillingEvent(request));
//有限时间超时等待,get到的结果是业务完成时设置进来的对象,业务系统可以按自己的场景转换
Object future= mFuture.get(1000); //单位是毫秒
//do something
} catch (Exception e) {
}
执行线程
//do something ...
DTFurure futrue=(DTFurure)request.getExtendField().get("MY_KEY");
DTFuture.received(futrue.getId(),response);
四、后记
本篇介绍了一个数据一致性项目的背景和方案选择过程,并给出了一个参考saga模式的状态机实现的一致性引擎。
算是分布式事务系列的开篇,下一篇主要介绍引擎中各模块的设计和使用,每个模块的详细实现,将在后续文章的逐步完善。
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击????卡片,关注后回复【面试题】即可获取
在看点这里![]() 好文分享给更多人↓↓
好文分享给更多人↓↓
以上是关于分布式事务从入门到放弃--数据一致性引擎概览的主要内容,如果未能解决你的问题,请参考以下文章