分布式事务从入门到放弃--详述DT引擎一致性原理及设计
Posted 程序员大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务从入门到放弃--详述DT引擎一致性原理及设计相关的知识,希望对你有一定的参考价值。
????????关注后回复 “进群” ,拉你进程序员交流群????????
作者丨成小灰
来源丨Coder的技术之路
❝分布式事务解决什么问题
❞
准备调用下游扣费,或刚调起下游扣费接口,服务宕机了,怎么办?
调用下游超时,不知道下游是否执行怎么办?
调用下游时发生网路堵塞,回滚先到扣费操作后到被悬挂怎么办?
整个事务需要同时满足重试和回滚操作怎么办?
因为支付系统大面积重试时,优惠券节点也要重试么?
重试失败怎么办?重试间隔怎么设置?
下面就带着这些待解决的场景问题,看看 DT 引擎是个什么东西
DT 引擎是个什么东西
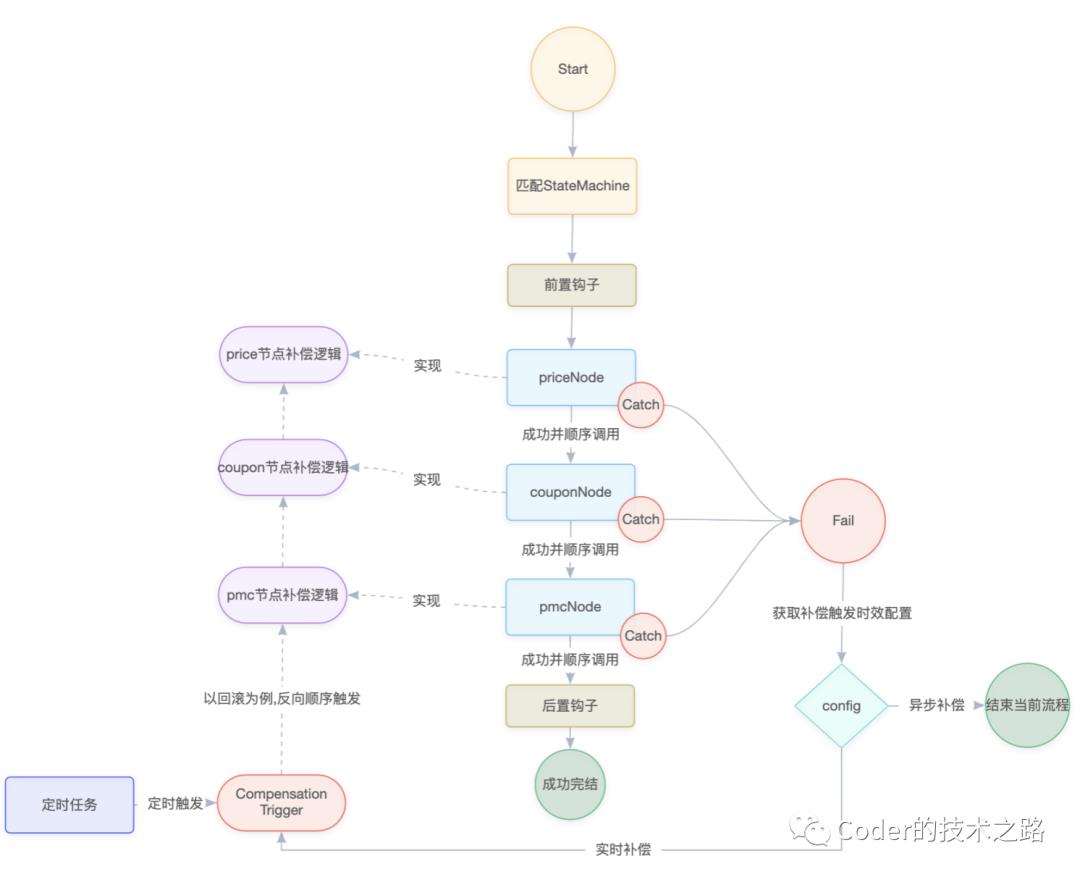 从上图可以看到,DT 的核心组成包括三大部分:
从上图可以看到,DT 的核心组成包括三大部分:
事务协调器:负责节点编排、结果判断、分支路由等主要功能。
业务执行及补偿节点 :负责调用业务系统实现的多个执行节点。
异步补偿触发:负责在执行异常时,异步调起恢复任务并触发执行。
「总结下,DT 是个以状态机为基础的,补偿式的分布式长事务一致性保障引擎。」
下面将详述每个模块的实现方案和细节。
DT 引擎原理介绍
「理论基础」:是从Hector&Kenneth在1987年发表的《Sagas》论文中演化而来: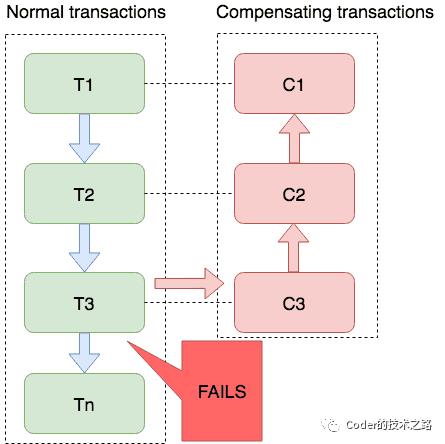 (该图片来自网络)
(该图片来自网络)
图中绿色的部分是正向执行逻辑,发起方逐个调用,参与者不分阶段,直接执行并提交本地事务.
当链路中某个参与者执行逻辑发生异常时,则依据实际配置,执行补偿--回滚或重试。
适用场景:
业务流程长、业务流程多;
业务场景除了回滚还有重试等场景。
参与者没法保证提供 TCC 接口。
优势:
一阶段提交本地事务,无锁,高性能、事件驱动架构;
参与者可异步执行,高吞吐;补偿服务易于实现。
缺点:不保证隔离性
模块设计详解
相比Seate里的saga, 原理都是一样的,但是内部实现很多实现方案进行了精炼和一些专属定制化的开发。
比如,saga 中的状态机定义内容非常庞大,几乎所有的内容都出现在了配置文件中,而 DT 精简到了只剩下节点编排,且顺序固定,不支持节点间路由跳转(因为感觉也没必要~)。
诸如此类的定制等等~
其目的,不是为了重复造轮子,是为了有一致性诉求,但是不想对接庞大的解决方案的同学们,提供一种轻量级的处理方案。参考上一篇DT的使用描述来看下面的内容可能会更清晰~
事务协调器
协调器的主要职责,是执行节点的流程编排、事务的开启、节点状态的维护和上报、全局状态的维护和更新、全局事务完结后的后续处理等。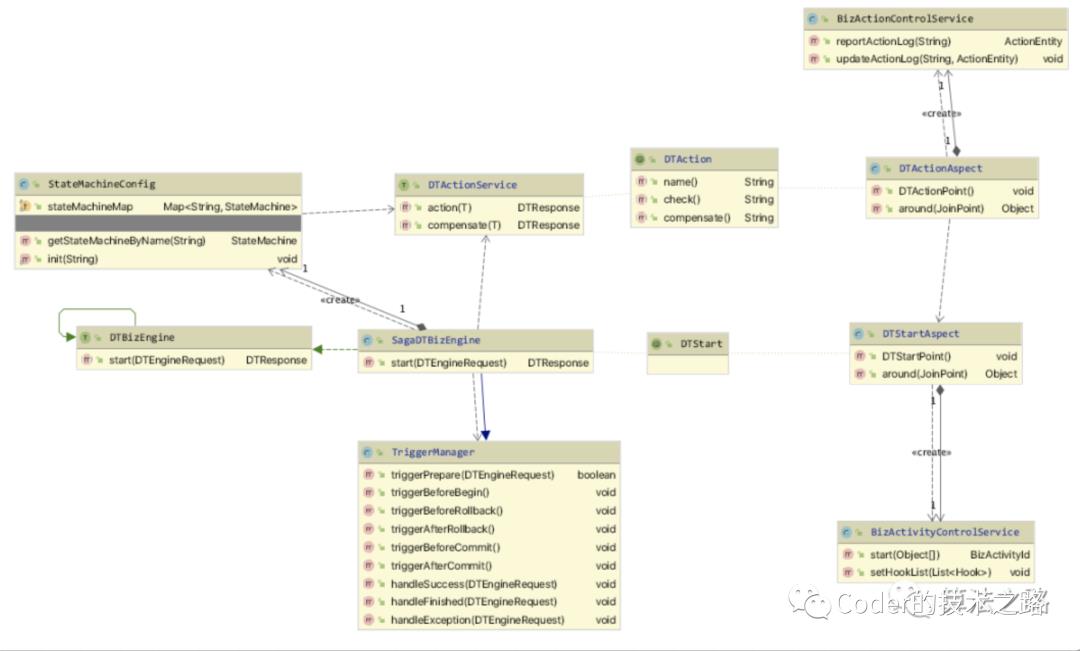 整个事务协调器类图如图所示:
整个事务协调器类图如图所示:
DTBizEngine接口定义了引擎的执行入口,具体实现策略都继承自它。SagaDTBizEngine是saga模式的具体实现类。通过
DTStart注解实现启动拦截器,执行事务启动初始化操作。通过
DTAction注解实现业务节点拦截器,执行数据上报和状态维护。引擎通过
config类拿到业务配置的DTactionService实例执行链,执行action方法以触发业务逻辑。TriggerManager负责调取框架定义+业务自定义的「钩子函数」,负责处理各个不同的执行阶段的特殊处理。整个业务流程,均由事务协调器协调处理。业务系统只需要实现每个节点的
DTactionService.action接口和compensate接口
「为了达到进度协调且保证各节点之间的数据一致性,有一些核心的问题需要解决。下面我们详细说明」
状态机的设计和维护
状态机的配置决定了事务的节点编排和执行流程。既要决定正常的业务执行流程,还要考虑不同场景下的可配置策略。
重试和回滚
回滚,需要从最后一个节点往前回滚。而重试,则需要从前往后执行,因此,状态机节点需要和二叉树一样,将pre 和next节点维护起来。
目前这种方式,是一种极简方式,适用于业务流程比较固定的场景。如果有节点路由的诉求,那另当别论了。
异常捕获
业务执行过程中可能会遇到不同类别的异常。
有些异常是可以忽略的,比如某作弊流量查某个关键配置时未查到,可以直接过滤,不进行后续流程。而个别的严重异常是我们不希望忽略的,比如调支付系统失败,超时等等。
而有些节点,包含了上述两种异常,而有些节点,所有异常均不能忽略。
所以,我们在捕获异常方面会支持两种配置方式:
「整个节点异常不可忽略」
「不可忽略的异常码列表」
如果当前节点配置了所有异常不可忽略,会直接进入补偿流程。如果没有配置该参数,则会在不可忽略的异常码列表中查询匹配。
重试时间衰减
为了防止下游系统异常恢复不及时和异常请求因特殊情况被防止无限期补偿等场景,我们做了重试时间衰减策略。该时间衰减序列被维护在状态机配置中,比如
「1,3,5,10」
则,框架在捞取异常数据进行处理时,会计算上次补偿的时间是否满足该时间序列,再进行执行。
主事务和分支事务
我们需要依赖主事务串联整个流程,依赖分支事务在执行异常时感知各参与者的执行结果。
一般在TCC模式下,绝大部分情况都以本地数据库事务为依托,会把主事务的创建、参与者的调用包在本地事务内部,这样,使用同一个数据库创建主事务和分支事务表,天然保证和本地业务数据的一致性。这样数据的压力也会有所增加,基本都是在分库分表之后,把压力均摊到分库上完成性能要求。
但是,还有一些情况另外,比如我们目前的业务,为了提高性能,没有启动本地事务,相当于是在裸跑。
那么,一个关键的问题就是数据存储的稳定性和流程阻断方案的完善。
一是需要一个高性能的存储来满足数据的强一致性要求,可以允许存储操作失败,但是决不允许接口返回成功,实际上数据丢失的情况发生。
二是一个完善的流程阻断方案:我们的存储操作一般分为前置操作和后置操作,如主事务插入和分支事务插入都是前置操作,而分支事务状态更新则是后置操作。在前置操作时失败,则流程阻断,返回失败,让调用方重试或框架补偿。
最终希望起到的作用是:
(1)只要存储中没有,那就是肯定没执行;
(2)而如果在存储中查到了记录,框架会认为,曾经有可能执行过,还需要看对应的状态执行对应的补偿。
流程串联
框架需要确定后置处理器和钩子函数的注册时机和方式,需要把主事务的开启,执行节点状态的更新,全部执行完成后的处理逻辑编织在一起,等等。
具体方法:使用拦截器的方式,在事务开启前后、节点执行前后,进行事务信息维护和更新,保证流程和数据相互匹配
服务匹配和调起
执行到每个节点,都需要获取参与者的对应服务实例。这个地方之前还会面试问过,问我异常恢复的时候怎么做到通过分支事务表里记录的字符串,调起对方的rpc服务。
这块的实现其实也有很多种,之前工作中用到的tcc模式的dtx引擎,是依托spring框架,使用XMap技术将配置在xml中的对应服务解析成对应的 Javabean,并匹配本地注册中心的服务端信息,调起对应服务。
DT中,我们用了一种比较简单的方法,那就是「ServiceLoader」,非常有用的一个获取同一接口下所有实现类服务的方法。
只需三步:
创建接口。
com.cjh.test.Hello创建实现类。
com.cjh.test.AHelloImplcom.cjh.test.BHelloImpl指定位置创建接口文件. 在
resource/META-INF/service
文件夹下,创建名为
「com.cjh.test.Hello」
的文件,将com.cjh.test.AHelloImpl
com.cjh.test.BHelloImpl
这两行文本填入
ok 完事~ 所以只要框架指定一个包含了 action 和 compesate 的接口,而业务系统的各个节点都实现了该接口,我们就可以方便的调起这些服务~
//示例代码
ServiceLoader<AAA> serviceLoader=ServiceLoader.load(AAA.class);
for (AAA load : serviceLoader) {
System.out.println(load);
}
LoadInterface loadInterface= EnhancedServiceLoader.load(LoadInterface.class,"BLoad");
loadInterface.execute();
Method method = loadInterface.getClass().getMethod("execute");
method.invoke(loadInterface);
EnhancedServiceLoader.load(LoadInterface.class,"ALoad").execute();
钩子函数
框架支持业务系统在流程执行开始前、完成后、成功后、异常后执行对应的自定义处理,以满足业务系统的特殊需求。
异步补偿
采用分布式调用方法,定时触发未处理数据的捞取操作,并用数据总线的方式,让系统快速执行补偿。为了防止某条数据被多台机器同时捞取,会加分布式锁进行拒绝拦截。
结束语
那么,DT是如何解决开篇提到的那些问题的呢:
在调用扣费服务时发生本服务宕机,说明主事务一定是插入成功的,异步补偿会捞取该主事务记录,并捞取对应的分支事务记录,执行异步补偿。
调用下游超时,说明分支事务已经插入成功,我们更新分支事务为状态未知,等待补偿。
用异步补偿的方式,处理一分钟之前的未完成数据,尽可能避免网络阻塞带来的影响拒绝空回滚,扣费请求后置的幂等处理,需要下游保障
支付系统大面积超时,我们会根据分支事务记录来判断其他节点是否已经执行成功,如果执行成功,则跳过重试操作,以避免不必要的系统调用,防止因为冗余的重试调用触发某一系统瓶颈导致全链路崩溃。
时间衰减等 略。。。
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击????卡片,关注后回复【面试题】即可获取
在看点这里![]() 好文分享给更多人↓↓
好文分享给更多人↓↓
以上是关于分布式事务从入门到放弃--详述DT引擎一致性原理及设计的主要内容,如果未能解决你的问题,请参考以下文章
深入浅出Seata原理及实战「入门基础专题」带你透析认识Seata分布式事务服务的原理和流程