CUDA开发详解篇一
Posted badman250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CUDA开发详解篇一相关的知识,希望对你有一定的参考价值。
CUDA开发详解
- 环境搭建
在部署过程中,需要要先安装Visual Studio,我这里是安装的是 Visual Studio 2017。
然后安装Nvidia CUDA,CUDA版本这里用的是11.3版本。CUDA回去修改VS的一些配置,可直接创建项目或打开sample程序进行运行。
还有开源的一些样例,可以下载下来直接用VS打开。
https://github.com/NVIDIA/cuda-samples
全同态算法库:
https://github.com/vernamlab/cuFHE
- CUDA
2006年,NVIDIA公司发布了CUDA,CUDA是建立在NVIDIA的CPUs上的一个通用并行计算平台和编程模型,基于CUDA编程可以利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题。
CUDA(Compute Unified Device Architecture)是 NVIDIA公司开发的一种计算架构,可以利用NVIDIA系列显卡对一些复杂的计算进行并行加速。
显卡可以加速最大的原因是其含有上千个CUDA核心,而CPU的核心往往都在各位或十位数,这就决定了显卡可以高度并行的对一些高维度矩阵进行计算。
- 创建项目
| #include <iostream> __global__ void mkernel(void) {} int main() { mkernel << <1, 1 >> > (); std::cout << "Hello, World!" << std::endl; system("pause"); return 0; } |
_global_ 为CUDA C为标准C增加的修饰符,表示该函数将会交给编译设备代码的编译器(NVCC)并最终在设备上运行。 而 main函数则依旧交给系统编译器(VS2013)。
CUDA通过直接提供API接口或者在语言层面集成一些新的东西来实现在主机代码中调用设备代码。
-
- 矢量相加
主机端准备数据 -> 数据复制到GPU内存中 -> GPU执行核函数 -> 数据由GPU取回到主机。
| #include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h>
// 接口函数: 主机代码调用GPU设备实现矢量加法 c = a + b cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size); // 核函数:每个线程负责一个分量的加法 __global__ void addKernel(int *c, const int *a, const int *b) { int i = threadIdx.x; // 获取线程ID c[i] = a[i] + b[i]; }
int main() { const int arraySize = 5; const int a[arraySize] = { 1, 2, 3, 4, 5 }; const int b[arraySize] = { 10, 20, 30, 40, 50 }; int c[arraySize] = { 0 };
// 并行矢量相加 cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize); if (cudaStatus != cudaSuccess) { fprintf(stderr, "addWithCuda failed!"); return 1; } printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\\n", c[0], c[1], c[2], c[3], c[4]);
// CUDA设备重置,以便其它性能检测和跟踪工具的运行,如Nsight and Visual Profiler to show complete traces.traces. cudaStatus = cudaDeviceReset(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaDeviceReset failed!"); return 1; } return 0; }
// 接口函数实现: 主机代码调用GPU设备实现矢量加法 c = a + b cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size) { int *dev_a = 0; int *dev_b = 0; int *dev_c = 0; cudaError_t cudaStatus;
// 选择程序运行在哪块GPU上,(多GPU机器可以选择) cudaStatus = cudaSetDevice(0); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); goto Error; } // 依次为 c = a + b三个矢量在GPU上开辟内存 . cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int)); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMalloc failed!"); goto Error; } cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int)); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMalloc failed!"); goto Error; } cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int)); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMalloc failed!"); goto Error; } // 将矢量a和b依次copy进入GPU内存中 cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMemcpy failed!"); goto Error; } cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMemcpy failed!"); goto Error; } // 运行核函数,运行设置为1个block,每个block中size个线程 addKernel<<<1, size>>>(dev_c, dev_a, dev_b); // 检查是否出现了错误 cudaStatus = cudaGetLastError(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "addKernel launch failed: %s\\n", cudaGetErrorString(cudaStatus)); goto Error; } // 停止CPU端线程的执行,直到GPU完成之前CUDA的任务,包括kernel函数、数据拷贝等 cudaStatus = cudaDeviceSynchronize(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\\n", cudaStatus); goto Error; } // 将计算结果从GPU复制到主机内存 cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMemcpy failed!"); goto Error; } Error: cudaFree(dev_c); cudaFree(dev_a); cudaFree(dev_b); return cudaStatus; } |
-
- 开发概念
- 核函数
- 开发概念
kernel<<<1,1>>>(param1,param2,...)
“<<< >>>”中参数的作用是告诉我们该如何启动核函数(比如如何设置线程)。
在主机端(Host)调用时采用如下的形式:
kernel<<<Dg,Db, Ns, S>>>(param list);
Dg:int型或者dim3类型(x,y,z)。用于定义一个grid中的block是如何组织的。 int型则直接表示为1维组织结构。
Db:int型或者dim3类型(x,y,z)。用于定义一个block中的thread是如何组织的。 int型则直接表示为1维组织结构。
Ns:size_t类型,可缺省,默认为0。用于设置每个block除了静态分配的共享内存外,最多能动态分配的共享内存大小,单位为byte。 0表示不需要动态分配。
S:cudaStream_t类型,可缺省,默认为0。 表示该核函数位于哪个流。
-
-
- CUDA概念
-
关于CUDA的线程结构,有着三个重要的概念: Grid, Block, Thread。
GPU工作时的最小单位是 thread。
多个 thread 可以组成一个 block,但每一个 block 所能包含的thread数目是有限的。因为一个block的所有线程最好应当位于同一个处理器核心上,同时共享同一块内存。 于是一个 block中的所有thread可以快速进行同步的动作而不用担心数据通信壁垒。
执行相同程序的多个 block,可以组成 grid。 不同 block 中的 thread 无法存取同一块共享的内存,无法直接互通或进行同步。因此,不同 block 中的 thread 能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的 thread 数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个 block 中的 thread 顺序执行,而非同时执行。不同的 grid 则可以执行不同的程序(即 kernel)。
下图是一个结构关系图:
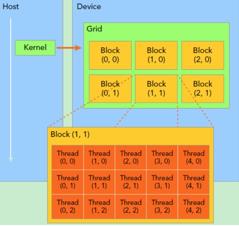
每个thread都有自己的一份register和local memory 的空间。同一个 block 中的每个 thread 则有共享的一份 share memory。同一个grid下所有的 thread(包括不同 block 的 thread)都共享一份 global memory、constant memory、和 texture memory。不同的 grid 则有各自的 global memory、constant memory 和 texture memory。
这种特殊的内存结构直接影响线程分配策略,需要通盘考虑资源限制及利用率。
异构编程就是:
主机上执行串行代码,设备上则执行并行代码。
CUDA并行程序设计,基本上都是在一批数据上利用大量线程实现并行。 除此之外, NVIDIA系列GPU还支持另外一种类型的并行性,即流。GPU中流并行类似于CPU上的任务并行,即每个流都可以看作是一个独立的任务,每个流中的代码操作顺序执行。
-
-
- GPU规格查询
-
| #include "cuda_runtime.h" #include <iostream>
int main() { cudaError_t cudaStatus; // 初获取设备数量 int num = 0; cudaStatus = cudaGetDeviceCount(&num); std::cout << "Number of GPU: " << num << std::endl; // 获取GPU设备属性 cudaDeviceProp prop; if (num > 0) { cudaGetDeviceProperties(&prop, 0); // 打印设备名称 std::cout << "Device: " << prop.name << std::endl; } system("pause"); return 0; } |
-
-
- 限定符
- 函数类型限定符
- 限定符
-
__global__
__global__修饰的函数为 核函数。
运行在设备上;
可以由主机调用;
必须有void返回类型;
调用时必须制定运行参数(<<< >>>)
该函数的调用时异步的,即可以不必等候该函数全部完成,便可以在CPU上继续工作;
__device__
运行在设备上;
只能由设备调用;
编译器会内联所有认为合适的__device__修饰的函数;
__host__
运行在主机上;
只能由主机调用;
效果等同于函数不加任何限定符;
不能与__global__共同使用, 但可以和__device__联合使用;
__noinline__
声明不允许内联。
__forceinline__
强制编译器内联该函数。
-
-
-
- 变量类型限定符
-
-
变量类型限定符用来标识变量在设备上的内存位置。
__device__ (单独使用时)
位于 global memory space;
生命周期为整个应用期间(即与application同生死);
可以被grid内的所有threads读取;
可以在主机中由以下函数读取;
cudaGetSymbolAddress()
cudaGetSymbolSize()
cudaMemcpyToSymbol()
cudaMemcpyFromSymbol()
__constant__
可以和 __device__ 联合使用;
位于 constant memory space;
生命周期为整个应用期间;
可以被grid内的所有threads读取;
可以在主机中由以下函数读取;
cudaGetSymbolAddress()
cudaGetSymbolSize()
cudaMemcpyToSymbol()
cudaMemcpyFromSymbol()
__shared__
可以和 __device__ 联合使用;
位于一个Block的shared memory space;
生命周期为整个Block;
只能被同一block内的threads读写。
__managed__
可以和 __device__ 联合使用;
可以被主机和设备引用,主机或者设备函数可以获取其地址或者读写其值;
生命周期为整个应用期间;
__restrict__
该关键字用来对指针进行限制性说明,目的是为了减少指针别名带来的问题。
-
-
- 内存
-
GPU通常包含大量的数学计算单元,性能瓶颈往往不在于芯片的数学计算吞吐量,而在于芯片的内存带宽,即有时候输入数据的速率甚至不能维持满负荷的运算,需要一些手段来减少内存通信量。在某些场景下,使用常量内存来替换全局内存可以有效地提高通信效率。
同常量内存一样,纹理内存(Texture Memory)也是一种只读内存。 之所以称之为 “纹理”,是因为最初是为图形应用设计的。 当程序中存在大量局部空间操作时,纹理内存可以提高性能。
纹理内存是缓存在片上的,因此一些情况下相比从芯片外的DRAM上获取数据,纹理内存可以通过减少内存请求来提高带宽。纹理内存是针对图形应用设计的,可以更高效地处理局部空间的内存访问。
-
-
- 原子操作
-
原子操作是一种最小单位的执行过程。 在其执行过程中,不允许其他并行线程对该变量进行读取和写入的操作。 如果发生竞争,则其他线程必须等待。
包括:
atomicAdd()/atomicSub()/atomicExch()/atomicMin()/atomicMax()/atomicInc()/atomicDec()/atomicCAS()/atomicAnd()/atomicOr()/atomicXor()。
-
- 线程协作
| #include <iostream> #include "cuda_runtime.h" //定义矢量长度 const int N = 64 * 256; // 定义每个Block中包含的Thread数量 const int threadsPerBlock = 256; // 定义每个Grid中包含的Block数量, 这里32 < 64, 是为了模拟线程数量不足的情况 const int blocksPerGrid = 32; // 核函数:矢量点积 __global__ void dot(float* a, float* b, float* c) { // 声明共享内存用于存储临时乘积结果,内存大小为1个Block中的线程数量 // 每个Block都相当于有一份程序副本,因此相当于每个Block都有这样的一份共享内存 __shared__ float cache[threadsPerBlock]; // 线程索引 int tid = blockIdx.x * blockDim.x + threadIdx.x; // 一个Block中的线程索引 int cacheIndex = threadIdx.x; // 计算分量乘积,同时处理线程不足的问题 float temp = 0.0f; while (tid < N) { temp += a[tid] * b[tid]; tid += gridDim.x * blockDim.x; } // 存储临时乘积结果 cache[cacheIndex] = temp; // 对线程块中的所有线程进行同步 // 线程块中的所有线程都执行完前面的代码后才会继续往后执行 __syncthreads();
// 合并算法要求长度为2的指数倍 int i = threadsPerBlock / 2; while (i != 0) { if (cacheIndex < i) cache[cacheIndex] += cache[cacheIndex + i]; __syncthreads(); i /= 2; }
if (cacheIndex == 0) c[blockIdx.x] = cache[0]; } int main() { // 在主机端创建数组 float a[N]; float b[N]; float c[threadsPerBlock]; for (size_t i = 0; i < N; i++) { a[i] = 1.f; b[i] = 1.f; } // 申请GPU内存 float* dev_a = nullptr; float* dev_b = nullptr; float* dev_c = nullptr; cudaMalloc((void**)&dev_a, N * sizeof(float)); cudaMalloc((void**)&dev_b, N * sizeof(float)); cudaMalloc((void**)&dev_c, blocksPerGrid * sizeof(float)); //将数据从主机copy进GPU cudaMemcpy(dev_a, a, N * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(dev_b, b, N * sizeof(float), cudaMemcpyHostToDevice); //进行点积计算 dot << <32, 256 >> > (dev_a, dev_b, dev_c);
//将计算结果copy回主机 cudaMemcpy(c, dev_c, blocksPerGrid * sizeof(float), cudaMemcpyDeviceToHost); //将每个block的结果进行累加 for (size_t i = 1; i < blocksPerGrid; i++) c[0] += c[i];
// 输出结果 std::cout << "The ground truth is 16384, our answer is " << c[0] << std::endl; //释放内存 cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c); system("pause"); return 0; } |
-
- 流操作示例
| #include <iostream> #include "cuda_runtime.h" using namespace std; #define N (1024*256) // 每次处理的数据量 #define SIZE (N*20) //数据总量 // 核函数,a + b = c __global__ void add(int* a, int* b, int* c) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < N) c[i] = a[i] + b[i]; } int main() { // 获取0号GPU的属性并判断是否支持设备重叠功能 cudaDeviceProp mprop; cudaGetDeviceProperties(&mprop, 0); if (!mprop.deviceOverlap) { cout << "Device not support overlaps, so stream is invalid!" << endl; return 0; } // 创建计时事件 cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); float elapsedTime; // 创建流 cudaStream_t stream0, stream1; cudaStreamCreate(&stream0); cudaStreamCreate(&stream1); // 开辟主机页锁定内存,并随机初始化数据 int *host_a, *host_b, *host_c; cudaHostAlloc((void**)&host_a, SIZE * sizeof(int), cudaHostAllocDefault); cudaHostAlloc((void**)&host_b, SIZE * sizeof(int), cudaHostAllocDefault); cudaHostAlloc((void**)&host_c, SIZE * sizeof(int), cudaHostAllocDefault); for (size_t i = 0; i < SIZE; i++) { host_a[i] = rand(); host_b[i] = rand(); } // 声明并开辟相关变量内存 int *dev_a0, *dev_b0, *dev_c0; //用于流0的数据 int *dev_a1, *dev_b1, *dev_c1; //用于流1的数据 cudaMalloc((void**)&dev_a0, N * sizeof(int)); cudaMalloc((void**)&dev_b0, N * sizeof(int)); cudaMalloc((void**)&dev_c0, N * sizeof(int)); cudaMalloc((void**)&dev_a1, N * sizeof(int)); cudaMalloc((void**)&dev_b1, N * sizeof(int)); cudaMalloc((void**)&dev_c1, N * sizeof(int)); //核心计算部分 cudaEventRecord(start, 0); for (size_t i = 0; i < SIZE; i += 2 * N) { // 复制流0数据a cudaMemcpyAsync(dev_a0, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0); // 复制流1数据a cudaMemcpyAsync(dev_a1, host_a + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1); // 复制流0数据b cudaMemcpyAsync(dev_b0, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0); // 复制流1数据b cudaMemcpyAsync(dev_b1, host_b + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1); // 执行流0核函数 add << <N / 256, 256, 0, stream0 >> > (dev_a0, dev_b0, dev_c0); // 执行流1核函数 add << <N / 256, 256, 0, stream1 >> > (dev_a1, dev_b1, dev_c1); // 复制流0数据c cudaMemcpyAsync(host_c + i * N, dev_c0, N * sizeof(int), cudaMemcpyDeviceToHost, stream0); // 复制流1数据c cudaMemcpyAsync(host_c + i * N + N, dev_c1, N * sizeof(int), cudaMemcpyDeviceToHost, stream1); } // 流同步 cudaStreamSynchronize(stream0); cudaStreamSynchronize(stream1); // 处理计时 cudaEventSynchronize(stop); cudaEventRecord(stop, 0); cudaEventElapsedTime(&elapsedTime, start, stop); cout << "GPU time: " << elapsedTime << "ms" << endl; // 销毁所有开辟的内存 cudaFreeHost(host_a); cudaFreeHost(host_b); cudaFreeHost(host_c); cudaFree(dev_a0); cudaFree(dev_b0); cudaFree(dev_c0); cudaFree(dev_a1); cudaFree(dev_b1); cudaFree(dev_c1); // 销毁流以及计时事件 cudaStreamDestroy(stream0); cudaStreamDestroy(stream1); cudaEventDestroy(start); cudaEventDestroy(stop);
return 0; } |
- 参考链接
Cuda算法
https://github.com/NVIDIA/cuda-samples
全同态算法库:
https://github.com/vernamlab/cuFHE
Tony-Tan代码:
https://github.com/Tony-Tan/CUDA_Freshman
GPU编程(CUDA)博客:
https://face2ai.com/program-blog/#GPU%E7%BC%96%E7%A8%8B%EF%BC%88CUDA%EF%BC%89
以上是关于CUDA开发详解篇一的主要内容,如果未能解决你的问题,请参考以下文章