系统C/C++内存管理之内存模型
Posted 黑黑白白君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统C/C++内存管理之内存模型相关的知识,希望对你有一定的参考价值。
1)内存模型
Linux 中的程序的内存分布:
Linux下32位环境的用户空间内存分布情况:
为什么需要分区?
之所以分成这么多个区域,主要基于以下考虑:
- 一个进程在运行过程中,代码是根据流程依次执行的,只需要访问一次,当然跳转和递归有可能使代码执行多次,而数据一般都需要访问多次,因此单独开辟空间以方便访问和节约空间。
- 临时数据及需要再次使用的代码在运行时放入栈区中,生命周期短。
- 全局数据和静态数据有可能在整个程序执行过程中都需要访问,因此单独存储管理。
- 堆区由用户自由分配,以便管理。

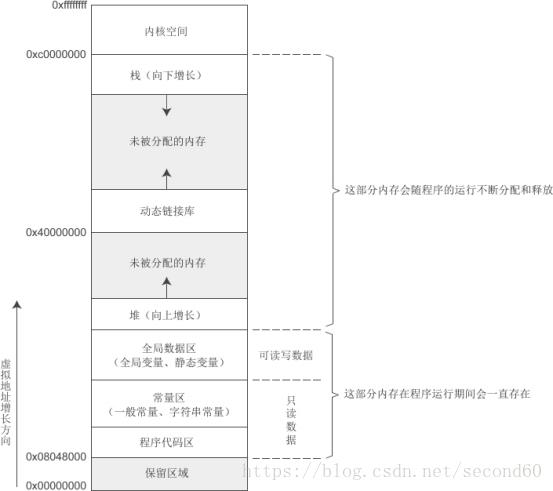
一个由 C/C++编译的程序占用的内存(memory)分为以下几个部分:
1、程序代码区(.text):
.text 部分是编译后程序的主体,也就是程序的机器指令。
程序被操作系统加载到内存的时候,所有的可执行代码(程序代码指令、常量字符串等)都加载到代码区,这块内存在程序运行期间是不变的。
- 代码区是平行的,里面装的就是一堆指令,在程序运行期间是不能改变的。
- 函数也是代码的一部分,故函数都被放在代码区,包括main函数。
2、文字常量区(.rodata):
这是一块比较特殊的存储区,里面存放的是常量,不允许修改。
- 常量字符串就是放在这里的,程序结束后由系统释放。
- rodata:read only data
3、全局区/静态区(static):
全局变量和静态变量被分配到同一块内存中。
- 在以前的C语言中,全局变量又分为初始化的和未初始化的:
- 初始化的全局变量和静态变量在一块区域(.rwdata or .data)。
- 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域(.bss), 程序结束后由系统释放。
- 在 C++中,已经不再严格区分bss和data了,它们共享一块内存区域。
4、堆区(heap):
一般由程序员分配释放(new/malloc/calloc delete/free)。
- 如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
- 注意:它与数据结构中的堆是两回事,但分配方式倒类似于链表。
5、栈区(stack):
在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。
- 由编译器自动分配释放,存放函数的参数值,局部变量的值等。
- 其操作方式类似于数据结构中的栈。
- 栈区在程序运行期间是可以随时修改的。
- 每个线程都有自己专属的栈。
- 栈的最大尺寸固定,超出则引起栈溢出。
- 栈不会很大,一般都是以K为单位。
*C程序执行时的内存分配情况
下面通过一段简单的代码来查看C程序执行时的内存分配情况:
int a = 0; //a在全局已初始化数据区 char *p1; //p1在BSS区(未初始化全局变量) main() { int b; //b在栈区 char s[] = "abc"; //s为数组变量,存储在栈区, //"abc"为字符串常量,存储在已初始化数据区 char *p1,p2; //p1、p2在栈区 char *p3 = "123456"; //123456\\0在已初始化数据区,p3在栈区 static int c =0; //C为全局(静态)数据,存在于已初始化数据区 //另外,静态数据会自动初始化 p1 = (char *)malloc(10); //分配得来的10个字节的区域在堆区 p2 = (char *)malloc(20); //分配得来的20个字节的区域在堆区 free(p1); free(p2); }
2)栈和堆
2.1 栈(stack)
栈存放函数的参数值,返回值,局部变量等,由系统自动分配和释放。
- 存放程序中的局部变量(但不包括static声明的变量,static变量放在数据段中。
- 局部变量表又包含基本数据类型,对象引用类型。
- 局部变量表所需的内存空间在编译期间完成分配。
- 在函数被调用时,栈用来传递参数和返回值。
- 由于栈先进后出特点,所以栈特别方便用来保存/恢复调用现场。
栈是线程私有的,生命周期与线程相同。
- 每个方法在执行的时候都会创建一个栈帧,用来存储局部变量表,操作数栈,动态链接,方法出口等信息。
2.1.1 栈的大小
栈是有一定大小的,通常情况下,栈只有2M,不同系统栈的大小可能不同。
-
在linux中,查看进程/线程栈大小,命令:ulimit -s
he@he-ThinkPad-X200:~$ ulimit -s 8192 //我的系统中栈大小为 8192, 有些系统为 10240, 具体查看自已系统栈大小 -
设置栈大小:
- 临时改变栈大小:ulimit -s 10240
- 开机设置栈大小:在/etc/rc.local中加入 ulimit -s 10240
- 改变栈大小: 在/etc/security/limits.conf中加入:
* soft stack 10240
2.1.2 栈的申请
- 当在函数或块内部声明一个局部变量时,如:
int nTmp;系统会判断申请的空间是否足够,足够,在栈中开辟空间,提供内存;不够空间,报异常提示栈溢出。 - 当调用一个函数时,系统会自动把参数当局部变量,压进栈中,当函数调用结束时,会自动提升堆栈。(可查看汇编中的函数调用机制)。
所以,在声明局部变量时,新手要特别注意栈的大小:
-
对于局部变量,尽量不定义大的变量,如大数组(大于2*1024*1024字节):
char buf[2*1024*1024]; // 可能会导致栈溢出 -
对于内存较大或不知大小的变量,用堆分配,局部变量用指针,注意要释放:
char* pBuf = (char*)malloc(2*1024*1024); // char* 为局部变量 malloc的内存在堆 free(pBuf); -
或定义在全局区中,static变量或常量区中:
static char buf[2*1024*1024];
*栈溢出(StackOverflowError)
栈溢出就是方法执行时创建的栈帧超过了栈的深度。
- 最有可能的就是方法递归调用产生这种结果。
C实现函数递归调用的方法:
- 每当一个函数被调用,该函数返回地址和一些关于调用的信息,比如某些寄存器的内容,被存储到栈区。
- 然后这个被调用的函数再为它的自动变量和临时变量在栈区上分配空间,这就是C实现函数递归调用的方法。
- 每执行一次递归函数调用,一个新的栈框架就会被使用,这样这个新实例栈里的变量就不会和该函数的另一个实例栈里面的变量混淆。
2.2 堆(heap)
为什么需要堆?
在栈中,大小是有限制的,通常大小为2M,如果需要更大的空间,那么就要用到堆了,堆的目的就是为了分配使用更大的空间。
堆用来存放进程运行中被动态分配的内存段。
- 它的大小并不固定,可动态扩张或缩减。
- 当进程调用malloc分配内存时,新分配的内存就被动态添加到堆上。
- 当进程调用free释放内存时,会从堆中剔除。
需要程序员分配和释放,系统不会自动管理,如果用完不释放,将会造成内存泄露。
- 直到进程结束后,系统自动回收。
2.2.1 堆的大小
堆是可以申请大块内存的区域。
- 理论上,使用malloc最大能够申请空间大约为用户空间大小。
- 但这是理论值,因为实际中,还会包含代码区,全局变量区和栈区。
2.2.2 申请和释放
int function()
{
char *pTmp = (char*) malloc(1024); // malloc在堆中分配1024字节空间
//pTmp 为局部变量,只占四字节
free(pTmp); // free为手动释放堆中空间
pTmp = NULL; // 防止pTmp变野指针误用
}
2.2.3 堆的注意事项
堆虽然可以分配较大的空间,但有一些要注意的地方,否则会出现问题。
-
释放问题
分配了堆内存,一定要记得手动释放,否则将会导致内存泄露。
-
碎片问题
如果频繁地调用内存分配和释放,将会使堆内存造成很多内存碎片,从而造成空间浪费和效率低下。
- 对于比较固定,或可预测大小的,可以程序启动时,即分配好空间。
- 如:某个对象不会超过500个,那个可先生成,object ptr = (object)malloc(object_size*500);
- 结构对齐,尽量使结构不浪费内存
- 对于比较固定,或可预测大小的,可以程序启动时,即分配好空间。
-
超堆大小问题
如果申请内存超过堆大小,会出现虚拟内存不足等问题。
- 尽量不要申请很大的内存,如直需要,可采用内存数据库等。
- 尽量不要申请很大的内存,如直需要,可采用内存数据库等。
-
分配是否成功问题
申请内存后,都在判断内存是否分配成功,分配成功后才能使用,否则会出现段错误。
char * pTmp = (char*)malloc(102400); if(pTmp == 0) // 一定在记得判断 { return false; } -
释放后野指针问题
释放指针后,一定要记得把指针的值设置成NULL,防止指针被释放后误用。
-
多次释放问题
如果上述没置NULL,多次释放将会出现问题。
2.3 堆和栈的区别
-
管理方式:
- 对于栈来讲,是由编译器自动管理;
- 对于堆来说,释放工作由程序员控制,容易产生 memory leak。
-
空间大小:
- 一般来讲在 32 位系统下,堆内存可以达到接近 4G 的空间,从这个角度来看堆内存几乎是没有什么限制的。
- 但是对于栈来讲,一般都是有一定的空间大小的,例如,在 VC6 下面,默认的栈空间大小大约是 1M。
-
碎片问题:
- 对于堆来讲,频繁的new/delete 势必会造成内存空间的不连续,从而造成大量碎片,使程序效率降低;
- 对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,永远都不可能有一个内存块从栈中间弹出。
-
生长方向:
- 对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;
- 对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
-
分配方式:
- 堆都是动态分配的,没有静态分配的堆;
- 栈有 2 种分配方式:静态分配和动态分配。
- 静态分配是编译器完成的,比如局部变量的分配,动态分配由 alloca 函数进行分配。
- 但是栈的动态分配和堆是不同的,它的动态分配是由编译器进行释放,不需要我们手工实现。
-
分配效率:
- 栈是机器系统提供的数据结构,计算机会在底层分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高;
- 堆则是 C/C++函数库提供的,它的机制是很复杂的。
- 例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,然后进行返回。
- 显然,堆的效率比栈要低得多。
无论是堆还是栈,都要防止越界现象的发生。
【部分内容参考自】
- C++内存模型:https://blog.csdn.net/qq_22365361/article/details/73928779
- C语言内存模型详解:https://blog.csdn.net/second60/article/details/79946310
- 进程内存布局:https://blog.csdn.net/duyiwuer2009/article/details/7994091
以上是关于系统C/C++内存管理之内存模型的主要内容,如果未能解决你的问题,请参考以下文章