图文详解: 操作系统之内存管理 ( 内存模型,虚拟内存,MMU, TLB,页面置换算法,分段等)...
Posted 东海陈光剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图文详解: 操作系统之内存管理 ( 内存模型,虚拟内存,MMU, TLB,页面置换算法,分段等)...相关的知识,希望对你有一定的参考价值。
关键词: 内存模型,虚拟内存,MMU, TLB,页面置换算法,分段.
计算机模型
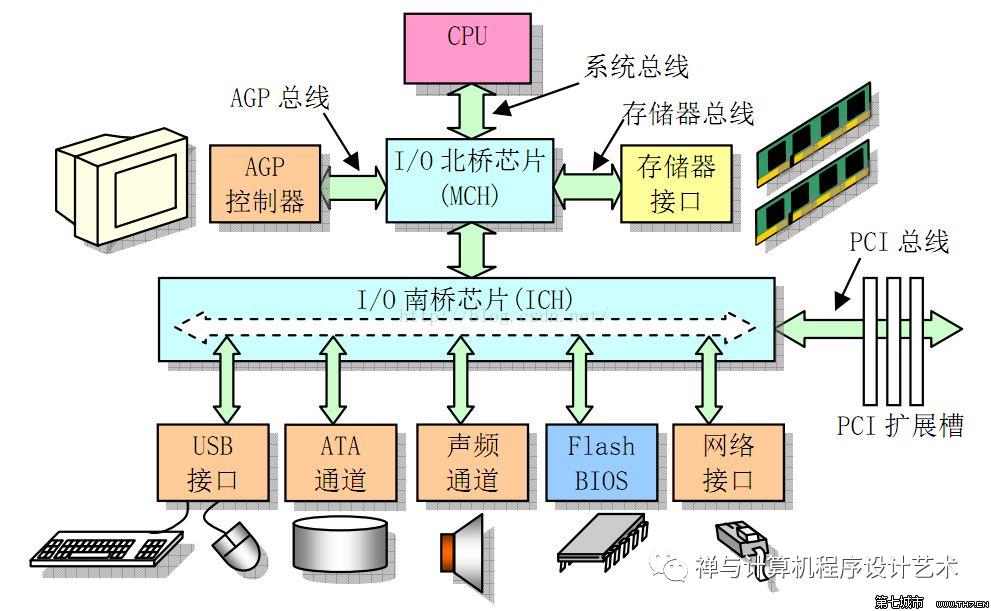

分层存储体系

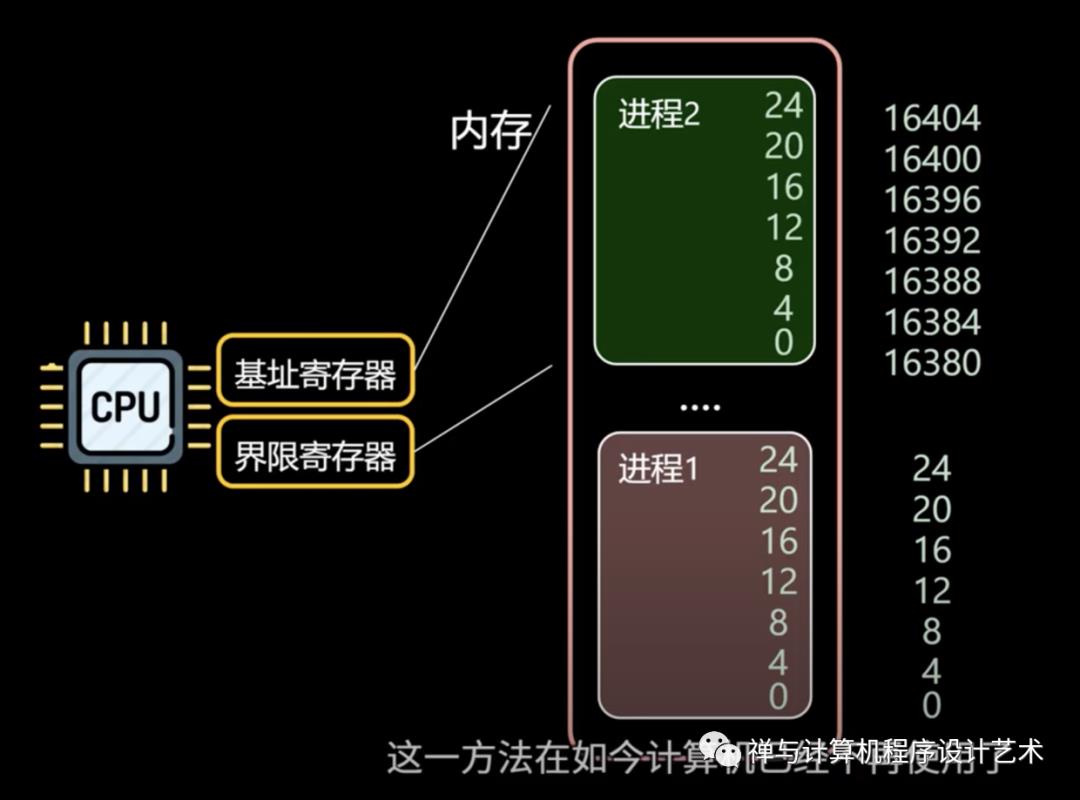
内存抽象
为了更好的管理内存,操作系统将内存抽象成地址空间。
分页管理

每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块称为一页 (Page, 4KB)。
这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。

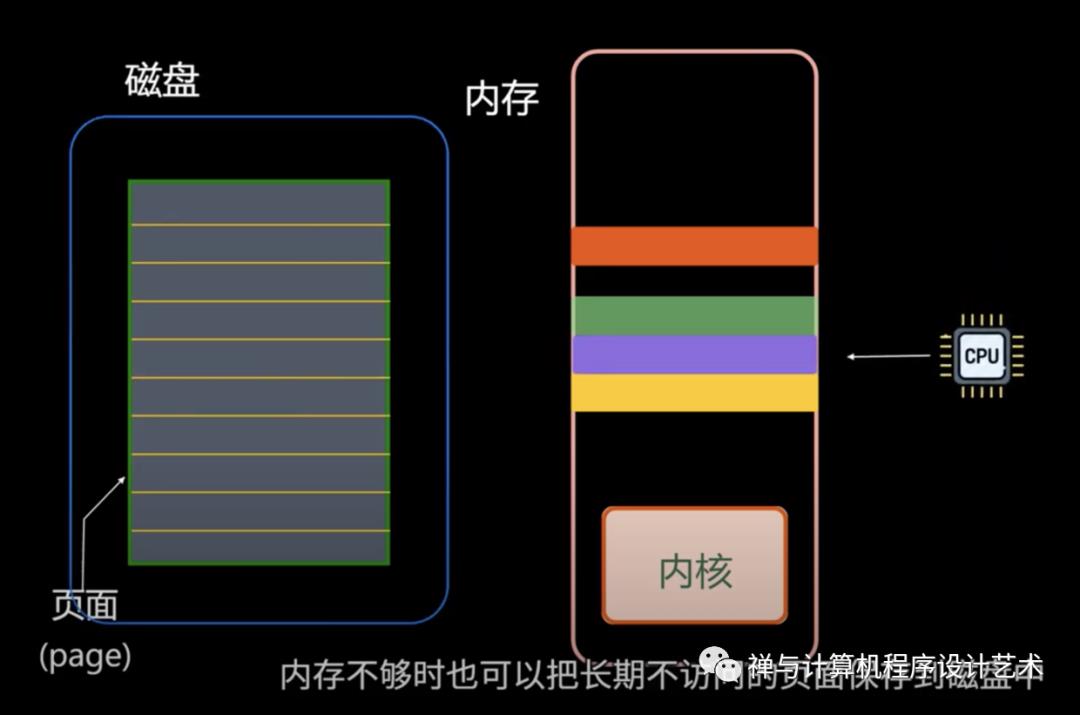
当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
虚拟内存
虚拟内存的目的是为了让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。
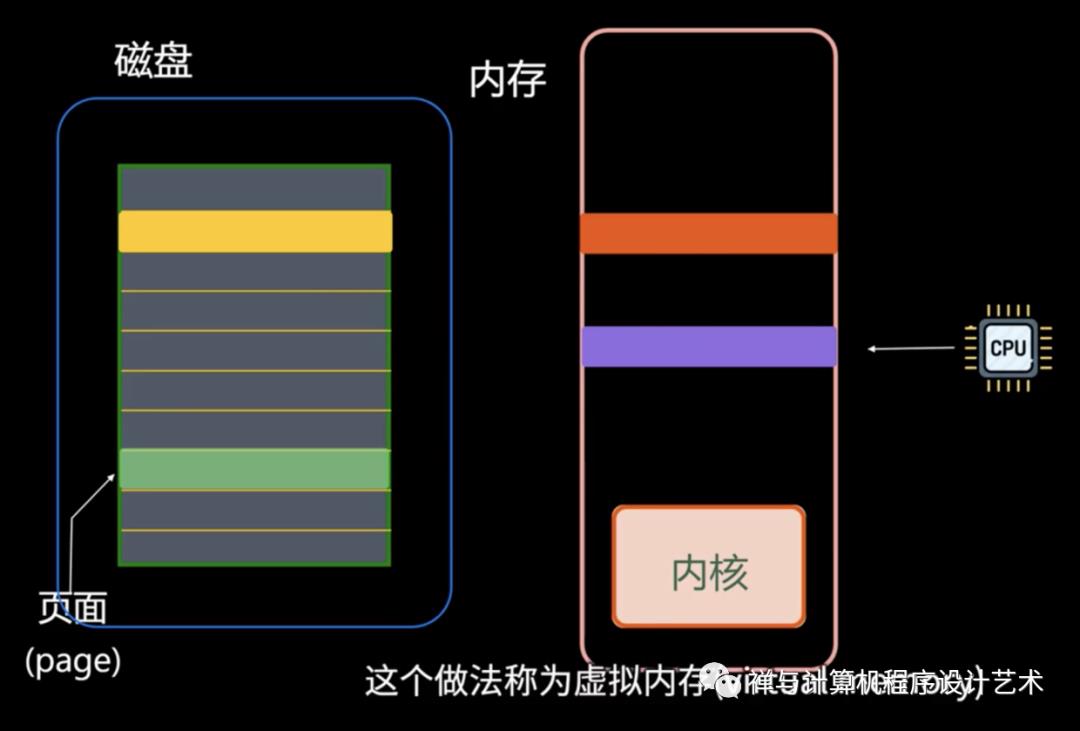
虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。
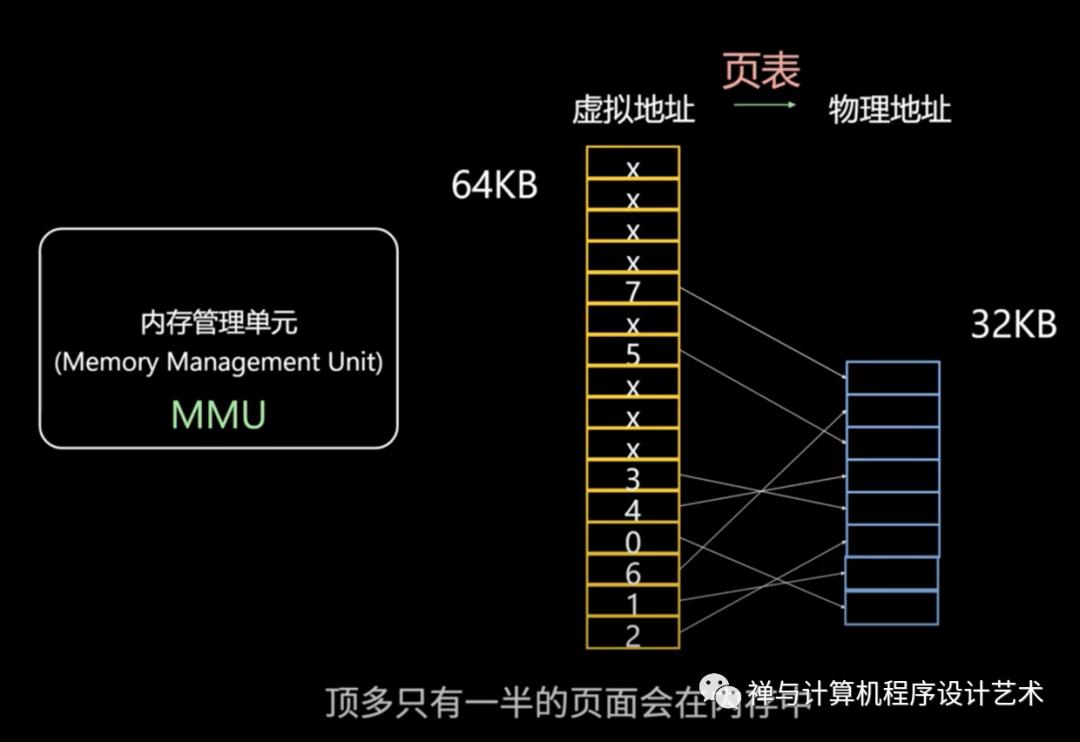
例如有一台计算机可以产生 16 位地址,那么一个程序的地址空间范围是 0~64K。该计算机只有 32KB 的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。

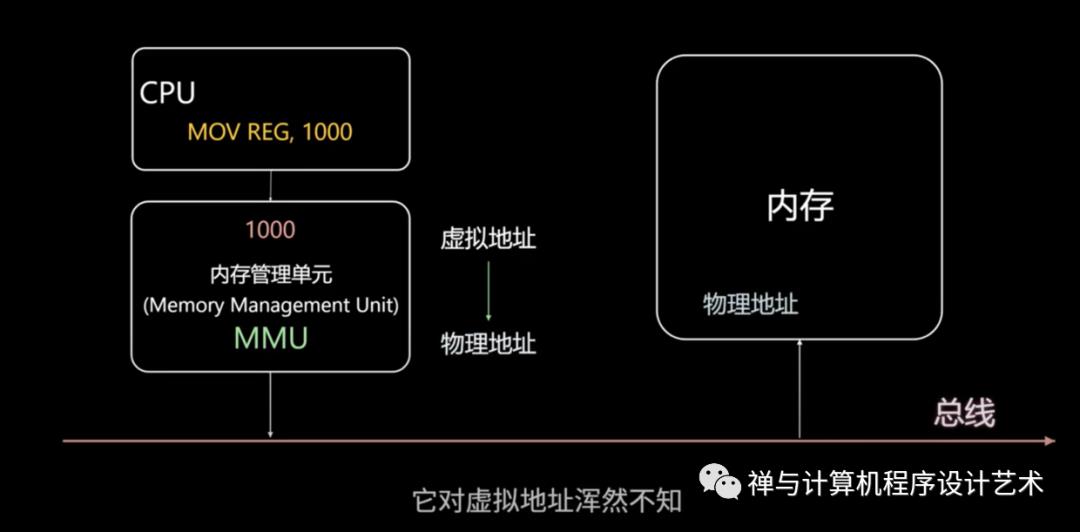
分页系统地址映射: 内存管理单元(MMU)
内存管理单元(MMU)管理着地址空间和物理内存的转换.
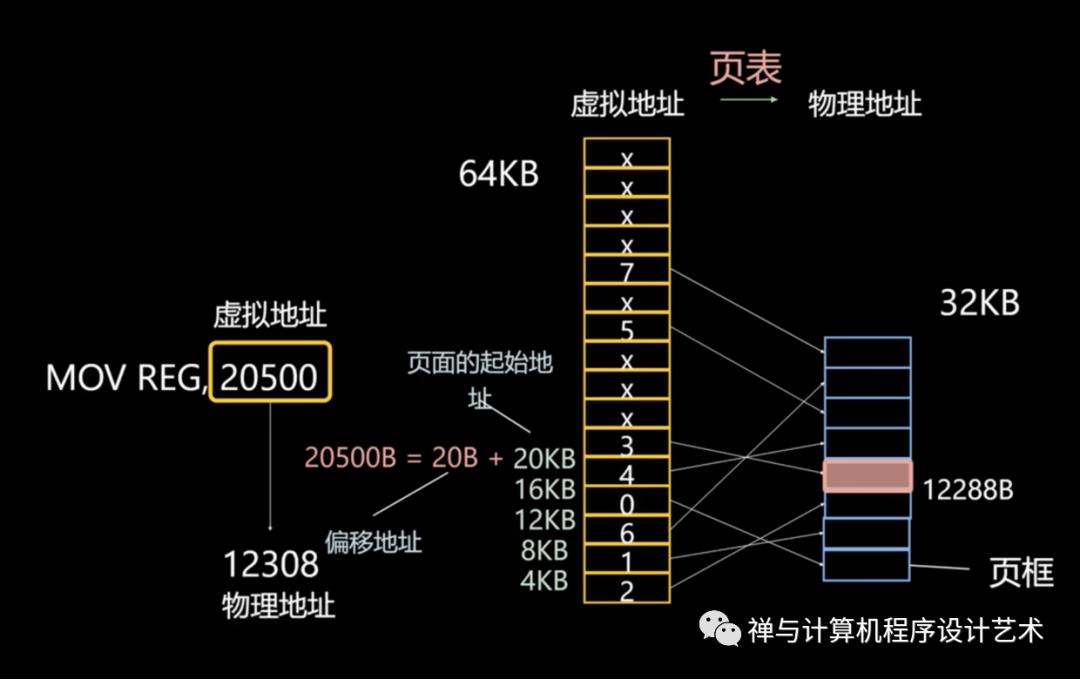
一个虚拟地址分成两个部分,一部分存储页面号,一部分存储偏移量。
下图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。

其中的页表(Page table)存储着页(程序地址空间)和页框(物理内存空间)的映射表。
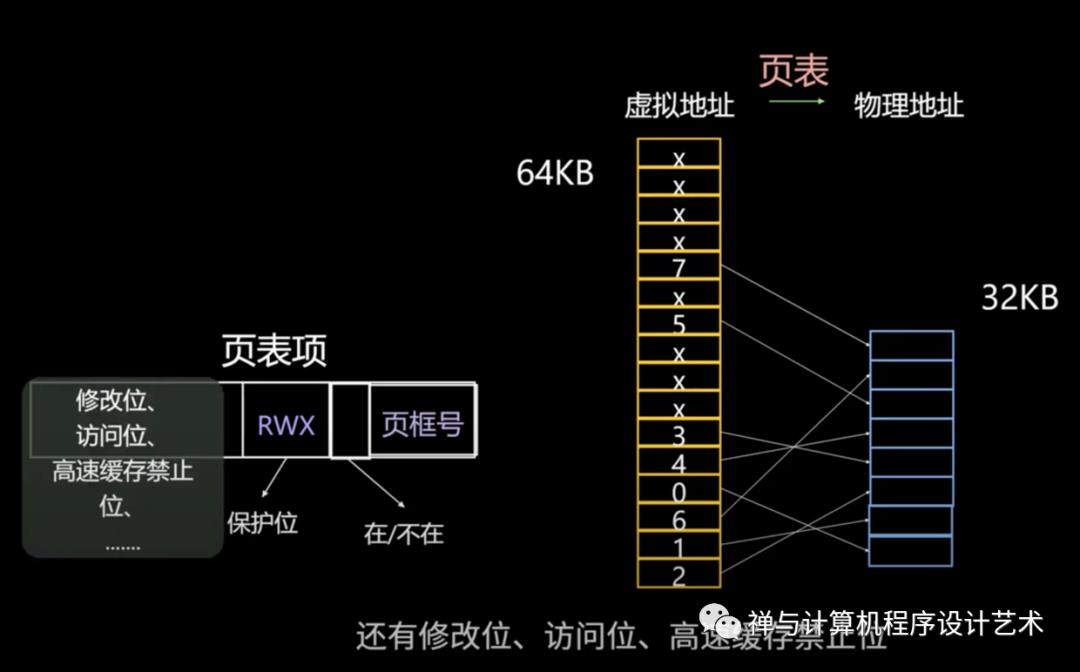
页面置换算法
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法和缓存淘汰策略类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
1. 最佳
OPT, Optimal replacement algorithm
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
举例:一个系统为某进程分配了三个物理块,并有如下页面引用序列:
7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1
开始运行时,先将 7, 0, 1 三个页面装入内存。当进程要访问页面 2 时,产生缺页中断,会将页面 7 换出,因为页面 7 再次被访问的时间最长。
2. 最近最久未使用
LRU, Least Recently Used
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。
为了实现 LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。
因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。
4,7,0,7,1,0,1,2,1,2,6

3. 最近未使用
NRU, Not Recently Used
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
R=0,M=0
R=0,M=1
R=1,M=0
R=1,M=1
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
NRU 优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
4. 先进先出
FIFO, First In First Out
选择换出的页面是最先进入的页面。
该算法会将那些经常被访问的页面换出,导致缺页率升高。
5. 第二次机会算法
FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问题,对该算法做一个简单的修改:
当页面被访问 (读或写) 时设置该页面的 R 位为 1。需要替换的时候,检查最老页面的 R 位。如果 R 位是 0,那么这个页面既老又没有被使用,可以立刻置换掉;如果是 1,就将 R 位清 0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续从链表的头部开始搜索。
6. 时钟
Clock
第二次机会算法需要在链表中移动页面,降低了效率。时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。

分段
虚拟内存采用的是分页技术,也就是将地址空间划分成固定大小的页,每一页再与内存进行映射。
下图为一个编译器在编译过程中建立的多个表,有 4 个表是动态增长的,如果使用分页系统的一维地址空间,动态增长的特点会导致覆盖问题的出现。
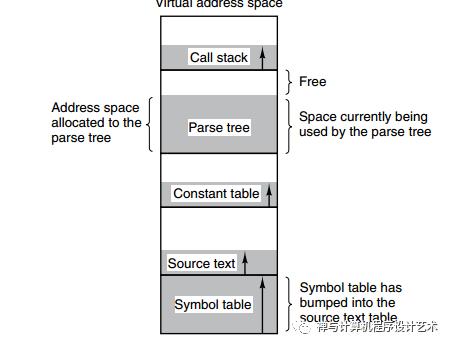
分段的做法是把每个表分成段,一个段构成一个独立的地址空间。每个段的长度可以不同,并且可以动态增长。

段页式
程序的地址空间划分成多个拥有独立地址空间的段,每个段上的地址空间划分成大小相同的页。这样既拥有分段系统的共享和保护,又拥有分页系统的虚拟内存功能。
分页与分段的比较
对程序员的透明性:分页透明,但是分段需要程序员显式划分每个段。
地址空间的维度:分页是一维地址空间,分段是二维的。
大小是否可以改变:页的大小不可变,段的大小可以动态改变。
出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
TLB: 页表缓冲区
TLB , Translation Lookaside Buffer

TLB工作原理
快表,直译为旁路快表缓冲,也可以理解为页表缓冲,地址变换高速缓存。
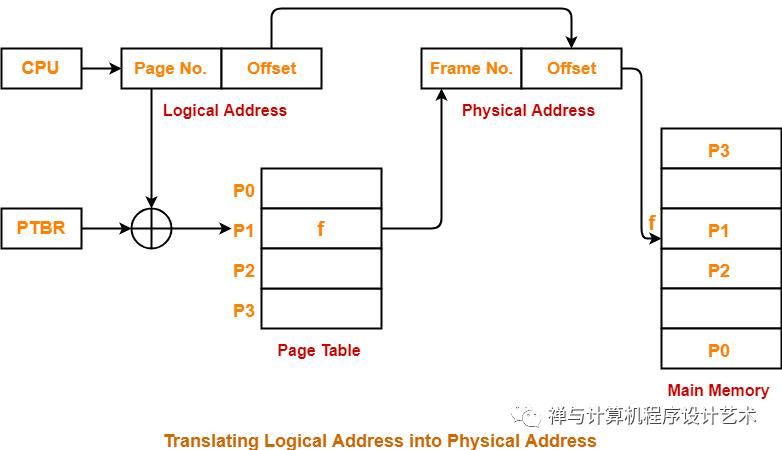
由于页表存放在主存中,因此程序每次访存至少需要两次:一次访存获取物理地址,第二次访存才获得数据。提高访存性能的关键在于依靠页表的访问局部性。当一个转换的虚拟页号被使用时,它可能在不久的将来再次被使用到。

TLB是一种高速缓存,内存管理硬件使用它来改善虚拟地址到物理地址的转换速度。当前所有的个人桌面,笔记本和服务器处理器都使用TLB来进行虚拟地址到物理地址的映射。使用TLB内核可以快速的找到虚拟地址指向物理地址,而不需要请求RAM内存获取虚拟地址到物理地址的映射关系。这与data cache和instruction caches有很大的相似之处。
TLB原理
当cpu要访问一个虚拟地址/线性地址时,CPU会首先根据虚拟地址的高20位(20是x86特定的,不同架构有不同的值)在TLB中查找。如果是表中没有相应的表项,称为TLB miss,需要通过访问慢速RAM中的页表计算出相应的物理地址。同时,物理地址被存放在一个TLB表项中,以后对同一线性地址的访问,直接从TLB表项中获取物理地址即可,称为TLB hit。
想像一下x86_32架构下没有TLB的存在时的情况,对线性地址的访问,首先从PGD中获取PTE(第一次内存访问),在PTE中获取页框地址(第二次内存访问),最后访问物理地址,总共需要3次RAM的访问。如果有TLB存在,并且TLB hit,那么只需要一次RAM访问即可。
TLB表项
TLB内部存放的基本单位是页表条目,对应着RAM中存放的页表条目。页表条目的大小固定不变的,所以TLB容量越大,所能存放的页表条目越多,TLB hit的几率也越大。但是TLB容量毕竟是有限的,因此RAM页表和TLB页表条目无法做到一一对应。因此CPU收到一个线性地址,那么必须快速做两个判断:
1 所需的也表示否已经缓存在TLB内部(TLB miss或者TLB hit)
2 所需的页表在TLB的哪个条目内
为了尽量减少CPU做出这些判断所需的时间,那么就必须在TLB页表条目和内存页表条目之间的对应方式做足功夫
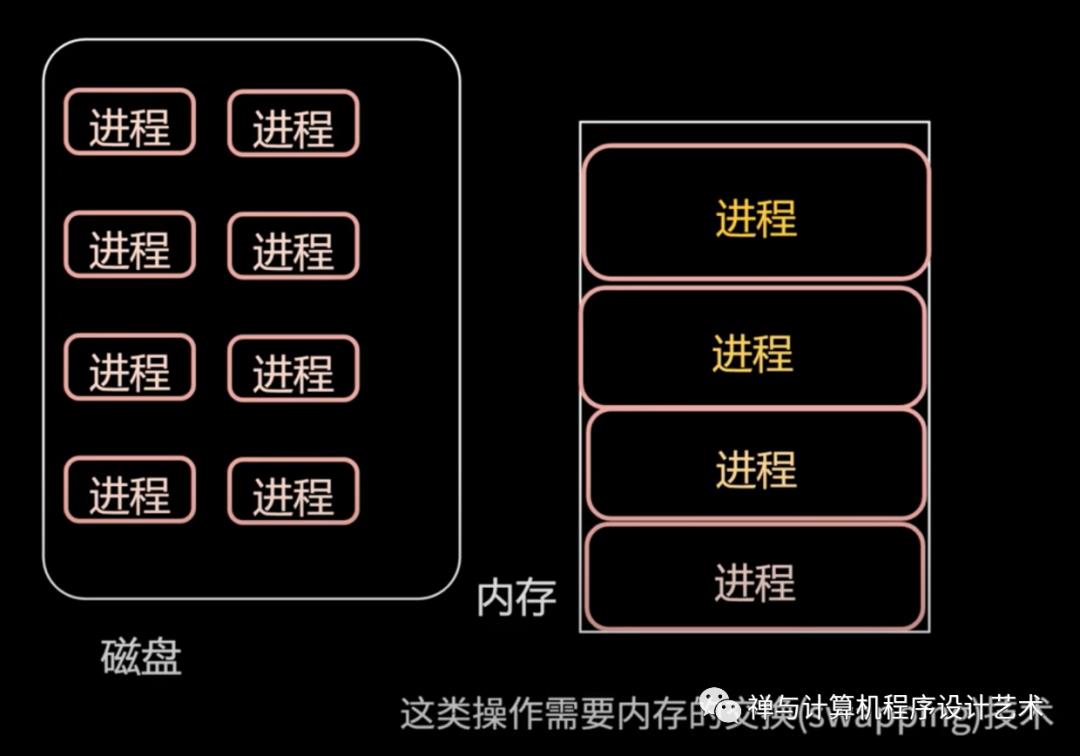
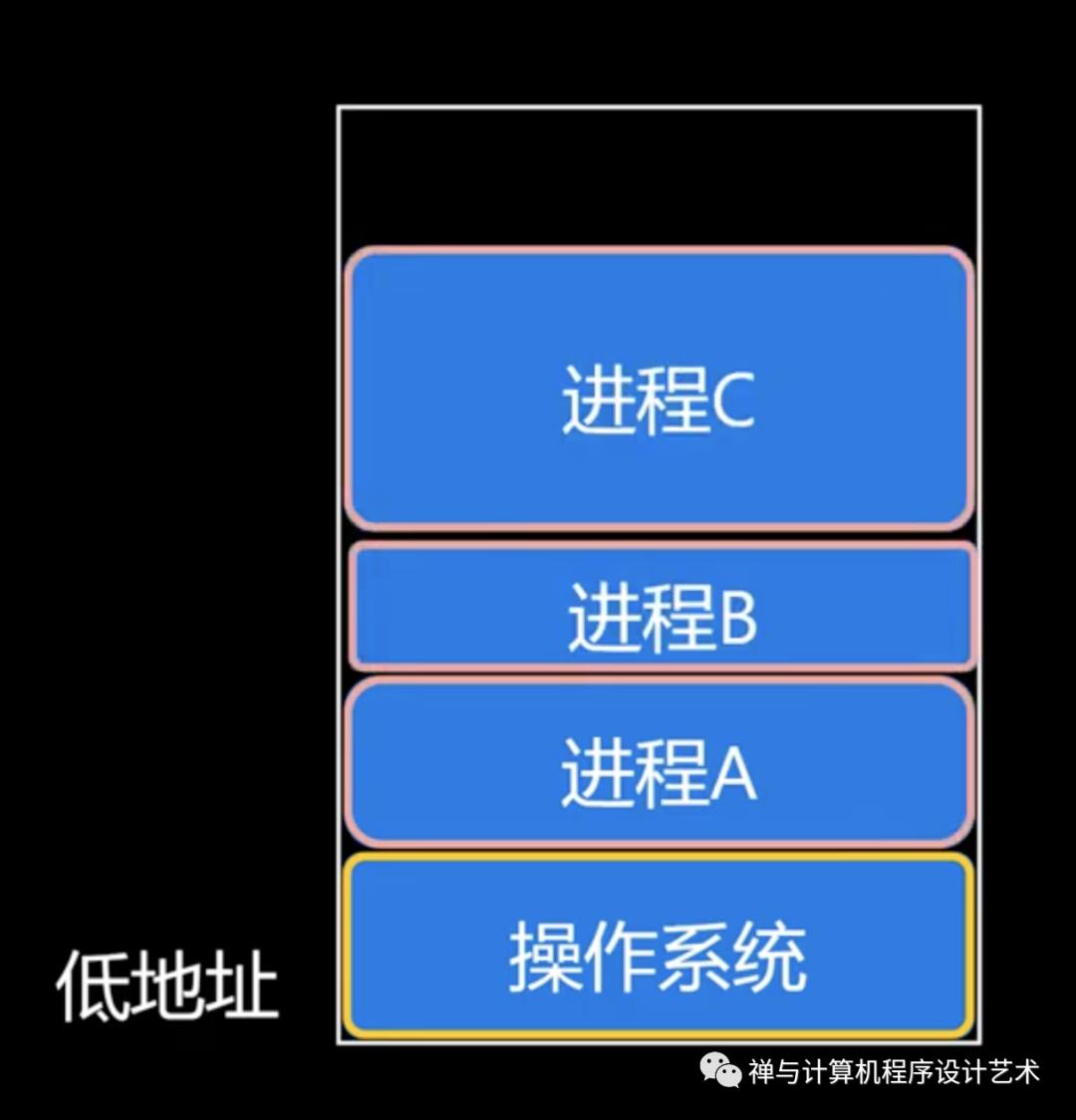
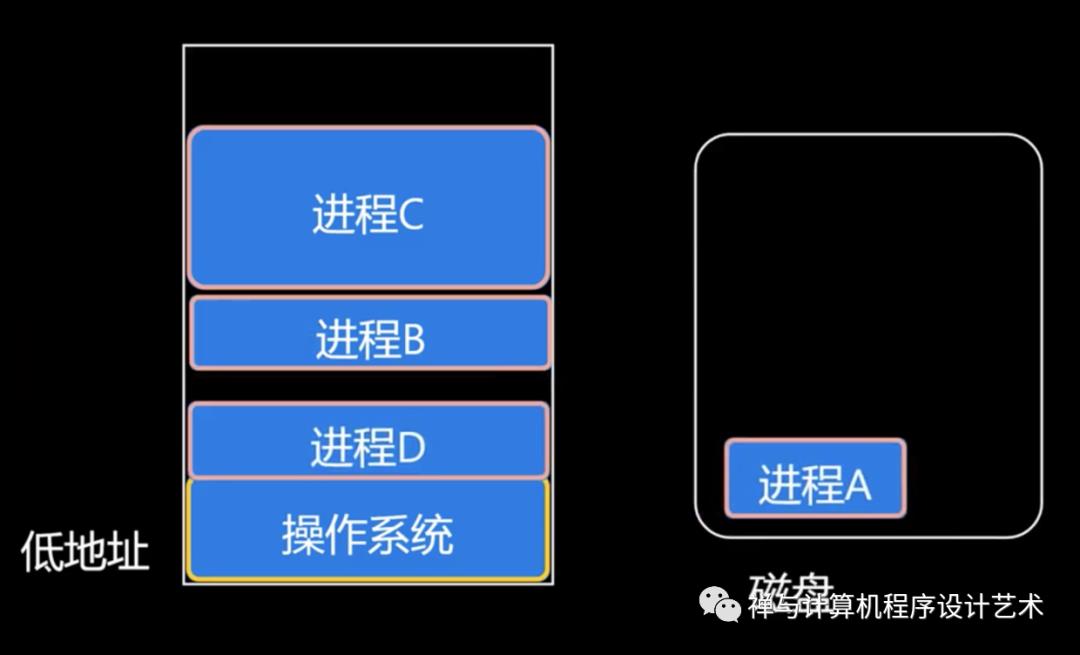
内存交换(Swapping)



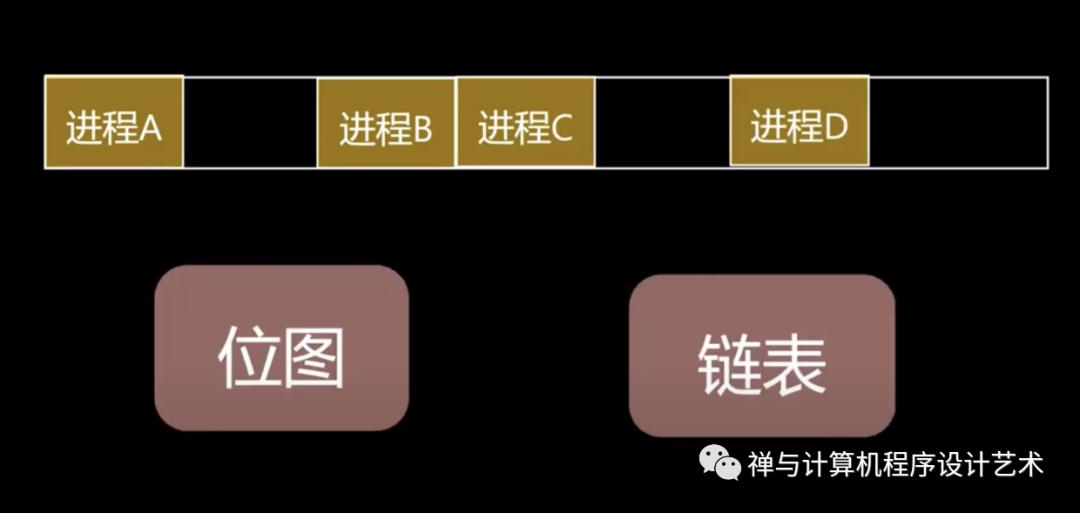
内存管理的数据结构


操作系统对进程进行管理和调度
task_struct
在进程管理中,最为重要的数据结构就是task_struct了。在它里面描述了进程几乎所有的信息,有了它进程才能被操作系统作为一个实体进行操作。task_struct的代码太长,这里就不一一列举了,只选一部分重要的进行讲解,下面的每一行代码在文件里不一定连续。(路径:kernel/include/linux/sched.h)
struct task_struct {
...
struct thread_info thread_info; //第一个成员就是指向内核栈里的thread_info,是有意而为之的
volatile long state; //进程当前的状态
unsigned int flags; //进程标记
int prio; //进程的优先级,在进行进程调度时使用
struct mm_struct *mm; //进程内存管理信息
pid_t pid; //进程标识符,每个拥有唯一的pid
pid_t tgid; //进程组标识,表示进程所属的进程组
struct task_struct __rcu *parent; //进程的父进程
struct list_head children; //子进程
struct list_head sibling; //兄弟进程
struct task_struct *group_leader; //进程组的组长进程
struct pid *thread_pid; //线程标识符
struct list_head thread_group; //线程组标识符
struct fs_struct *fs; //文件系统描述符
struct files_struct *files; //打开文件描述符
...
}
操作系统对进程进行管理和调度,实质是对task_struct进行管理,通过对其中某些成员的修改来达到对进程当前状态的修改。
线程的实现实际上是进程内存空间的共享,而管理内存的结构就是task_struct中的mm_struct。
mm_struct
如下图,mm_struct各成员指向了进程各部分所在的内存区域。
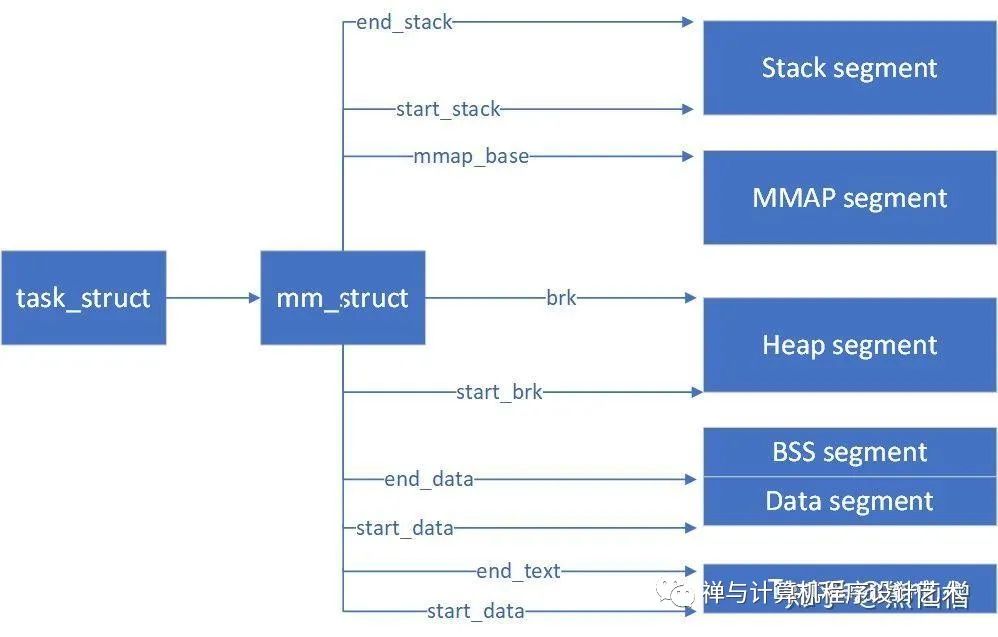
进程内存管理结构
在前面的章节中讨论过,不论进程还是线程,都各自拥有自己的task_struct实例。而线程的实现方式就是共享进程内存空间,即共享mm_struct。在这里就可以将前面关于线程的知识串联起来了,属于同一个线程组的线程各自拥有自己的task_struct实例,但是他们的mm_struct却是同一个实例。
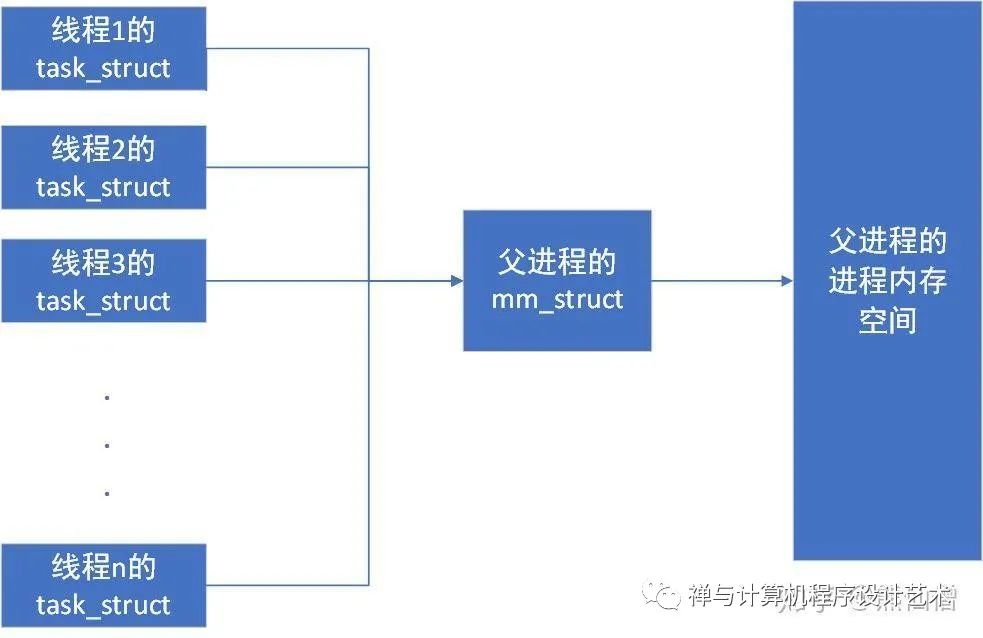
线程之间共享内存
属于同一线程组的线程通过共享 mm_struct 实例的方式实现了内存空间的共享。
一个进程的整个虚拟空间映射到的物理空间不一定是连续的,而是被分为了多个虚拟区间(单个虚拟区间在内存中是连续的,通常为一个内存页面),管理这些虚拟区间的结构体为vm_area_struct。这样我们可以总结一下,一个进程只能有一个mm_struct来描述其整个虚拟空间信息,但可以有多个vm_area_struct来描述其虚拟空间中的一个区间的信息。
下面的两行都是mm_struct中用来管理虚拟区间的成员。当虚拟区间较少时,使用mmap;当虚拟区间较多时,使用mm_rb。
关于红黑树的数据结构不是本章所要关注的重点,故不在此深入展开。(路径:kernel/include/linux/mm_types.h)
struct vm_area_struct*mmap; /* 指向虚拟区间VMA的链表, list of VMAs */
struct rb_rootmm_rb; /* 指向线性区对象红黑树的根 */
参考资料:
[1]https://blog.csdn.net/tiankong_/article/details/75647488
[2]https://blog.csdn.net/qq_26768741/article/details/54375524
[3]https://www.jb51.net/article/123056.htm
[4]https://blog.csdn.net/SweeNeil/article/details/88641053
[5]《Linux内核设计与实现(第三版)》
[6] https://www.youtube.com/watch?v=adHUOoGB67Q
[7] https://github.com/to-be-architect/CS-Notes/blob/master/notes/%E8%AE%A1%E7%AE%97%E6%9C%BA%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F%20-%20%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86.md
以上是关于图文详解: 操作系统之内存管理 ( 内存模型,虚拟内存,MMU, TLB,页面置换算法,分段等)...的主要内容,如果未能解决你的问题,请参考以下文章